最新信息
- Koupleless 2024 年度报告 & 2025 规划展望
- 获奖情况
- 社区会议纪要
- 大会分享与干货文章视频
- 产品发布记录
- 线上应用 10 秒启动、只占 20M 内存不再是想象~SOFAServerless 为你带来极致研发体验
- 成倍降本增效,提升企业竞争力!SOFAServerless 品牌升级为 Koupleless,重磅发布 1.0 版本
- Koupleless 内核系列|模块化隔离与共享带来的收益与挑战
- Koupleless 内核系列 | 单进程多应用如何解决兼容问题
- Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
- Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
- Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
- 恭喜 祁晓波 成为 Koupleless (原 SOFAServerless) 优秀 Contributor!
- 恭喜 颜文 成为 Koupleless 社区优秀 Contributor!
- 蚂蚁中间件团队火热招聘中!
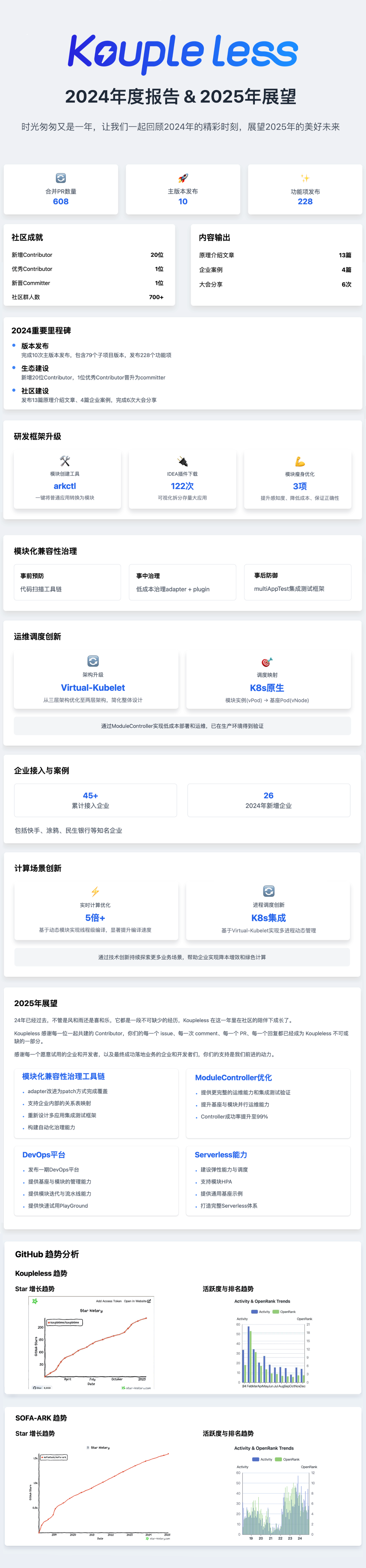
Koupleless 2024 年度报告 & 2025 规划展望
文字版
时光匆匆又是一年,2024年已经结束,是时候对过去一年做个回顾和总结,是对过去一年每一位在 Koupleless 社区一起努力的同学们的一次答复和感谢,也是趁次机会对25年做个规划和展望。
Koupleless 是一个基于模块化技术的企业级解决方案,涉及的组件和功能较多,包括研发框架、运维调度、研发工具、生态治理工具链等,在 2023 年经过半年的建设到24年初基本框架成型发布 1.0.0 版本,但还存在诸多难题:
- 研发阶段的成本仍然较高,特别是在新模块创建、模块瘦身等上
- 广泛的生态组件不支持模块化,体现在多个 springboot 安装在一个 jvm 里、动态卸载等,这里的兼容性适配如何解决?
- Koupleless 的发布运维平台建设成本很高,且不同企业的基础设施不同,也不可能为不同企业提供不同的集成方案,如何让广泛的企业都能低成本的集成 Koupleless 模块化发布运维能力,是关于 Koupleless 项目能否顺利推广的关键问题。
24年除了继续在每个组件每个环节上持续迭代和演进 快、省、灵活部署、平滑演进四大特性,还重点针对上述难题进行攻坚。这一年,Koupleless 各个项目包括 SOFAArk、Runtime、Adapter、Plugin、Virtual-Kubelet、Module-Controller、ArkCtl、Scanner、Koupleless-idea 等组件,共合并 608 个 PR,完成 10 次主版本发布,包含79个子项目版本,发布 228 个功能项,后面会再介绍下其中重要的进展,详细可以查看 github release 列表。在开发者生态上,新增 20 Contributor,其中1位优秀 Contributor,1 位晋升为 committer。发布 13 篇原理介绍文章、4篇企业案例,完成 6 次大会分享,社区群人员数量达到 700+。
主项目:Koupleless


子项目:SOFAArk


@ToviHe,@compasty,@g-stream,@lbj1104026847,@linwaiwai,@liu-657667,@qq290584697,@yuhaiqun19892019,@suntaiming,@pmupkin,@2041951416,@loong-coder,@hadoop835,@xymak,@jyyfei,@laglangyue,@yuandongjian,@98DE9E1F,@leewaiho,@KennanYang,@Jackisome,@liufeng-xiwo,@Simon-Dongnan,@oxsean,@langke93,@XiWangWy,@Juzi-jiang,@ligure,@chenjian6824
项目功能演进
研发框架
首先在模块的研发上,为了降低模块的创建和接入成本,Koupleless 提供了
- 基于研发工具 arkctl 的普通应用一键转换成模块
- 开放了模块拆分插件 Koupleless-idea,目前已有 122 次下载,帮助用户可视化的方式将存量大应用拆分出多个小模块
- 提供模块脚手架快速创建出新模块

在模块研发上线整体流程上,可以看到模块创建的三种方式都已经提供了工具来降低成本。不过当前对改造成基座并没有提供工具,主要考虑这部分主要工作是引入 Koupleless sdk 的 starter,可以参考官网实现即可。
模块接入和研发过程中,还有个关键的也是必须的步骤“模块瘦身”需要完成,这个过程需要同步分析基座和模块的代码,由于这两部分信息比较分散,所以常常发生该瘦身的没有瘦身、不该瘦身的瘦身然后导致模块启动失败等问题。今年对模块瘦身做了三大重大升级:
- 提升基座与模块信息的感知度
- 低成本的模块瘦身
- 确保瘦身的正确性
将模块瘦身的操作从原来的黑盒状态转变成白盒状态,可以大幅降低这部分的改造和研发成本。另外在模块打包构建上提供了 gradle 版本的打包插件可以让 gradle 工程也能使用 Koupleless 的所有能力,模块隔离上新增了环境变量隔离能力。
模块化兼容性治理
Koupleless 模块化是在单个 jvm 内同时运行多个 springboot,并提供动态热更新的能力,势必存在一些生态组件不完全适配问题。主要体现在三个方面:
- 共享变量的互相覆盖
- 多 ClassLoader 切换导致的不一致
- 部分资源未清理干净
对于这些问题,也发表了多篇系列文章来详细阐述
进阶系列一:[Koupleless 模块化的优势与挑战,我们是如何应对挑战的]
进阶系列二: [Koupleless 内核系列 | 单进程多应用如何解决兼容问题]
进阶系列三:[Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?]
进阶系列四:[Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么]
进阶系列五:[Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?]
同时今年也在社区将完整的生态治理工具链开放出来,包括事前的代码扫描 -> 事中的低成本治理 adapter + plugin -> 事后的防御集成测试框架 multiAppTest,每个组件的使用都可以在官网文档里查看到。

当前已完成所发现的 50 多个常用组件的兼容性治理或提供最佳实践。
运维调度
在发布与运维调度上,由于 Koupleless 是在原有的基座进程里动态安装卸载多个模块,这套模式与企业的现有基础设施有较大不同,需要在原来的基础设施上新建一层模块化的控制面,有较大的建设成本和与周边设施打通的成本,如下图:

需要建设设配的周边平台不限于
- 应用元数据管理平台:新增模块应用元数据
- 研发与迭代管理平台:增加模块创建、模块迭代、模块构建、发起模块发布
- 联调平台:增加模块与基座、模块与普通应用联调
- 可观测平台:监控与告警、trace 追踪、日志采集与查询
- 灰度平台
- 模块流量
今年我们根据内部实战经验,考虑生态适配的成本问题,将模块安装调度到基座上的行为抽象为等同于 pod 安装调度到 node 上的行为,巧妙的利用 Virtual-Kubelet 将模块实例映射为 vPod,将基座 Pod 映射为 vNode.

通过基于 Virtual-Kubelet 的 ModuleController 方案,将原来的三层架构打平到与传统一致的两层架构,可以大量复用为普通应用建设的基础设施能力,包括直接使用基座 PaaS 平台来发布模块,达到可低成本扩展出模块化发布、运维、调度能力的目的,这套方案也在内部实际业务落地过程得到验证。

还有更多能力就不再一一罗列,详细查看 github release 列表。
企业接入与案例
当前可以统计的累计有 45 家企业已经完成接入上线,其中24年新增 26 家企业,包括快手、涂鸦、民生银行等,沉淀4篇案例,当然还有更多不在可统计范围里的哈。
高效降本|深度案例解读 Koupleless 在南京爱福路的落地实践
Koupleless 助力蚂蚁搜推平台 Serverless 化演进
涂鸦智能落地 Koupleless 合并部署,实现云服务降本增效
Koupleless 助力「人力家」实现分布式研发集中式部署,又快又省!
这些企业在多个业务场景里落地 Koupleless,包括“中台代码片段研发提效”、“企业内合并部署省资源”、“私有云、边缘云交付”、“长尾应用治理”等,同时也完成了一些新业务的探索落地。
新业务场景探索落地
实时计算
在蚂蚁内部的 flink 计算引擎,原来采用业内常用的启动进程的方式编译用户提交上来的作业代码,每次占用资源且耗时较高。使用 Koupleless 中提供的动态模块与动态 plugin 能力,将每一次编译请求从进程模型调整线程模型,每一次请求实际变成安装一次模块,然后触发线程内的编译,编译完成后立即卸载模块。将编译速度提升5倍以上,解决了原来的三大痛点: 资源消耗大、相应速度慢、处理请求有限,当前一篇专利正在申请中。

进程调度
有个业务场景,需要在一个 POD 内动态开启或关闭多个子进程,并同步状态到控制平台。这个过程相当于在一个 Pod 的基座进程里安装了多个进程模块,与 Koupleless 模块化实际上非常类似,区别只是进程内模块化还是进程间模块化的区别,在运维调度上本质是相通的,需要考虑的问题如下
- 资源的分配与调度
- 玩法进程的启动
- 玩法进程关闭
- 玩法进程的状态查询与同步等

我们基于 Virtual-Kubelet 的 ModuleController 方法,同样把基座进程映射成 vNode,把动态启停的子进程映射成 vPod,然后由 K8S 控制组件完成实例管理、调度、运维等,通过实现类似 kubelet 的 agent 管道实现子进程的启动和关闭,通过这种方式帮助业务快速完成运维和调度等三层能力的建设。
除了这些已有的和24年新增的业务场景,相信还有更多的业务场景可以使用 Koupleless,欢迎一起在社区里碰撞出更多可能,帮助更多企业实现降本增效和绿色计算。
25年规划
24年已经过去,不管是风和雨还是喜和乐,它都是一段不可缺少的经历,Koupleless 在这一年里在社区的陪伴下成长了。
Koupleless 感谢每一位一起共建的 Contributor,你们的每一个 issue、每一次 comment、每一个 PR、每一个回复都已经成为 Koupleless 不可或缺的一部分;
也感谢每一个愿意试用的企业和开发者,你们已经踏出了关键的第一步“动手试用”,愿意尝试去发现 Koupleless 的价值,这过程可能不是顺利的,但也能完成评估验证。不管有没有实际落地业务,你们都为 Koupleless 的发展提供了业务基础;
更感谢最终成功落地业务的企业和开发者们,你们不光解决 Koupleless 框架的适配问题,还需解决企业落地的困难(有不少企业因为非技术的原因停在了这一步),用你们对 Koupleless 的耐心和信心,持续努力最终顺利在企业内部落地,这个过程也是用业务持续陪伴和滋养了 Koupleless 的成长。
因为有你们的陪伴,Koupleless 在这一年里成长了,除了进一步打磨底盘完善体验外,对于年初的三大难题也探索出了方向,实现了完整的架构和工具链或组件,但还不能说完全解决了这几个难题。25年有更多的工作需要做,主要集中如下几个方面:
进一步完善模块化兼容性治理工具链
- adapter 虽然可以通过类覆盖的方式完成组件的治理,但因为要拷贝原来完整的类过来,可能覆盖掉某些版本的实现。需要改成 patch 的方式完成覆盖,https://github.com/Koupleless/Koupleless/issues/183
- plugin 当前可以帮助基座自动匹配到对应的 adapter 并引入,但是当前的匹配方式是基于
Koupleless-adapter-config里的映射关系表实现的,如果企业内部自定义的 adapter 是不在这个映射表里的,需要支持企业内部的关系表映射。 - 多应用集成测试框架还需重新设计方案,以便可以利用已有的测试的用例快速建设多应用的集成测试用例。
- 另外当前这些工具是手动模式,无法支持更广泛的组件的扫描与治理,需要考虑自动化的能力去做好生态更广泛的治理工作。
ModuleController 的成功率
当前 ModuleController 已经提供 http 和 mqtt 两种类型的运维管道能力,但目前实现功能还需要在更复杂的运维环境里测试验证。
- ModuleController 提供更完整的运维能力和集成测试验证能力
- 验证并提高基座与模块的同时并行运维的能力
- ModuleController 自身成功率达到99%
DevOps 平台
当前 ModuleController 只是提供了模块化发布、运维与调度能力,不具备 devops 的平台能力,也无法提供基座和模块的管理能力。
- 发布 0.5 版本 DevOps 平台,提供基础的基座与模块管理能力,模块迭代与流水线能力等
- 提供快速试用 PlayGroud
打造 Serverless 能力
- 建设弹性能力与调度,如模块 HPA
- 提供通用基座示例,打造 Serverless 体系
这些能力的建设还需要更多社区同学一起努力,欢迎有志之士一起加入 Koupleless 社区,一起打造模块化研发体系,帮助更多企业实现降本增效和绿色计算。
获奖情况
中国信通院云原生技术创新案例奖


社区会议纪要
最新 Koupleless (SOFAServerless) 社区会议
会议纪要详见:双周会历史记录
Koupleless (SOFAServerless) 24.01.23 社区会议
会议纪要详见:https://github.com/koupleless/koupleless/issues/12
Koupleless (SOFAServerless) 24.01.09 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/445
Koupleless (SOFAServerless) 23.12.26 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/415
Koupleless (SOFAServerless) 23.12.12 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/387
Koupleless (SOFAServerless) 23.11.28 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/335
Koupleless (SOFAServerless) 23.11.14 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/280
Koupleless (SOFAServerless) 23.11.02 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/214
Koupleless (SOFAServerless) 23.10.17 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/162
Koupleless (SOFAServerless) 23.09.27 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/117
Koupleless (SOFAServerless) 23.09.19 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/100
Koupleless (SOFAServerless) 23.09.04 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/44
Koupleless (SOFAServerless) 23.08.21 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/38
视频回放:https://www.bilibili.com/video/BV19r4y1R761
Koupleless (SOFAServerless) 23.08.07 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/13
Koupleless (SOFAServerless) 23.07.03 社区会议
会议纪要详见:https://github.com/sofastack/sofa-serverless/issues/1
视频回放:https://www.bilibili.com/video/BV1dh4y1f7KW
Koupleless (SOFAServerless) 23.06.05 社区会议
会议纪要详见:https://github.com/sofastack/sofa-ark/issues/661
Koupleless (SOFAServerless) 23.05.08 社区会议
会议纪要详见:https://github.com/sofastack/sofa-ark/issues/636
视频回放:https://www.bilibili.com/video/BV1Qs4y1D7Lv
Koupleless (SOFAServerless) 23.04.03 社区会议
会议纪要详见:https://github.com/sofastack/sofa-ark/issues/635
视频回放:https://www.bilibili.com/video/BV1f84y1K7qd
大会分享与干货文章视频
技术会议
2024 Apache COC 大会
举办时间:20240726 会议 PPT: 点击此处下载
KCD 开发者交流会 深圳站
举办时间:20231216
会议 PPT: 点击此处下载
QCon 大会 - Koupleless (SOFAServerless) 微服务新架构的探索与实践
举办时间:2023.09
会议 PPT:点击此处
SOFAStack 开源四周年大会 - 蚂蚁 Koupleless (SOFAServerless) 技术体系化介绍
举办时间:2022.07
会议视频:https://www.bilibili.com/video/BV1nU4y1B7u3
会议 PPT:点击此处
技术分享视频
开源人 - SOFAArk 类隔离框架底层原理
发布时间:2022.06
https://www.bilibili.com/video/BV1gS4y1i7Fg
技术分享文章
蚂蚁 Koupleless (SOFAServerless) 微服务新架构的探索与实践
发布时间:2023.08
https://mp.weixin.qq.com/s/dSyWTEascUkF4Jd3_RBjVQ
Koupleless (SOFAServerless) 应用架构助力业务 10 倍效率提升,探索微服务隔离与共享的新平衡
发布时间:2023.07
https://mp.weixin.qq.com/s/JQYtk-Z54udV5Fhaf_akjg
线上应用 10 秒启动、只占 20M 内存不再是想象~SOFAServerless 为你带来极致研发体验
你想让手上的工程仅需增加一个打包插件,即可变成10秒启动,只占20M内存的工程吗?你是否遇到大应用多人协作互相阻塞,发布效率太低的问题吗?是否遇到小应用太多,资源浪费严重的问题吗?今天我们和大家介绍基于模块化能力,从应用架构、研发框架和运维调度方面提供的完整配套的 SOFAServerless 项目,帮助解决这些与你息息相关的问题,让存量应用一键接入,享受秒级启动、资源无感等收益,轻松跨入 Serverless 研发模式,帮助企业降本增效。
模块化应用架构
为了解决这些问题,我们对应用同时做了横向和纵向的拆分。首先第一步纵向拆分:把应用拆分成基座和业务两层,这两层分别对应两层的组织分工。基座小组与传统应用一样,负责机器维护、通用逻辑沉淀、业务架构治理,并为业务提供运行资源和环境。通过关注点分离的方式为业务屏蔽业务以下所有基础设施,聚焦在业务自身上。第二部我们将业务进行横向切分出多个模块,多个模块之间独立并行迭代互不影响,同时模块由于不包含基座部分,构建产物非常轻量,启动逻辑也只包含业务本身,所以启动快,具备秒级的验证能力,让模块开发得到极致的提效。
拆分之前,每个开发者可能感知从框架到中间件到业务公共部分到业务自身所有代码和逻辑,拆分后,团队的协作分工也从发生改变,研发人员分工出两种角色,基座和模块开发者,模块开发者不关系资源与容量,享受秒级部署验证能力,聚焦在业务逻辑自身上。
这里要重点看下我们是如何做这些纵向和横向切分的,切分是为了隔离,隔离是为了能够独立迭代、剥离不必要的依赖,然而如果只是隔离是没有共享相当于只是换了个部署的位置而已,很难有好的效果。所以我们除了隔离还有共享能力,所以这里需要聚焦在隔离与共享上来理解模块化架构背后的原理。
架构的优势
我们根据在蚂蚁内部实际落地的效果,总结模块化架构的优势主要集中在这四点:快、省、灵活部署、可演进上,

与传统应用对比数据如下,可以看到在研发阶段、部署阶段、运行阶段都得到了10倍以上的提升效果。
适用的场景
经过在蚂蚁内部 4 到 5 年的打磨,逐渐沉淀出适用的6大场景,可以看看是否有你适合的口味?

运维调度平台架构
只有应用架构还不够,需要从研发阶段到运维阶段到运行阶段都提供完整的配套能力,才能让模块化应用架构的优势真正触达到研发人员。
 在研发阶段,需要提供基座接入能力,模块创建能力,更重要的是模块的本地快速构建与联调能力;在运维阶段,提供快速的模块发布能力,在模块发布基础上提供 A/B 测试和秒级扩缩容能力;在运行阶段,提供模块的可靠性能力,模块可观测、流量精细化控制、调度和伸缩能力。
组件视图
在整个平台里,需要个组件:
- 研发工具 Arkctl, 开发者使用 Arkctl 完成模块快速创建、快速联调测试等能力
- 运行组件 SOFAArk,提供基于 ClassLoader 的多模块运行的环境
- Arklet 和 Runtime 组件,提供模块运维、模块生命周期管理,多模块环境适配
- 控制面组件 ModuleController
- ModuleDeployment 提供模块发布与运维能力
- ModuleScheduler 提供模块调度能力
- ModuleScaler 提供模块伸缩能力
在这些组件基础上提供了从研发到运维到运行时的完善的配套能力。
多集群,弹性与调度

将线上应用根据场景隔离出不同机器组,不同机器组上可以安装不同模块,给不同业务提供不同的 QOS 保障。同时可以单独划分出 buffer 机器组,当业务机器组机器不够时,可以快速从 Buffer 机器组里调度出机器,安装上相应的模块,完成 10 秒级的扩容。

由于模块的启动速度在 10 秒级,所以在弹性上也能做到与服务更加同频,伸缩更加实时,这里看到应用实例数曲线与流量曲线基本处于一致的状态。
可观测、高可靠、排障等能力
模块化运维调度作为在 pod 上一层的模型,与现有配套设施会有些不同,所以需要针对配套设施完成可观测、监控排障等能力适配。

AB 测试/灰度
一个模块更新时,可以同时存在多个版本,通过引流规则完成灰度测试,或者 A/B 测试。

流量隔离与精细化路由
在上述中已经将应用粒度从机器分组,代码分组(模块)上做了更细粒度的划分,这里我们进一步将流量也进一步细粒度划分。一组模块和对应所在的机器组可以分配不同的流量单元,可以根据请求的不同参数,精细化路由到对应的流量分组中。

当前完整能力已经开源 https://github.com/sofastack/sofa-serverless,并提供 2 分钟上手试用视频教程,https://sofaserverless.gitee.io/docs/video-training/ 欢迎试用,也期待与大家一起建设社区。当前已接入 15+ 企业列表

如果你也想帮助企业完成降本增效,欢迎咨询探讨。


未来展望
在未来,SOFAServerless 将持续不断地探索,根据业务痛点为各行各业提出 Serverless 的解决方案。感谢各位开源共建开发者一直以来的支持与付出!排名不分先后
@QilingZhang @lvjing2 @glmapper @yuanyuancin @lylingzhen @yuanyuan2021 @straybirdzls @caojie09 @gaosaroma @khotyn @FlyAbner @zjulbj @hustchaya @sususama @alaneuler @compasty @wuqian0808 @nobodyiam @ujjboy @JoeKerouac @Duan-0916 @poocood @qixiaobo @lbj1104026847 @zhushikun @xingcici @Lunarscave @HzjNeverStop @AiWu4Damon @vchangpengfei @HuangDayu @shenchao45 @DalianRollingKing @lanicc @azhsmesos @KangZhiDong @suntao4019 @huangyunbin @jiangyunpeng @michalyao @rootsongjc @liu-657667 @CodeNoobKing @Charlie17Li @TomorJM @gongjiu @gold300jin @nmcmd
12 月 16 日 KCD 2023 深圳站(插入文章链接),期待和各位技术爱好者面对面交流探讨!
我将分享**《云原生微服务的下一站,蚂蚁 SOFAServerless 新架构的探索与实践》,活动现场还将设立展台进行 SOFAServerless 能力演示、操作流程互动展示**。如果你对 SOFAServerless 感兴趣,欢迎前来参与体验~
体验可以点击:https://sofaserverless.gitee.io/docs/tutorials/trial_step_by_step/
如有问题可在 SOFAServerless GitHub 上及时提交 issue 互动交流~
成倍降本增效,提升企业竞争力!SOFAServerless 品牌升级为 Koupleless,重磅发布 1.0 版本
- 如果你是企业经营者,在为企业降本增效而发愁……
- 如果你是企业的开发、运维或架构同学,在日常工作中被开发效率、交付问题等困扰……
欢迎来了解 Koupleless(原 SOFAServerless)!
现在,Koupleless 重磅发布 1.0 版本!那么 Koupleless 是什么?又将如何为你解决以上问题呢?除了以上这几种情境,Koupleless 还有哪些能力呢,等着你来探索发现。
Koupleless 是什么?
Koupleless 原名 SOFAServerless,是一款模块化研发框架与运维调度平台。它从应用架构角度出发,帮助应用解决从需求、到研发、再到交付的全生命周期中的痛点问题。其最核心的架构图如下👇。如果想了解更详细的原理介绍也可以查看官网页面。

它能帮助解决的问题包括:
- 应用拆分过度,机器成本和长期维护成本高;
- 应用拆分不够,多人协作互相阻塞;
- 应用构建、启动与部署耗时久,应用迭代效率不高;
- SDK 版本碎片化严重,升级成本高周期长;
- 平台、中台搭建成本高,业务资产沉淀与架构约束困难;
- 微服务链路过长,调用性能不高;
- 微服务拆分、演进成本高;
其中是否有哪些问题困扰着你?可以来看看 Koupleless 的解决方案。
本模式在蚂蚁集团内部历经 4-5 年时间孵化而成,当前已经帮助 70W 核业务量完成 10 倍级降本增效,可以帮助应用做到秒级启动,只占 20M 内存。
性能对比示例如下图👇。

根据我们的模块化应用架构模型,可以看到我们是将传统应用从纵向和横向切分演变而来的。所以我们将 SOFAServerless 进行品牌升级为 Koupleless,取自 Couple + less,寓意通过对应用进行拆分解耦,实现更好的职责分工,帮助业务降本增效。

我们为什么开源
关注应用架构领域的同学,应该知道微服务很好地解决了组织分布式协作难题,但同时也带来了一些问题,并且这些问题正日益获得更多关注。
有人说,2023 年是微服务的转折年。一些科技巨头(如 Amazon 和 Google )已经开始尝试去解决和完善微服务带来的问题,例如 service weaver,amazon prime video的架构改造,甚至直接回归单体。

而蚂蚁内部在 4-5 年前就开始着手解决微服务问题,并为此打造了 Koupleless 应用研发模式。
根据蚂蚁这些年的实践经验,我们相信模块化架构是一种有潜力的架构,是真正能够较好地解决微服务问题;我们也希望通过模块化架构给行业内部提供一种新的解决方案,帮助更多企业降本增效。
开源提供了哪些能力
自 2023 年下半年开源以来,经过这半年时间和社区的共同努力,我们已经开放了内部完整的能力,包括研发工具、框架、运维调度平台等;也沉淀了一些常用组件最佳实践和 samples 用例。
基本上具备了可生产使用级别,一些企业也已经可以按照官网和文档自主接入使用了。

研发工具 Arkctl
一键构建、部署和发布模块,方便用于本地开发测试验证
Arklet、SOFAArk 和 Runtime 组件
为多种研发框架如 Spring Boot、SOFABoot、Dubbo 提供多模块运行容器环境,适配 30+ 组件,沉淀 15+ samples 用例
控制面组件 ModuleController
- ModuleDeployment,提供模块发布与运维能力
- ModuleScheduler,提供模块基础调度能力
- ModuleScaler,提供模块扩缩容能力
有了这些组件之后,从开发验证 -> 交付上线 -> 日常运维全流程的基本能力已经具备,1.0 版本实现生产可用级别。
挑战与亮点
这套模式最大的挑战来自于将多个应用或代码片段合并在一起,在隔离与共享上如何找到最佳的平衡点,在存量应用低成本接入的同时,能享受到隔离的带来稳定可靠的好处,也能享受到共享的高性能、低资源消耗的收益。
隔离可以确保运行时的稳定可靠,但带来了性能的下降、资源利用率的损失;共享提升了性能和资源利用率,但也带来了运行时的一些问题,例如 static 变量可能带来互相影响的问题。我们采用了模块化技术来解决这类问题,在 JAVA 领域模块化技术并不是我们首创的,20 年前就有了 OSGI 技术,那为什么我们的模块化技术能在蚂蚁内部规模化落地呢?我们是做了哪些工作来解决存量应用低成本接入和共享后的一些问题的呢?
要解决这类问题,我们并没有太多可参考的行业案例,相当于是在无人区里摸索,除了解决隔离与共享的核心问题外,还要解决配套设施的建设、用户心智的培养等,这些都需要一个笃定的心力和持续的过程,这些问题也就是这套模式的挑战所在。
好在最终,我们拨云见日探索了出来。我们在隔离和共享之间找到了一个最佳的平衡点,并且能让存量业务低成本的接入,这也是我们最自豪的地方。我们在蚂蚁集团用事实证明了模块化技术并不是停留在设计稿里的技术,或者小部分人才能使用的技术,它的问题和挑战并不可怕,是有固定模式的,可以通过工具和流程逐步治理、收敛的,现在将此模式进行开源分享,是希望可以帮助其他企业少走弯路,和社区一起把这套模式心智在行业里树立起来。
Koupleless 已接入 15+ 企业
当前在统计内的,有 15+ 企业在使用 Koupleless 接入线上或者用于交付,还有17+ 企业正在试用或者接入中,还有一些因为信息缺失未统计到的。详细企业接入列表可以查看官网信息。
很高兴 Koupleless 能帮助到他们,也十分欢迎这些企业探索的更多使用场景,也欢迎更多企业开发者一起参与社区建设,推广这套技术。
Koupleless 未来的规划
我们希望能让模块化架构成为应用架构领域里的新模式,能在行业里推广开来。这不仅是我们作为技术人的技术追求,也是我们做开源的持续动力来源。
当前我们虽然发布了 1.0 版本,但开源工作才只是刚刚开始,还有更多规划。比如,我们希望未来能把模块化技术做得更加完善,将我们想要做到的效果完整地提供出来:
Speed as you need,
Pay as you need,
Deploy as you need,
Evolute as you need 。
需要的能力包括支持各种框架、运行时组件、中间件服务,还有非常多相关的配套设施;也希望这套模式能在更多语言里发挥出效果,例如 Go语言,以此和更多的小伙伴们一起探索出微服务领域的下一站。

这里感谢所有参与贡献 Koupleless 1.0 的 51 位开发者
@QilingZhang @lvjing2 @glmapper @yuanyuancin @lylingzhen @yuanyuan2021 @straybirdzls @caojie09 @gaosaroma @khotyn @FlyAbner @zjulbj @hustchaya @sususama @alaneuler @compasty @wuqian0808 @nobodyiam @ujjboy @JoeKerouac @Duan-0916 @poocood @qixiaobo @lbj1104026847 @zhushikun @xingcici @Lunarscave @HzjNeverStop @AiWu4Damon @vchangpengfei @HuangDayu @shenchao45 @DalianRollingKing @lanicc @azhsmesos @KangZhiDong @suntao4019 @huangyunbin @jiangyunpeng @michalyao @rootsongjc @liu-657667 @CodeNoobKing @Charlie17Li @TomorJM @gongjiu @gold300jin @nmcmd @qq290584697 @ToviHe @yuhaiqun19892019
Koupleless 内核系列|模块化隔离与共享带来的收益与挑战
本篇文章属于 Koupleless 进阶系列文章之一,默认读者对 Koupleless 的基础概念、能力都已经了解,如果还未了解过的可以查看官网。
进阶系列一:Koupleless 模块化的优势与挑战,我们是如何应对挑战的
进阶系列二: Koupleless 内核系列 | 单进程多应用如何解决兼容问题
进阶系列三:Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
进阶系列四:Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
进阶系列五:Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
在 Koupleless 模块化架构下,有四大特点:快、省、灵活部署、平滑演进,这些主要的优势来自于对应用架构的纵向和横向的分层解耦,在隔离与共享之间寻找最佳的平衡,同时也对应用全生命周期(需求 -> 研发-> 测试验证 -> 发布 -> 线上运维调度等)流程进行升级,包括基座提前预热、模块独立迭代、机器合并复用等上。这篇文章会从运行时隔离和共享的角度分析 Koupleless 模块化的优势,对应的性能 benchmark 对比,同时也会详细介绍模块化背后的挑战和解决方式。
共享带来的优势分析
传统的 SpringBoot 之间完全隔离,相互之间通过 RPC 进行通信,模块化的模式在于模块之间存在更直接的共享能力,包括类和对象,以及更直接更高效的本机 jvm service 调用等,从而在隔离与共享之间找到一个更佳的平衡点。为了深入分析在隔离的基础上增强共享带来的效果,我们以社区应用 eladmin 为基础拆出一个基座 + 三个模块进行实验,统计了一些数据提供给用户查看,如果兴趣也可以自行下载验证。

类的共享
Koupleless 采用 SOFAArk 将模块里的类委托给基座加载,可以让模块 ClassLoader 运行时只加载模块特有的类,模块打包不会包含这些被复用的类,从而降低打包构建产物的大小以及运行 MetaSpace 的内存消耗,根据模块与基座相同类的占比不同,降低的大小和比例也不同。在 eladmin 中,可以看到镜像化在 300MB,而模块化构建产物只有 100KB。

构建产物大小对比(假设基础镜像为200M)
对象的共享
对象的共享主要通过如下两种方式来复用基座上的对象、逻辑、资源、连接等:
- static 变量或对象的共享
- 模块通过 Jvm Service 调用基座的逻辑,类似 api 调用且没有序列化的开销
static 对象共享
多个模块通过类委托加载机制复用基座类,这些复用的类里一些 static 变量在基座启动时已经初始化完成,模块启动时发现这些类里的 static 变量已经初始化过就会直接返回基座初始化的值,这样基座类里定义的 static 变量或对象会被模块共享,特别是单例对象,在中间件里存在不少这样的对象。这些对象在模块初始化时自动判断是否存在实例,存在了就会复用,例如 ehcache 里的 CacheManager。

模块 JVM Service 调用基座
基座内的通用逻辑定义在基座 bean 或者接口里,模块可以通过注解 (Dubbo 与 SOFARPC 的注解) 或者 api 的方式调用这些 bean 或接口。这样模块启动可以无需再次初始化基础设施服务或者连接,能降低模块资源消耗提升模块启动速度。同时由于这些接口 和 bean 是在同一个进程里,通过 api 或 JVM Service 调用没有序列化与反序列化开销,所以也不会出现调用性能下降问题。
通过上述介绍的类和对象复用,我们可以看到模块的内存消耗相对于传统应用,从原来的 200MB 下降到了 30 MB,同时因为减少了一些类与对象的初始化逻辑,启动时间也从原来的 8 秒下降到4秒。

内存消耗大小对比

启动耗时对比
| eladmin-mng | eladmin-quartz | eladmin-system | |||
|---|---|---|---|---|---|
| 构建产物大小对比(MB) | 内存消耗对比(MB) | 启动耗时对比(s) | 构建产物大小对比(MB) | 内存消耗对比(MB) | |
| 微服务 | 325 | 200 | 8.63 | 327 | 192 |
| 模块化 | 0.112 | 33 | 3.67 | 0.051 | 34 |
详细数据表
可以看到共享带来了成倍级的收益,收益的多少和复用多少基座的类和资源有关,如果基座沉淀更多的逻辑和资源,那么模块的启动速度还可以提升更多。在蚂蚁集团内部由于基础设施的 sdk 较多,将这些下沉到基座后,模块的复用率较高,大部分应用的启动速度从分钟级降到了 10秒 左右。
共享带来的问题分析
共享除了带来收益外,在一些特殊情况下也会带来一些问题。这些问题主要在于多应用与热部署这两方面
- 多应用主要是 Static 变量共享、多 ClassLoader 的切换
- 热部署主要是动态卸载时部分资源不会释放
Koupleless 结合在蚂蚁逻辑 5 年的经验,提炼了遇到的问题列表,并给出对应的解决方案。这里将遇到的问题列出来,让大家清楚模块化的问题与挑战,与社区一起共同完善模块化框架。
类共享
当前类共享的设计是模块将一些公共类委托给基座,模块类查找时可以复用基座的类。
Static 共享变量
在单进程多个应用模式下,模块复用基座里的类,这些类里的 Static 变量在基座启动时会完成一次初始化,模块再次启动时,在如下两种情况下
- 直接复用基座的值
那么大部分是符合预期的,在少部分模块希望使用自己的值,这时候会发现使用的是基座值而与实际预期不符
- 直接覆盖基座的值
对于一些希望使用模块自身值的情况,直接覆盖原有的值,那么会出现覆盖问题,static 最后只保留最后一次安装的值
解决方式:遇到这类情况只要将原来 static 变量增加一层 key 为 classLoader 的 map 即可解决。
多 ClassLoader
我们定义了类委托关系,是优先查找模块里的类,模块查找不到再查找基座里的类。但由于模块除了一些能够委托给基座的类外,一定存在一些无法委托给基座的类,也就是部分委托的方式。所以在类查找过程中会有这 5种情况。





这5种情况下,在少数情况下会出现如下的一些异常 case:
- 模块和基座里都有的类:如果某些类同时被两个 ClassLoader 加载,且涉及到类的 instanceOf 等判断,会导致一些 LinkageError 或者
is not assignable to的错误。 - 模块里有、基座里没有的类:如果由模块 ClassLoader 进入到基座 ClassLoader,然后在基座 ClassLoader 里执行 Class.forName(“模块类名”) 方法,会查找不到类。
解决方式:这里我们需要通过 adapter 确保查找类的时候,传入正确的模块 ClassLoader。另外在线程池下,存在线程复用,需要将线程与对应 ClassLoader 的绑定正确。
部分资源没有自动卸载(热部署才有)
模块 SpringBoot 的关闭实际上只是调用了 SpringContext 的 Shutdown 方法,底层依赖 Spring 的 Context 管理进行服务和 Bean 的卸载、依赖 JVM 的 GC 进行对象的回收,没有执行真正的 JVM 关闭操作。由于框架和业务设计和开发一般较少关注 Shutdown 时的资源清理的,主要依赖 JVM 的关闭操作自动完成资源的清理。所以模块在热部署是先卸载后安装可能存在一些线程、资源、连接等未清理问题。
解决方式:只要用户主动监听 SpringContext Close 事件,主动做下清理工作即可。热部署还有另外一个 metaspace 会在每次安装增涨的问题,这个 Koupleless 会在安装时检测 metaspace 阈值,超过阈值可以回退到重启安装即可解决 metaspace 增涨问题。
共享带来问题的解决方案
为了更系统的解决这些问题,我们从问题的发现 -> 治理 -> 防御都做了设计和工具实现,这些会在系列的后续文章里进行介绍。另外我们也通过分析用户需求,发现不同场景并不是所有的问题都需要解决的,只需要解决其中部分问题即可。
中台模块
中台模块追求启动快、占用资源少,模块较为轻量,以代码片段为主,较少直接引入一些中间件,一般不需要处理 static / classLoader / 资源卸载等问题,这种模式是问题域最小的,上述所说问题基本不存在,可以直接集成接入 Koupleless 使用。
| 是否有问题 | 解决方式 | 解决后是否还有问题 | |
|---|---|---|---|
| static 共享变量问题 | 无 | 无需处理 | 无 |
| 多 ClassLoader 问题 | 无 | 无需处理 | 无 |
| 卸载残留问题 | 无 | 无需处理 | 无 |
应用模块
相对于中台模块的是应用模块,应用模块也就是模块较重,和普通应用一样可以使用各种中间件等能力,这种模式会存在上述提到的一些问题。对于应用模块存量两种场景,一种是长尾场景另一种是非长尾场景,非长尾场景遇到的问题相对可以较少,我们先看下非长尾场景。
非长尾应用
非长尾应用指每台机器的流量都较充分,已经较充分利用了每一台机器的计算能力。这类应用一般没有因为拆分微服务造成的资源浪费问题,更多关心的是启动速度、迭代效率。我们可以部署和调度策略,解决一部分问题。首先可以通过 1:1 的方式在一个基座机器上仅安装一个模块,能在达到较快启动的同时,避开多个应用合并在一起的问题。同时可以通过调度的方式,每次模块安装新版本的时候可以选择空基座(没有安装过任何模块)机器进行安装,原来老版本可以通过异步重启的方式卸载掉老模块,解决热部署的卸载残留问题。以一个模块的升级过程为例,具体过程如下:
第一步,初始状态

第二步,从buffer 里筛选一台机器安装模块 1 版本 2

第三步,将版本 2 的基座机器调度给基座 1,将版本 1 的基座机器调度给 buffer
第四步,buffer 集群发现有机器有已废弃的模块实例,则发起重启,从而清理掉上面的模块实例

以此类似,把基座 1 所有机器都升级到版本 2

这套方式的效果如下表:
| 是否存在 | 解决方式 | 解决后是否还存在 | |
|---|---|---|---|
| static 共享变量问题 | 有 | 1:1,一个基座上仅安装一个模块 | 无 |
| 多 ClassLoader 问题 | 有 | 1:1,一个基座上仅安装一个模块 | 无 |
| 卸载残留问题 | 有 | 异步调度,安装模块新版本的时候,选择无模块的基座实例,不存在卸载老版本过程 | 无 |
长尾应用/私有化交付
这个场景里追求省资源,这就需要把多个应用合并在一个 jvm 里,就会遇到多应用的 Static 变量和 ClassLoader(如果解决 RPC 调用消耗上把多应用合并在一起也有类似问题)。这种模式根据是否需要追求迭代也分两种:
- 不需要高效迭代,可以直接使用静态合并部署,不会存在热部署的卸载残留问题。
| 是否存在 | 解决方式 | 解决后是否还存在 | |
|---|---|---|---|
| static 共享变量问题 | 有 | 从发现 –> 治理 –> 回归防御 逐步治理 | 无 |
| 多 ClassLoader 问题 | 有 | 从发现 –> 治理 –> 回归防御 逐步治理 | 无 |
| 卸载残留问题 | 无 | - | 无 |
- 动态合并部署,该模式会有多应用、热卸载的问题,多应用的问题无法规避,需要通过我们提供的整套工具逐步完善解决,热卸载的问题可以通过模块部署的时候同步或异步的方式重启基座解决。
| 是否存在 | 解决方式 | 解决后是否还存在 | |
|---|---|---|---|
| static 共享变量问题 | 有 | 从发现 –> 治理 –> 回归防御 逐步治理 | 无 |
| 多 ClassLoader 问题 | 有 | 从发现 –> 治理 –> 回归防御 逐步治理 | 无 |
| 卸载残留问题 | 有 | 可以通过模块部署的时候,同步或异步的方式重启基座来解决 | 无 |
后续我们会建设 ModuleController 和对应的平台能力,针对不同的场景提供不同的“套餐”,帮助各位按需选择适合的模式。这是 Koupleless 为了帮助存量应用解决对应实际问题,从框架和平台角度共同解决的思路,如果感兴趣的同学,欢迎访问官网 koupleless.io 加群共同建设。
Koupleless 内核系列 | 单进程多应用如何解决兼容问题
本篇文章属于 Koupleless 进阶系列文章第二篇,默认读者对 Koupleless 的基础概念、能力都已经了解,如果还未了解过的可以查看官网。
进阶系列一:Koupleless 模块化的优势与挑战,我们是如何应对挑战的
进阶系列二: Koupleless 内核系列 | 单进程多应用如何解决兼容问题
进阶系列三:Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
进阶系列四:Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
进阶系列五:Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
多应用兼容性 —— Koupleless 极速研发体系下存在的问题
Koupleless 是模块化研发的体系,应用被抽象成了基座和模块两个部分,模块可以动态地安装到基座上,如下图所示:

通过该抽象,一个进程里可以运行多个应用,用户可以享受到:节省资源、快速部署、迭代提效等收益。具体解析可以参考文章:https://koupleless.io/docs/introduction/architecture/arch-principle/
这种单进程多应用的模式背后其实是共享与隔离的极致平衡,像文中所说的,隔离可以带来独立的迭代升级能力,共享可以带来极致的启动速度与研发效率。但是共享会带来互相干扰的问题,如进阶系列第一篇文章所说,需要引入额外的兼容性治理,首先兼容性问题大致可以分为 3 大类:
- 全局变量互相污染(多数为 static 变量、System Properties 导致)
- ClassLoader 不匹配
- 部分资源不卸载(只有热部署时才会有)
综上,为了让用户能低成本地享受到 Koupleless 的收益,同时保证业务执行的正确性,我们设计了从问题的发现 -> 治理 -> 防御 角度全面治理此类问题的方案,在每个阶段分别提供了相应的工具和组件:
问题发现
问题发现部分主要分为静态问题暴露和动态问题暴露两块:
- 静态问题暴露:通过静态代码扫描工具,识别潜在的不兼容点,并由人工确认和修复。
- 动态问题暴露:提供简单易用的 koupleless 运行时集成测试框架,允许用户低成本地编写集成测试逻辑,回归验证模块行为符合预期。
问题治理
当我们发现问题后,需要提供对应的兼容性修复方案。为此,我们提供了基座构建插件,自动进行兼容性修复,帮助用户低成本地解决兼容性问题。
问题防御
集成测试框架,同样可以帮助完成治理后回归验证问题,避免版本升级带来的回归问题。
问题发现:代码扫描工具
在 Java 单进程多应用模式下,根据团队的经验积累,我们发现了一些常见的不兼容静态代码模式。基于这个现状,我们可以通过静态代码扫描工具来识别这些模式,在运行前暴露风险,让开发者尽早修复问题。
常用的不兼容模式
常用的不兼容模式主要有 3 类:
- 全局变量相互污染:比如基座通过 static 维护了一些全局变量,多个模块在写入 / 读取 static 变量的时候可能是用了同一个 key,进而导致潜在的互相污染的风险。
- classLoader 不匹配问题:在 sofa-ark 类隔离机制中,属于模块自身的类只能由自己的 classLoader 加载。因此,在一些 classLoader 使用不正确的时候,例如用基座的 classLoader 加载模块类的全称,可能会出现预期外的问题。
- 模块泄漏问题:在多模块架构中,模块是一个单独的运维单位,如果卸载模块时没有正确地关闭一些服务,例如 shutdown 线程池,可能会导致内存泄漏的问题。
代码扫描工具
上述 3 类问题是 koupleless 不兼容的主要问题,我们可以通过一些常见的代码片段模式进行问题识别和暴露这 3 类问题,然后由人工进行确认和修复。
为此,我们基于开源社区的 sonarqube 静态代码扫描服务,开发了针对性的静态代码扫描插件,以帮助开发者快速地发现问题,从而进行有效的治理。目前项目已经开源,地址在 https://github.com/koupleless/scanner .
目前已有的扫描规则有:
- static 变量扫描:扫描和暴露可修改的 static 变量(不可修改的变量无污染问题)。当然,由于工程中使用 static 变量是一种常见的模式,全部告警可能会造成大量噪音,因此我们也基于一定的特征(命名、类型等)进行了没有潜在风险的降噪处理。
- class.forName 方法调用扫描:class.forName 会使用堆栈中 caller 的 classLoader 进行类加载,这往往是基座的 classLoader, 因此有较高的风险导致 ClassNotFound。
- SomeClass.getClassLoader 方法:如果要加载的目标类和 SomeClass 不在一个模块中,则会导致 ClassNotFound 异常,有比较高的风险。
当前已经有一些企业在使用该工具。未来,扫描规则还会持续完善,也欢迎开源社区的各位在发现了新的不兼容模式后,将其完善成为规则,并且 PR 贡献,让静态代码扫描规则越来越完善!
问题治理:基座构建插件 —— 让基座低成本地快速增强多应用模式
前一小节我们提到,koupleless 运行时可能由于引入多应用污染的问题而导致需要兼容性修复,而兼容性修复又主要解决 3 大问题:
- 修复原有代码:一些组件的某个版本已经固化,已不再允许提高代码修改,如何才能低成本的方式修改原有逻辑增强多应用的能力?
- 多版本适配:同一组件不同版本之间的实现可能不同,导致修复方式也不同。如何修改这么多的版本,并做到长期的可维护呢?
- 用户如何低成本的使用:每个组件对应不同版本可能有不同的增强逻辑,用户怎么知道具体要引入哪段增强逻辑呢?怎样才能让用户低成本甚至不感知的情况下,自动帮助找到对应的增强逻辑呢?
接下来,我们继续介绍一下是如何解决这些问题的。
如何低成本增强组件原有代码
这里的低成本要考虑两点:
- 组件本身代码增强的低成本,让 Koupleless 贡献者能低成本扩展一些组件支持多应用能力。
- 每个组件存在许多历史版本,一个组件的不同版本其实现可能不同,进而需要增强的逻辑也不同,如何能低成本的增强这些历史版本,而非逐个版本的增强。
常见的手段有三种:同名类覆盖、反射、提交到修复的主分支。
| 修复方法 | 优点 | 缺点 |
|---|---|---|
| 同名类覆盖 | 修复逻辑比较直观,还可以用 diff 软件和源文件进行实现的对比。 | 需要用户引入额外的依赖,以及必须优先于原有实现被 JVM 加载。 |
| 反射 | 不需要用户引入额外的依赖,可以由框架自动代理类和生成增强。 | 无法直观地看到增强逻辑,可维护性比较差,可能有性能影响。 |
| 提交到修复的主分支 | 用户只需要升级 SDK 即可修复。 | 迭代周期比较长,无法及时解决用户问题,以及许多用户用的是历史老版本,官方可能不再维护接受 PR。 |
为了有更好的可维护性 koupleless 最终采用了同名类覆盖的办法,并将有关增强类统一放置在了独立仓库: https://github.com/koupleless/adapter 。
每个组件的多版本问题,所以这里也维护了组件不同版本的不同 adapter 实现列表,如 log4j2,这里 koupleless-adapter-log4j2-spring-starter-2.1 实际上是增强了springboot 2.1 版本到 3.2 的所有版本。

如何解决用户低成本使用问题
某个组件不同版本对应的增强逻辑不同,这也给用户带来了使用负担,为了进一步降低用户的接入成本,免去用户对照依赖版本查询增强的繁琐,我们也提供了 koupleless-base-build-plugin 插件,用户可以将如下构建插件添加到自己的 maven 工程中:
<plugin>
<groupId>com.alipay.sofa.koupleless</groupId>
<artifactId>koupleless-base-build-plugin</artifactId>
<version>${koupleless.runtime.version}</version>
<executions>
<execution>
<goals>
<goal>add-patch</goal>
</goals>
</execution>
</executions>
</plugin>
该插件会动态地解析用户使用的依赖,识别到需要增强的依赖,并动态地添加增强类,工作流程如下图所示:

值得注意的是,在使用增强的过程中,我们必须保证对于一个同名类,koupleless 维护的增强优先于原本的类被 classLoader 加载。
我们在 koupleless-base-build-plugin 中保证了这个优先级,保证的方法是在 maven 的 generated-sources 阶段将增强类拷贝到当前工程中,正如上述流程图的 5~6 步所示,而当前工程中的类加载优先级是最高的。用户可以参考 samples 工程 https://github.com/koupleless/samples/tree/main/springboot-samples/logging/log4j2 进行验证和实践,在当前项目下执行 maven clean package 命令后,可以看到构建结果如下图:

总结一下,用户可以通过在 maven 工程中引入 koupleless-base-build-plugin 插件保证其业务逻辑在多应用模式下的兼容性,其优势有:
- 通过同名类覆盖的方式自动修复潜在的兼容性问题。
- 通过动态依赖映射减少用户自己查询依赖到补丁的映射。
- 通过将补丁拷贝到当前的工程目录自动解决补丁优先级应该是最高的问题。
如此,用户只需要引入一个构建插件,即可快速地接入 koupleless。
问题防御:集成测试框架 —— 简单又快速验证正确性的效率神器
当然,由于这套模式在一个 JVM 里运行多个应用不可避免存在的一些兼容性问题,我们当然不能指望用户每次都到生产才发现这个问题。我们需要将风险左移,在本地测试验证的时候尽可能地暴露问题。不过,由于 koupleless 是以动态加载 jar 包的模式实现单进程多应用的,我们也推出了集成测试框架 koupleless-test-suite 来尽可能地简化中间件、sdk 开发者的验证流程,也便于未来治理后的回归性验证。
原生的集成测试编写方式有什么问题
那么 koupleless-test-suite 解决了什么问题呢?假设没有这个框架,当用户需要在本地验证代码的正确性时,其需要经历如下的操作步骤:
- 构建基座代码。
- 启动基座代码。
- 构建模块代码。
- 安装模块代码。
- 进行 http / rpc 掉用验证接口结果。
如果 5 失败,则用户需要反复地在 3~5 之间来回操作,并且会涉及在多个 ide / 终端之间的来回切换。
上述步骤是原生的 koupleless 模式无法避免的,因为 koupleless 是多 classLoader 加载多个 jar 包的模式,在该模式下模块单独打包构建是必要的,但这又会引入比较繁琐的验证成本。
集成测试框架如何解决了该问题
为了优化该问题,给用户提供简单直接的编程体验,即在 IDEA 里点一下 Debug 按钮即可调试了。我们需要一定的 mock 能力去在 1 个 jar 包中模拟出多个 jar 包的加载行为,免于用户在多个项目之间来回切换。
最终呈现给用户的接口是非常简洁的,用户需要引入如下依赖:
<dependency>
<groupId>com.alipay.sofa.koupleless</groupId>
<artifactId>koupleless-test-suite</artifactId>
<version>${koupleless.runtime.version}</version>
<scope>test</scope>
</dependency>
启动基座 + 模块的样例代码如下:
public static void setUpMultiApplication() {
multiApp = new TestMultiSpringApplication(MultiSpringTestConfig
.builder()
.baseConfig(BaseSpringTestConfig.builder()
.mainClass(BaseApplication.class)
.build()
)
.bizConfigs(
Lists.newArrayList(
BizSpringTestConfig.builder()
.bizName("biz1")
.mainClass(Biz1Application.class)
.build(),
BizSpringTestConfig.builder()
.bizName("biz2")
.mainClass(Biz2Application.class)
.build())
).build()
);
multiApp.run();
}
上述代码会在一个进程中同时启动基座 + 模块 APP,并且底层类加载的行为和生产基本保持一致。
接着,我们就可以便捷地写验证逻辑了, 比如直接拿到模块内部的 Bean 并且进行行为的验证,如下:
Assert.assertEquals(
"biz1",
SpringServiceFinder.getModuleService(
"biz1",
null,
StrategyService.class
).getAppName()
);
目前,Koupleless 自身的 samples 用例,也都通过这套测试框架来做功能性的测试验证,完整的测试用例可以参照工程样例:
如果你对测试框架的实现方式感兴趣,欢迎参照官方文档 https://koupleless.io/docs/tutorials/multi_app_integration_test 对测试框架各个重要方法的简单介绍。
展望与规划
当然,为了能更好地让用户平滑地接入 koupleless 模式,我们希望与社区共同完善配套工具链,不断完善静态代码扫描与动态集成测试规则,沉淀治理的 adapter,让更多的用户能更低成本的接入使用。
最后欢迎大家来使用 koupleless,并献上您宝贵的意见!
Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
本篇文章属于 Koupleless 进阶系列文章第三篇,默认读者对 Koupleless 的基础概念、能力都已经了解,如果还未了解过的可以查看官网。
进阶系列一:Koupleless 模块化的优势与挑战,我们是如何应对挑战的
进阶系列二: Koupleless 内核系列 | 单进程多应用如何解决兼容问题
进阶系列三:Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
进阶系列四:Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
进阶系列五:Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
在前面进阶系列的文章里,我们介绍了 Koupleless 模块化适用的一些场景,会把多个模块应用安装并运行在一个基座里。大家可能会有一个疑问:一台机器最多能安装多少个模块应用?为了帮助大家更好的了解 Koupleless 模块化的价值,评估生产上部署的策略,这篇文章我们会尝试回答下这个问题,并分析一个模块应用需要消耗多少资源,在日常迭代时需要考虑哪些问题。
模块数量的上限在哪里?
也就是一台机器最多能安装多少个模块应用?如果使用的是静态合并部署,一个基座能安装的模块数量上限,在计算能力允许的前提下,主要取决于模块消耗的内存。根据进阶系列第一篇文章里的数据,一个模块在强制 gc 后消耗 30M 内存(包括堆内存和非堆内存),假如一个 4C8G 的机器,JVM 配置 6G 内存,预留 2G 内存给运行期创建临时对象,那么可以用于安装模块的内存空间大小为 4G,即:总共可以安装的模块数量 = 4000M / 30M = 133 个模块。
如果是动态合并部署呢,即:模块升级时无需重启基座,直接安装模块到正运行的基座上,也称为热部署方式。热部署方式除了需要考虑基座启动后可提供模块消耗的内存,还需要考虑每次热部署新版本后,在卸载老版本时候,老版本占用内存的回收情况,老版本内存是否能全部回收给新版本模块使用。根据实际观察验证,我们发现老版本的内存回收需要考虑这两方面:
- 堆内存:从 JVM 资源视角中,堆内存中旧版本模块的实例不再可达,可以通过 GC 回收给其他模块应用/基座应用继续使用。
- 非堆内存:Metaspace 的回收要求较高,需要满足三个条件“该类的所有的实例对象都已被 GC”、“该类没有在其他任何地方被引用”、“且该类的类加载器的实例已被GC”。在 koupleless 中,模块的每次安装都会产生一个模块实例,每个模块实例都由一个新的 ClassLoader 加载,由于该 ClassLoader 被 Spring ApplicationContext 等运行环境持有,无法彻底回收,导致整个模块实例的非堆内存基本无法回收。
所以这就导致了模块热部署后 Metaspace 的使用只增不减,每次部署需要消耗 Metaspace 资源,成为热部署模块数量上限的主要因素。
举个例子,模块安装了版本 1.0 到基座,接着用户修改了模块代码,热部署版本 2.0 到基座,然后用户又修改了模块代码,热部署版本 3.0 到基座。从用户和框架视角中,现在该基座中只有模块应用 3.0,模块应用 1.0 和 2.0 已经被卸载;但从 Metaspace 视角中,模块 1.0 和 2.0 的 占用的空间不会被释放,仍旧占用 Metaspace 资源,如下图:

因此在热部署场景下,初始时不应该安装过多模块把 Metaspace 用完,而应该留有一定的 Metaspace Buffer 给模块热部署,所以对于 4C8G 的机器,我们可以在静态合并部署的基础上,减少模块数量,从而提高可以热部署的次数。由实际经验,采用动态合并部署的模块数量建议为静态合并部署的模块数量理论值上限的 1/2,也就是 133/2 = 66 个模块,从而给热部署模块预留出一部分的空间。
既然模块安装的数量存在上限,且上限主要取决于 Metaspace 的内存消耗,那么到达上限时会出现什么情况?一般是会触发 Metaspace 的 OOM 从而导致 FullGC,但是 FullGC 又无法清理 Metaspace 的内存消耗,这就会导致不断地 FullGC,从而可能对请求的 RT 产生影响。在这种情况下,我们一般只需要设置好 Metaspace 消耗的阈值然后重启即可,但是为了严谨考虑,我们需要从整个研发到上线的完整过程中分析这个问题。
如何应对模块数量或安装次数的上限?
为了避免模块在安装或运行时达到 Metaspace 上限影响多应用的正常运行,我们可以在应用的研发时 -> 运维时 -> 运行时的全链路上做全链路的防御、检测和自动处理。
研发时降低单个模块占用 Metaspace
首先我们可以尽可能地降低单个模块占用的 Metaspace 消耗,从而让一个机器能安装或热部署的模块数量尽可能高。同时,由于基座升级或者机器自身重启都会清理掉 Metaspace,模块迭代过程可以很少触发上限问题。
由于 Metaspace 主要用于存储类的元数据、方法的元数据以及常量池,因此 Metaspace 使用大小取决于不同 ClassLoader 的数量以及 ClassLoader 加载的类信息的总量大小,那么可以通过减少模块 ClassLoader 加载的类数量和减少模块中创建的 ClassLoader 总量来降低 Metaspace 使用。
- 减少模块 ClassLoader 加载的类数量:在 Koupleless 中,建议用户把模块与基座相同依赖包的依赖范围配置为 provided,这些类可以由模块委托给基座加载,模块打包不会包含这些被复用的类,模块 ClassLoader 运行时也只加载模块特有的类,从而降低运行期间 Metaspace 的内存占用。
- 减少模块创建的 ClassLoader 总量:在开发时,避免写出会造成大量 ClassLoader 只加载一个类的代码😯。(例如在 fastjson 等为了提高性能会动态创建类缓存,存在可能大量创建只加载很少类的 ClassLoader,通过调整 fastjson 的使用可以避免该问题发生)。
运维时主动检测、防御与处理模块的 Metaspace 消耗
模块发布不可避免地会带来 Metaspace 使用增长,此时我们需要考虑的是如何让模块发布给原本正常运行的基座带来的影响最小,即:拒绝安装会导致 Metaspace OOM 的模块,并自动化处理预期外的 Metaspace OOM。
我们从模块发布流程来看,模块发布有两个阶段:模块安装和模块挂流对外提供服务,这两个阶段都可能会引起 Metaspace 增长,因此需要关注模块安装前后和模块对外提供服务时 Metaspace 的使用率,当使用率超出设定阈值时在不同阶段做不同处理:
- 模块安装前:平台侧统计该模块每次安装对 Metaspace 的内存消耗,在安装前获取此时 JVM 的 Metaspace 使用情况,以此预估该模块本次安装后该机器的 Metaspace 使用率是否会超过阈值,如果超过阈值则拒绝该次发布,提示用户重启/替换该机器。将机器记录在重启列表中,后续重启。
- 模块安装后:平台侧计算此时 Metaspace 内存使用率,如果超过阈值则机器记录在重启列表中,后续重启。
- 模块挂流对外提供服务一定时长后:平台侧计算此时 Metaspace 使用率,如果超过阈值则卡住发布单,由用户决定是否需要重启或替换该机器。
那么怎么定义 Metaspace 使用率更合理呢?
如何定义 Metaspace 的使用率?
在 Koupleless 中使用内存分配比例(commited / MaxMetaspaceSize)作为使用率,而不是实际使用比例(used / MaxMetaspaceSize)。
在一般情况下,应用会把 Metaspace 的实际使用比例作为 Metaspace 的使用率,当使用率超出设定阈值时做一些处理避免 Metaspace OOM。但在一些特殊场景下仍会出现 Metaspace 使用率低但还是 Metaspace OOM 的情况,如:上万个不同 ClassLoader 只加载了一个类。举个例子,开发者使用 fastjson 在每次序列化时都 new ParserConfig(),使得每次序列化都会创建新 ClassLoader,该新 ClassLoader 只加载了被序列化的这个类,当有上万次序列化时,JVM 中会存在上万个不同 ClassLoader 只加载了一个类。
我们从 Metaspace 的内存分配及使用上来看该情况的成因:Metaspace 已分配的空间与实际使用的空间大小不同,如果实际使用空间较少,但已分配的空间已达到上限,Metaspace 也会 OOM。Metaspace 每次给 ClassLoader 分配内存时的基本单位是 Chunk(1K、4K、64K等),一个 Chunk 只能被一个 ClassLoader 独享,而一个 ClassLoader 能占用多个 Chunk。那么如果一个 Chunk 没有被该类加载器用完,且该类加载器不再加载新的类,那么剩余空间就被浪费掉了。比如:Metaspace 给某类加载器只分配少量 Chunk(共 6 KB),该类加载器只加载一个类使用 3 KB,那么另外 3KB 就被浪费了;当 JVM 配置了 MaxMetaspaceSize 为 128 MB,在运行时创建了 20000 个这种类加载器,共分配了 120MB 内存,虽然 Metaspace 使用率只有 50%,但已经不断触发 Metaspace OOM 了,如下图所示:

因此需要使用 Metaspace 内存分配比例作为使用率。
运行时持续观测与自动处理 Metaspace 消耗
运行时框架 sdk 里会以时间窗口主动获取 Metaspace 的内存分配比例(Commited / MaxMetaspaceSize)作为使用率,上报至平台侧。如果线上机器长时间超过阈值,可以通过短信或其他方式告知到用户;如果线下机器一段时间内超出阈值,则平台侧主动在触发定时重启。
在蚂蚁集团内部,Koupleless 使用该方式在应用的研发、运维和运行的全链路上做了 Metaspace 的防御、检测和恢复,机器在达到 Metaspace 上限前基本通过主动和被动的自愈重启方式完成 Metaspace 清理,有效地防止模块安装数量与次数上限带来的影响。
总结与展望
我们当前通过检测、防御和自动恢复等方式,基本解决了模块数量上限的影响。但这里可能会有人提出新的问题:“模块的资源消耗是否可以强隔离?如果模块的资源消耗是强制隔离的,是不是也就没有 Metaspace 消耗的上限问题呢?”
实际上资源的强制隔离是可以避免 Metaspace 的消耗上限带来的 fullgc 问题,但资源的强隔离会导致模块无法复用基座的内存,导致模块资源的占用量变大,使得一个机器上能安装的模块或者安装次数只能在 10 个左右,带来的数量的下降是非常明显的。从实际出发,是否需要资源的强隔离,需要综合考虑成本和获得的收益:
资源强隔离成本
- 用户编程界面有侵入,参考 alijdk 的多租户隔离文档
- 目前没有成熟的同进程的隔离方案。如果使用进程隔离,那么也完全背离了模块化的初衷。
资源强隔离收益
- 资源的可靠性保障:在公有云情况下,资源的强隔离可以避免部分恶意用户的模块资源过大抢占其他模块的资源,但在私有企业内部极少会发生恶意抢占,该收益并不明显。
- 避免极端情况的模块数量上限带来的影响:该收益也不明显,因为这些极端情况也可以通过检测和自动恢复解决。
综合考虑资源的强隔离成本明显大于收益,目前也没有成熟的实现方案,带来的收益也不明显,所以对于当前这类问题做好配到的检测和自动恢复手段即可,可以不必作为企业内部是否采用模块化技术的评判标准。未来随着技术的不断发展,我们也一定会与整个社区和行业共同努力,持续探讨新的隔离与共享技术,在确保获得共享的收益情况下,解决掉当前共享带来的这些问题,让模块化的技术能给更多的业务带来收益。
Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
本篇文章属于 Koupleless 进阶系列文章第五篇,默认读者对 Koupleless 的基础概念、能力都已经了解,如果还未了解过的可以查看官网。
进阶系列一:Koupleless 模块化的优势与挑战,我们是如何应对挑战的
进阶系列二: Koupleless 内核系列 | 单进程多应用如何解决兼容问题
进阶系列三:Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
进阶系列四:Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
进阶系列五:Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
在往期文章中,我们已经介绍了 Koupleless 的收益、挑战、应对方式及存量应用的改造成本,帮助大家了解到 Koupleless 是如何低成本地给业务研发带来效率提升和资源下降的。在实践中,开发者将多个 Koupleless 模块部署在同一个基座上,从而降低资源成本。那么,如何在一个基座上安装更多的模块呢?
通常来说,有三种方式:模块复用基座的类、模块复用基座的对象、以及模块卸载时清理资源。其中,最简单、最直接、最有效的方式是让模块复用基座的类,即:模块瘦身。接下来,我们将介绍模块瘦身。
模块瘦身是什么?所谓模块瘦身,就是让模块复用基座所有依赖的类,模块打包构建时移除基座已经有的 Jar 依赖,从而让基座中可以安装更多的模块。
在最初的模块瘦身实践中,模块开发者需要感知基座有哪些依赖,在开发时尽量使用这些依赖,从而复用基座依赖里的类。其次,开发者需要根据基座所有依赖,判断可以移除哪些依赖,手工移除依赖。在移除依赖后,还可能会出现以下场景:
- 由于开发者误判,移除了基座没有的依赖,导致模块编译正常通过,而运行期出现 ClassNotFound、LinkageError 等错误;
- 由于模块依赖的版本和基座不同,导致模块编译正常通过,而运行期出现依赖版本不兼容的错误。
由此,引申出 3 个关键问题:
- 模块怎么感知基座运行时的所有依赖,从而确定需要移除的依赖?
- 怎么简单地移除依赖,降低普通应用和模块相互转换的改造成本?
- 怎么保证在移除模块依赖后,模块编译时和模块运行在基座中的依赖是一样的?
本篇文章将介绍模块瘦身原理、原则及关键问题的解决方式。
模块瘦身原理
Koupleless 底层借助 SOFAArk 框架,实现了模块之间、模块和基座之间的类隔离。模块启动时会初始化各种对象,会优先使用模块的类加载器去加载构建产物 FatJar 中的 class、resource 和 Jar 包,找不到的类会委托基座的类加载器去查找。

基于这套类委托的加载机制,让基座和模块共用的 class、resource 和 Jar 包通通下沉到基座中,可以让模块构建产物非常小,从而模块消耗的 Metaspace 非常少,基座上能安装的模块数量也更多,启动也能非常快。
其次,模块启动后 Spring 上下文中会创建很多对象,如果启用了模块热卸载,可能无法完全回收,安装次数过多会造成 Old 区、Metaspace 区开销大,触发频繁 FullGC,所以需要控制单模块包大小 < 5MB。这样不替换或重启基座也能热部署热卸载数百次。
在模块瘦身后,能实现以下两个好处:
- 允许基座安装更多的模块数量,从而在合并部署场景下,降低更多的资源成本;在热部署热卸载场景下,不替换或重启基座也能热部署、热卸载模块更多次
- 提高模块安装的速度,减少模块包大小,减少启动依赖,控制模块安装耗时 < 30秒,甚至 < 5秒
模块瘦身原则
由上文模块瘦身原理可知,模块移除的依赖必须在基座中存在,否则模块会在运行期间出现 ClassNotFound、LinkageError 等错误。
因此,模块瘦身的原则是,在保证模块功能的前提下,将框架、中间件等通用的依赖包尽量放置到基座中,模块中复用基座的依赖,这样打出的模块包会更加轻量。如图:

可感知的基座运行时
在基座和模块协作紧密的情况下,模块应该在开发时就感知基座正使用的所有依赖,并按需引入需要的依赖,而无需指定版本。为此,我们提供了“基座-dependencies-starter”的打包功能,该包在
<build>
<plugins>
<plugin>
<groupId>com.alipay.sofa.koupleless</groupId>
<artifactId>koupleless-base-build-plugin</artifactId>
<configuration>
<!-- ... -->
<!--生成 starter 的 artifactId(groupId和基座一致),这里需要修改!!-->
<dependencyArtifactId>${baseAppName}-dependencies-starter</dependencyArtifactId>
<!--生成jar的版本号-->
<dependencyVersion>0.0.1-SNAPSHOT</dependencyVersion>
</configuration>
</plugin>
</plugins>
</build>
执行 mvn 命令,即可:
mvn com.alipay.sofa.koupleless:koupleless-base-build-plugin::packageDependency -f ${基座 bootstrap pom 对于基座根目录的相对路径}
然后,模块配置项目的 parent 为 “基座-dependencies-starter”。
<parent>
<groupId>com.alipay</groupId>
<artifactId>${baseAppName}-dependencies-starter</artifactId>
<version>0.0.1</version>
</parent>
以此,在模块的开发过程中,开发者能感知到基座运行时的所有依赖。
低成本的模块瘦身
在应用中,最简单的移除依赖的方式是把依赖的 scope 设置为 provided,但这种方式会增加普通应用转换为模块的成本。这种方式也意味着,如果模块要转为普通应用,需要将这些依赖配置回 compile,改造成本较高。
为了降低模块瘦身的成本,我们提供了两种配置模块瘦身的方式:基于“基座-dependencies-starter”自动瘦身和基于配置文件瘦身。
- 基于“基座-dependencies-starter”自动瘦身
我们提供了基于“基座-dependencies-starter” 的自动瘦身,自动排除和基座相同的依赖(GAV 都相同),保留和基座不同的依赖。配置十分简单,在模块的打包插件中配置 baseDependencyParentIdentity 标识即可:
<build>
<plugins>
<plugin>
<groupId>com.alipay.sofa</groupId>
<artifactId>sofa-ark-maven-plugin</artifactId>
<configuration>
<!-- ... -->
<!-- 配置 “基座-dependencies-starter” 的标识,规范为:'${groupId}:${artifactId}' -->
<baseDependencyParentIdentity>${groupId}:${baseAppName}-dependencies-starter</baseDependencyParentIdentity>
</configuration>
</plugin>
</plugins>
</build>
- 基于配置文件瘦身
在配置文件中,模块开发者可以主动配置需要排除哪些依赖,保留哪些依赖。
为了进一步降低配置成本,用户仅需配置需要排除的顶层依赖,打包插件会将该顶层依赖的所有间接依赖都排除,而无需手动配置所有的间接依赖。如:
# excludes config ${groupId}:{artifactId}:{version}, split by ','
excludes=org.apache.commons:commons-lang3,commons-beanutils:commons-beanutils
# excludeGroupIds config ${groupId}, split by ','
excludeGroupIds=org.springframework
# excludeArtifactIds config ${artifactId}, split by ','
excludeArtifactIds=sofa-ark-spi
保证瘦身的正确性
如果基座运行时没有模块被排除的依赖,或者基座运行时中提供的依赖版本和模块预期不一致,那么模块运行过程中可能会报错。为了保证瘦身的正确性,我们需要在模块编译和发布的环节做检查。
在模块编译时,模块打包插件会检查被瘦身的依赖是否在“基座-dependencies-starter”中,并在控制台输出检查结果,但检查结果不影响模块的构建结果。同时,插件允许更严格的检查:配置一定参数,如果基座中不存在模块被排除的依赖,那么模块构建失败,直接报错。
在模块发布时,在发布流程中拉取基座的运行时依赖,检查是否和 “基座-dependencies-starter” 一致。如果不一致,那么卡住发布流程,开发者可根据情况去升级模块的 “基座-dependencies-starter” 或跳过该卡点。
模块瘦身效果
以某个模块为例(该模块依赖了 16 个中间件),将模块的 parent 配置为 “基座-dependencies-starter”自动瘦身,下表是瘦身前后的 ark-biz.jar 大小和 Metaspace 占用的对比:
| 瘦身前 | 瘦身后 | 瘦身后/瘦身前 | |
|---|---|---|---|
| ark-biz.jar 大小 | 133 MB | 24 KB | 0.02% |
| Metaspace 占用 | 84352 KB | 6400 KB | 7.5% |
总结
通过上文相信大家已经了解,我们可以通过简单的配置,让模块打包更小,从而在一个基座上安装更多的 Koupleless 模块,降低更多的资源成本。
最后,再次欢迎大家使用和参与 Koupleless,我们期待您宝贵的意见!
Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
本篇文章属于 Koupleless 进阶系列文章第四篇,默认读者对 Koupleless 的基础概念、能力都已经了解,如果还未了解过的可以查看官网。
进阶系列一:Koupleless 模块化的优势与挑战,我们是如何应对挑战的
进阶系列二: Koupleless 内核系列 | 单进程多应用如何解决兼容问题
进阶系列三:Koupleless 内核系列 | 一台机器内 Koupleless 模块数量的极限在哪里?
进阶系列四:Koupleless 可演进架构的设计与实践|当我们谈降本时,我们谈些什么
进阶系列五:Koupleless 内核系列 |怎么在一个基座上安装更多的 Koupleless 模块?
引入|为什么写这篇文章
此前,我们已经介绍了 Koupleless 的收益、挑战以及应对方式,帮助大家了解到 Koupleless 是“如何”为业务研发带来效率提升和资源下降的,以及收益的比例会有多少。不过对于企业和开发者来说,这些收益终究还不是自己的,想要让这些收益成为自己的,还需要踏出第一步:动手试用和接入。这里涉及到的关键问题是:
- 代码接入成本是多少?存量应用是否可以使用?
- 发布到线上所需的平台能力是否需要重新建设?相关的基础设施是否需要适配?
这些问题是企业和开发者关心的问题,也是 Koupleless 能否顺利帮助更广泛的企业降本增效需要解决的关键问题。
本篇文章将详细介绍 Koupleless 为了降低接入成本做了哪些设计和考量,并引申出 Koupleless 另一个能力,也就是通过可演进式架构帮助存量应用低成本演进和享受到 Serverless 收益的解决方案。这里需要解决的这几个问题:
- 存量应用的低成本接入
- 企业模块化平台的低成本建设
- 应用架构的灵活切换
- 面向未来的 Serverless 平台
存量应用的低成本接入
存量应用要做到低成本接入,需要从研发框架着手,也就是模块化的定义与使用上出发。模块化在 Java 领域里由来已久,相比其他的模块化技术,Koupleless 模块化有哪些不同?为什么 Koupleless 的模块化技术可以规模化落地呢? 关键问题在于如何处理模块间的隔离和共享。
在 Java 领域的各类模块化技术里,有 OSGI/JPMS/Spring Modulith 等,
对于 JPMS 与 Spring Modulith,主要考虑业务逻辑和代码的隔离与管理,通过内置模块或者 inner package 来做逻辑隔离,该方式与传统应用开发习惯有较大不同,对开发者有较高学习成本,存量应用较难改造使用。
在 Koupleless 里,我们使用 Java 领域里用户最熟悉的 ClassLoader 隔离类和资源 和 Spring ApplicationContext 来做隔离对象,这和 OSGI 比较一致。
下面我们主要对比 Koupleless 模块(SOFAArk)与 OSGI 模块的不同,来说明 Koupleless 模块是如何做到低成本使用和规模化落地的。
| 隔离 | 共享 | ||
|---|---|---|---|
| 类与资源 | bean与服务 | 类与资源 | |
| JPMS | JVM 内置模块级别访问控制 | JVM 内置模块级别访问控制 | 定义模块间依赖关系,源模块与目标模块定义导入导出列表 |
| Spring Modulith | inner 的子 package,inner 内不允许外部模块访问,并通过 ArchUnit 的 verify 来做校验,未通过则构建失败。 | inner 包,通过单元测 verify 来校验 | 模块 API |
| OSGI | ClassLoader | Spring ApplicationContext | 定义模块间依赖关系,源模块与目标模块定义导入导出列表 |
| SOFAArk | ClassLoader | Spring ApplicationContext | 源模块默认委托给基座(pom 依赖 scope 设置成 provided) |
Koupleless 模块 vs OSGI 模块
Koupleless 模块与 OSGI 模块的不同,主要体现在模块间如何完成通信和共享。OSGI 的模块要进行共享和通信,package 需要在每个模块指定 import 和 export,服务需要编写代码定义 Activator 使用 BundleContext.registerService 进行注册,示例如下:
// 类导出,定义在 MANI
Export-Package: com.example.mypackage, com.example.anotherpackage
// 服务导出
MyService myService = new MyServiceImpl();
context.registerService(MyService.class.getName(), myService, null);
// 类导入
Import-Package: com.example.mypackage, com.example.anotherpackage
// 服务导入
MyService myService = new MyServiceImpl();
context.registerService(MyService.class.getName(), myService, null);
这就带来了较大的配置和使用成本。
而 Koupleless 模块化设计虽然借鉴了 OSGI 的设计,却也简化了这一模块共享和通信的使用方式。
1⃣️免配置的类与资源共享方式
- OSGI 模块角色都是对等的,在这一点上 Koupleless 与之不同。Koupleless 对模块做了区分,定义了两种不同角色:模块与基座(基座背后也是一个模块)。

在类和资源共享的时候,默认从各自模块自身查找。如果查找到则直接返回;如果查找不到,只要模块 pom 里引入过的类就会默认从基座查找。所以模块里并不需要定义类和资源的导入导出配置,只要定义哪些由自己加载,哪些委托给基座加载即可。


而定义由自己加载的方式只要模块的 pom 里 compile 引入对应依赖即可;要委托给基座的,也只需要在配置文件里配置即可,如下配置,详见模块瘦身。
excludes=org.apache.commons:commons-lang3,commons-beanutils:commons-beanutils
excludeGroupIds=org.springframework
excludeArtifactIds=sofa-ark-spi
2⃣️免配置的通信方式
与 OSGI 需要主动注册的方式不同,Koupleless 在 Dubbo 或者 SOFABoot 等框架里提供了跨模块间查找的能力,模块开发方式完全没有改动,需要使用其他可以直接使用等 @SOFAReference 注解获取其他模块里的对象。而在 SpringBoot 里,Koupleless 也提供了 @AutowiredFromBase @AutowiredFromBiz 来主动获取其他模块的对象。
3⃣️给业务自由
Koupleless 让业务模块来决定哪些类和资源或者对象需要从基座里获取,与 OSGI 相比,这里不需要双向的配置,只要业务模块主动“去拿”就可以。
凭借以上三点,可以让模块开发者像开发普通 SpringBoot 一样开发模块,让业务低成本的使用 Koupleless 模块化框架。当然这里并不是说 Koupleless 模块比 OSGI 模块更优秀,而是 Koupleless 模块根据特定的场景做了特定的简化,也随之带来了这样的效果。
当然除了上述的简化外,Koupleless 在研发侧还做了大量的工作,包括普通应用只需要引入 SDK 和构建插件低成本改造成基座或模块、低成本的模块瘦身方案、arkctl 的研发工具、生态组件的多应用低成本适配和使用等。
企业模块运维调度平台的低成本建设
🤔️直接的方案:在基座平台之上建设模块平台
在介绍运维调度的低成本方案前,我们需要先了解模块化的运维调度到底是在做什么。简单理解,就是在已有基座的情况下,在基座上分批安装模块。安装需要如下几个步骤:
- 假如基座有 100 台机器,需要获取基座的一个批次的机器(例如 10 台机器的 IP);
- 给这个批次的每台机器,逐个发送运维指令,包括模块名、模块 jar 包地址、运维类型等信息;
- 每台机器接收到指令后,解析指令,下载模块 jar 包并解压,然后通过模块里定义的 main 方法启动模块;
- 返回模块安装状态信息,批次安装结束;
- 开始新的批次,直到所有机器完成安装。
该过程需要选择基座机器并发送运维指令,然后根据状态判断安装成功与否,从而继续下批次运维。
实现这类运维过程比较直接的解决方式是,在基座平台之上建设模块平台。

再由模块平台负责:
- 管理模块版本、模块流量
- 选择待安装的机器
- 发送安装指令
- 维护模块状态
- ……
然而选择这种方式,企业除了需要建设完整的模块化运维调度平台及对应产品外,还需要适配多种基础设施平台,例如:
- 应用元数据管理平台:新增模块应用元数据
- 研发与迭代管理平台:增加模块创建、模块迭代、模块构建、发起模块发布
- 联调平台:增加模块与基座、模块与普通应用联调
- 可观测平台:监控与告警、trace 追踪、日志采集与查询
- 灰度平台
- 模块流量
这样的话,企业接入的成本是相当大的。为了降低生态企业建设成本,我们设计了与生态更融合的模块化平台建设方案。
✅降本的方案:复用原生 K8s 的模块化平台
为了尽可能降低模块化平台建设成本,我们进一步分析模块运维调度的过程:这个过程主要是“选择有资源空闲或者带升级机器然后执行指令”,也就是将模块 Jar 调度安装到 Pod 上的过程,这个过程实际与普通应用将 Pod 调度到 Node 上的运维调度过程非常类似。所以我们设计了基于 Virtual-Kubelet 的方案,将模块平台融入到 K8s 平台里。

将业务模块映射成 pod,将基座 pod 映射成 Node,这样就可以复用 K8s 的能力来运维调度模块。具体过程如下:
- 安装 Virtual-Kubelet,映射出 Virtual Node,Virtual Kubelet 将保持基座与 VNode 的状态同步:

- 安装模块,创建模块的 Deployment(即原生 K8s Deployment),此时 K8s ControllerManager 会创建出模块的 VPod(刚创建时还未调度到节点上,状态为 Pending):

- K8s Scheduler 发现 VPod 可以调度到 VNode 上,将 VPod 分配到 VNode 上:

- Virtual Kubelet 发现 VNode 上有 VPod 调度上来,发起模块安装指令到基座上:

- 安装成功后,保持模块与 VPod、基座 Pod 与 Node 间的状态同步:

- 同时可以使用 K8s Service 创建模块的独立流量单元:

这样模块的版本管理、安装发布、模块的流量都可以通过创建模块的 deployment 和 service 来完成。更进一步的,模块的发布平台也可以直接复用普通应用的 PaaS 平台来完成,只要创建或更新对应的模块 Deployment 即可。
可演进的应用架构
Koupleless 模块化实际上是在单体架构和微服务架构之间增加了模块化架构这个桥梁,并降低经由这个桥梁的改造成本,这是 Koupleless 可演进架构的关键设计。

模块架构在之前文章已有详细介绍,这里介绍下 Koupleless 如何降低其中演进过程的改造工作。
Koupleless 为了帮助应用从单体架构 <–> 模块架构 <–> 微服务架构平滑演进,提供了半自动化工具和最佳实践。例如
- 单体架构 <–> 模块架构:模块半自动拆分工具;基座与模块共库
- 模块架构 <–> 微服务架构:不改代码即可切换模块还是微服务部署模式,主要是在代码里同时引入 springboot fatjar 和 sofaArk biz jar 打包插件,然后根据发布方式不同选择镜像化部署还是模块化部署。
<build>
<plugins>
<plugin>
<groupId>com.alipay.sofa</groupId>
<artifactId>sofa-ark-maven-plugin</artifactId>
<version>${sofa.ark.version}</version>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
</plugin>
</plugins>
</build>
基于 Koupleless 的 Serverless 的能力
当前对于业务模块开发者来说,由于已经不需要感知机器,已经享受到了一些 Serverless 的收益。这种收益对于类似代码片段的中台模块来说更加明显,除了不感知机器外,还不需要引入、配置和初始化中间件等基础服务的使用方式,这些都由基座封装成 API 给模块使用。
在调度上,由于不同的机器上可以安装不同的模块,这样我们可以划分出不同机器组,例如日常机器组、高保机器组、buffer 机器组。模块 3 可以安装到高保机器组上,如果模块 3 流量增加,可以从 buffer 机器组里调度出机器直接安装模块,这样模块 3 的扩容即可秒级完成。

另外,模块也可以有自己的副本数,模块可以配置弹性伸缩规则、流量驱动等更多的 Serverless 能力。
总结
通过上文相信大家已经了解,存量应用从单体应用或者微服务应用可以低成本演进到模块应用,并利用模块化能力,演进出 Serverless 的能力。
不过当前 Koupleless 还没有开放出 Serverless 平台的能力,还需要和社区共同建设。希望未来有更多的伙伴加入,一起打造帮助存量应用低成本演进和享受到 Serverless 收益的可演进架构和解决方案。
恭喜 祁晓波 成为 Koupleless (原 SOFAServerless) 优秀 Contributor!

祁晓波 作为F6汽车科技基础设施负责人,主要研究微服务、可观测、稳定性、研发效能、java中间件等领域
自加入 Koupleless (原 SOFAServerless) 项目以来,他贡献了诸多框架与中间件在多模块模式下的最佳实践和治理方案,并从框架角度一起探讨如何以更标准化、可持续性的解决思路和方案,也贡献了 dubbo、apollo 等的 adapter 组件。
2023 年 12 月26日,Koupleless (原 SOFAServerless) 社区PMC之一 赵真灵 代表 Koupleless (原 SOFAServerless) 社区,宣布 祁晓波 @qixiaobo 通过投票,成为社区优秀 Contributor!
commits 记录/PR 贡献等:
https://github.com/sofastack/sofa-serverless/pulls?q=is%3Apr+is%3Aclosed+author%3Aqixiaobo

https://github.com/sofastack/sofa-ark/pulls?q=is%3Apr+is%3Aclosed+author%3Aqixiaobo
突出贡献:
扩展了 springboot 1.x 的支持,沉淀了10+类组件在落地多应用模式的最佳实践和治理方案,并深度参与如何从框架角度定义标准治理方案,完成了 dubbo 2.6 和 apollo 的 adapter 适配组件。
成员感想
很荣幸和 SOFA 一起为开源社区打造一款基于 spring/springboot/sofaboot 的 serverless 框架。目前越来越多的企业在支持海量微服务之后感受到了微服务对于架构复杂度的不友好,尤其是在成本支出这块。现在 ESG 在整个社会越发得到重视,国家也在大力发展绿色经济,无数人在为碳中和付出自己的努力。也特别有幸在这个环节可以为 java 生态添砖加瓦,期望可以更好的和社区合作共建。
社区同学寄语
感谢祁晓波一直以来为 Koupleless (原 SOFAServerless) 项目做出的巨大贡献!期待未来和晓波一起,让 Koupleless (原 SOFAServerless) 变得更好!
同时感谢各位对 Koupleless (原 SOFAServerless) 社区的贡献,也希望更多的小伙伴加入 Koupleless (原 SOFAServerless) 社区,共同助力开源环境的快速发展。
恭喜 颜文 成为 Koupleless 社区优秀 Contributor!

颜文 作为政采云大客定制团队业务架构师,主要负责对大型客户业务的开发模式优化和研发效能提升。自了解到 Koupleless 的设计理念和实践效果以来,他积极参与 Koupleless 开源社区,并结合内部实践经验,为社区贡献了如下两大实用功能 MultiBizProperties、Koupleless-web-gateway,并得到社区的好评。2024 年 6 月 20 日,Koupleless 社区 PMC 之一 赵真灵 代表 Koupleless 社区,宣布 颜文 @巨鹿 通过投票,成为社区优秀 Contributor!
commits 记录/PR 贡献等:
https://github.com/koupleless/koupleless/pulls?q=is%3Apr+is%3Aclosed+author%3Aqq290584697

https://github.com/sofastack/sofa-serverless/pulls?q=is%3Apr+is%3Aclosed+author%3Aqq290584697
https://github.com/sofastack/sofa-ark/pulls?q=is%3Apr+author%3Aqq290584697+is%3Aclosed

突出贡献:
- MultiBizProperties:在 Java 里 System.Properties 是 JVM 级别的配置,在多应用合并在一起后可能会存在不同应用间 System Properties 互相干扰的问题,颜文 提出 MultiBizProperties 方案优雅且低成本的解决了多个应用合并一起后,为不同应用提供了互相隔离 System Properties 能力。

- Koupleless-web-gateway: 多个存量应用合并在一个进程后,由于复用一个 tomcat 的 host,需要在原来的web path 里增加一个 webContext Path 来区分不同的应用。但这会导致原来访问的地址发生改变,如 biz1.alipay.com/path/to/content 变成了 biz1.alipay.com/biz1/path/to/content,访问的路径发生了改变。这对于存量应用接入来说,是很大的一个变化,可能涉及到上游的调用路径配置。颜文 通过设计进程内的 web forward 能力,能让上游调用路径不变的情况下,把服务转发到对应的 biz 模块内,大大降低了存量应用合并部署的改造成本。

成员感想
很荣幸可以参与到koupleless的开发,这也是我参与的第一个开源项目。前期的时候,甚至连提交PR和提交ISSUE都需要询问,感谢项目成员不厌其烦的指导。在我看来,koupleless是对于微服务架构重大补充,且有望成长为java生态中,极具影响力的项目,期待着未来更多的参与,与koupleless共同成长。
社区同学寄语
感谢颜文一直以来为 Koupleless 项目做出的巨大贡献!期待未来和颜文一起,让 Koupleless 变得更好,帮助更多的企业降本增效、绿色计算!
同时感谢各位对 Koupleless 社区的贡献,也希望更多的小伙伴加入 Koupleless 社区,共同助力开源社区的快速发展。
蚂蚁中间件团队火热招聘中!
团队介绍
蚂蚁中间件平台技术是服务整个蚂蚁集团的核心技术团队,打造了世界领先的金融级分布式中间件技术和平台产品,是云原生领域的领先者。
蚂蚁中间件团队正在打造可服务蚂蚁所有在线应用的大规模流程编排和 Serverless 平台,当前已服务蚂蚁 90 万核在线业务,在国内名列前茅。与此同时,我们近期还开源了部分核心技术组件,让 30+ 外部企业成功实现了极致降本增效,欢迎查阅我们的开源版产品官网:https://koupleless.io/
岗位工作内容
在这个团队,你能学习到大规模中间件平台技术体系,工作内容包括流程编排平台、AI 智能体低代码平台、大规模秒级发布运维平台的开发与上线,能够作为主创人做出服务全球海量业务的中间件平台产品,还会在双十一、新春红包等大促中大放异彩,留下你的足迹与成就!
欢迎各位有意向的同行与我们联系~ 联系邮箱:ly109106@antfin.com