6. 参与社区
- 1: 6.1 开放包容理念
- 2: 6.2 交流渠道
- 3: 6.3 贡献社区
- 3.1: 6.3.1 本地开发测试
- 3.2: 6.3.2 完成第一次 PR 提交
- 3.3: 6.3.3 文档、Issue、流程贡献
- 3.4: 6.3.4 组织会议和运营布道
- 4: 6.4 社区角色与晋升
- 5: 6.5 技术原理
- 5.1: 6.5.1 SOFAArk 技术文档
- 5.2: 6.5.2 Arklet 技术文档
- 5.3: 6.5.3 多模块运行时适配或最佳实践
- 5.3.1: 6.5.3.1 Koupleless 多应用治理补丁治理
- 5.3.2: 6.5.3.2 Koupleless 三方包补丁指南
- 5.3.3: 6.5.3.2 多模块集成测试框架介绍
- 5.3.4: 6.5.3.3 dubbo2.7 的多模块化适配
- 5.3.5: 6.5.3.4 ehcache 的多模块化最佳实践
- 5.3.6: 6.5.3.5 logback 的多模块化适配
- 5.3.7: 6.5.3.6 log4j2 的多模块化适配
- 5.3.8: 6.5.3.7 模块使用宝蓝德 web 服务器
- 5.3.9: 6.5.3.8 模块使用东方通 web 服务器
- 5.3.10: 6.5.3.9 模块使用 Dubbo
- 5.3.11: 6.5.3.10 基座与模块间类委托加载原理介绍
- 5.3.12: 6.3.5.11 如果模块独立引入 SpringBoot 框架部分会怎样?
- 5.4: 6.5.4 模块拆分工具
- 6: 6.6 ModuleController 技术文档
1 - 6.1 开放包容理念
核心价值观
Koupleless 社区的核心价值观是 “开放” 和 “包容”。社区里所有的用户、开发者完全平等,体现在如下几个方面:
社区参考了 Apache 开源项目的运作方式,对社区做出任意贡献的同学,尤其是非代码贡献的同学(文档、官网、Issue 回复、运营布道、发展建议等),都是我们的 Contributor,都有机会成为社区的 Committer 甚至是 PMC(Project Management Committee)成员。
社区所有的 OKR、RoadMap、讨论、会议、技术方案等都是完全开放的,所有人都可以看见,并且都可以参与其中,社区会认证倾听、考虑大家的所有建议和意见,一旦采纳就会确保执行落地。希望大家带着无所顾虑、求同尊异的心态参与 Koupleless 社区。
社区不限地域国籍,所有源代码必须是英文注释确保大家都能理解,官网也是中英文双语。所有微信群、钉钉群、GitHub Issues 讨论都可以是中英双语。但由于当前我们主要聚焦在国内用户,因此大部分文档暂时只有中文版,未来会提供英文版。
2023 年 OKR
O1 打造社区健康、有行业影响力的 Serverless 开源产品
KR1 新增 10 个 Contributors,年底 OpenRank 指数 > 15(当前 5)、活跃度 > 50(当前 44)
KR1.1 完成 5 次布道和 5 次文章分享,触达 200 家企业,深度交流 30+ 企业。
KR1.2 形成完善的社区共建机制(包括 Issue 管理、文档、问题响应、培养与晋升机制),发布 2+ 培训课程与产品手册,共建开发者可在一周内上手,开发总吞吐率达到 20+ Issues/周。
KR2 新增 5 家企业在生产环境使用或完成试点接入(当前新增 1),3 家企业参与社区
KR2.1 产出初步行业分析报告,帮助定位适用不同场景的重点企业对象。
KR2.2 5 家企业生产真实使用或完成试点接入,3 家企业参与社区,覆盖 3 个场景并沉淀 3+ 用户案例。
O2 打造技术先进、效果显著的降本增效解决方案
KR1 落地模块化技术实现机器减少 30%、部署验证耗时降低至 30 秒、需求交付效率提升 50%
KR1.1 搭建 1 分钟快速试用平台,完善的文档、官网与配套支持,用户可在 10 分钟完成一个模块拆分。
KR1.2 完成 20 种中间件和三方包治理,同时形成多应用与热卸载评测和自动检测标准。
KR1.3 模块具备热部署启动耗时降低至 10 秒级,多模块具备合并部署资源减少 30%,同时让用户需求交付效率提升 50%。
KR1.4 落地开源版 Arklet,支持 SOFABoot 和 SpringBoot。提供运维管道、指标采集、模块生命周期管理、多模块运行环境、Bean 与服务发现及调用能力。
KR1.5 落地研发工具 ArkCtl,具备快速开发验证、灵活部署(合并与独立部署)、模块低成本拆分改造能力。
KR2 运维调度 1.0 版本上线。全链路高频端到端测试用例成功率 99.9%,自身端到端耗时 P90 < 500ms
KR2.1 上线基于 K8S Operator 的开源版运维调度能力,至少具备发布、回滚、下线、扩缩容、替换、副本保持、2+ 调度策略、模块流控、部署策略、对等和非对等运维能力。
KR2.2 建设开源版 CI 和 25+ 高频端到端测试用例,不断打磨并推动端到端 P90 耗时 < 500ms、所有预演成功率> 99.9%、单测覆盖率达到行 > 80% 分支 > 60%(通过率 100%)。
KR3 开源版自动伸缩初步上线,模块具备人工画像和分时伸缩能力
RoadMap
- 2023.08 完成 SOFABoot 完整的部署功能验证,产出兼容性 Benchmark 基线。
- 2023.09 发布基础运维和调度系统 ModuleController 0.5 版本。
- 2023.09 发布研发运维工具 Arkctl 与 Arklet 0.5 版本。
- 2023.09 官网和完整用户手册上线。
- 2023.10 新增 2+ 公司使用。
- 2023.11 支持 SpringBoot 完整能力和 5+ 社区常用中间件。
- 2023.11 Koupleless 0.8 版本上线(ModuleController、Arkctl、Arklet、SpringBoot 兼容)。
- 2023.12 Koupleless 0.9 版本上线(包括基础自动伸缩、模块基础拆分工具、20+ 中间件与三方包兼容)。
- 2023.12 新增 5+ 家公司真实使用,10+ Contributors 参与。
2 - 6.2 交流渠道
Koupleless 提供如下沟通交流渠道,欢迎加入我们一起分享、一起使用、一起收获:
Koupleless 社区交流与协作钉钉群:24970018417
如果您对 Koupleless 感兴趣、或者有初步意向使用 Koupleless、或者已经是 Koupleless / SOFAArk 的用户、或者有兴趣成为社区 Contributor,都可以加入该钉钉群和我们随时随地一起交流讨论、一起贡献代码。
Koupleless 用户微信群

如果您对 Koupleless 感兴趣、或者有初步意向使用 Koupleless、或者已经是 Koupleless / SOFAArk 的用户,都可以加入该微信群随时随地一起交流讨论。
社区双周会
每两周周二晚 19:30 - 20:30 会举办社区会议,欢迎大家积极参与旁听或讨论。社区钉钉会议入会方式:
入会链接:https://meeting.dingtalk.com/dialin/?corpId=dingd8e1123006514592
钉钉会议号:90957500367
电话呼入:057128095818 (中国大陆)、02162681677 (中国大陆)
具体会议时间也可关注社区钉钉协作群(群号:24970018417)。
双周会记录(有视频回放)
每个月底的周一会召开社区各组件 PMC 成员迭代规划会议,讨论并敲定下一个月需求规划。
3 - 6.3 贡献社区
3.1 - 6.3.1 本地开发测试
SOFAArk 和 Arklet
SOFAArk 是一个普通 Java SDK 项目,使用 Maven 作为依赖管理和构建工具,只需要本地安装 Maven 3.6 及以上版本即可正常开发代码和单元测试,无需其它的环境准备工作。
关于代码提交细节请参考:完成第一次 PR 提交。
ModuleController
ModuleController 是一个标准的 K8S Golang Operator 组件,里面包含了 ModuleDeployment Operator、ModuleReplicaSet Operator、Module Operator,在本地可以使用 minikube 做开发测试,具体请参考本地快速开始。
编译构建请在 module-controller 项目里执行:
go mod download # if compile module-controller first time
go build -a -o manager cmd/main.go
单元测试执行请在 module-controller 项目里执行:
make test
您也可以使用 IDE 进行编译构建、开发调试和单元测试执行。
module-controller 开发方式和标准 K8S Operator 开发方式完全一样,您可以参考 K8S Operator 开发官方文档。
Arkctl
Arkctl 是一个普通 Golang 项目,他是一个命令行工具集,包含了用户在本地开发和运维模块过程中的常用工具。 可参考此处
3.2 - 6.3.2 完成第一次 PR 提交
认领或提交 Issue
不论您是修复 bug、新增功能或者改进现有功能,在您提交代码之前,请在 Koupleless 或 SOFAArk GitHub 上认领一个 Issue 并将 Assignee 指定为自己(新人建议认领 good-first-issue 标签的新手任务)。或者提交一个新的 Issue,描述您要修复的问题或者要增加、改进的功能。这样做的好处是能避免与其他人的工作重复。
获取源码
要修改或新增功能,在提 Issue 或者领取现有 Issue 后,点击左上角的fork按钮,复制一份 Koupleless 或 SOFAArk 主干代码到您的代码仓库。
拉分支
Koupleless 和 SOFAArk 所有修改都在个人分支上进行,修改完后提交 pull request,当前在跑通 PR 流水线之后,会由相应组件的 PMC 或 Maintainer 负责 Review 与合并代码到主干(master)。因此,在 fork 源码后,您需要:
- 下载代码到本地,这一步您可以选择 git/https 方式:
git clone https://github.com/您的账号名/koupleless.git
git clone https://github.com/您的账号名/sofa-ark.git
- 拉分支准备修改代码:
git branch add_xxx_feature
执行完上述命令后,您的代码仓库就切换到相应分支了。执行如下命令可以看到您当前分支:
git branch -a
如果您想切换回主干,执行下面命令:
git checkout -b master
如果您想切换回分支,执行下面命令:
git checkout -b "branchName"
修改代码提交到本地
拉完分支后,就可以修改代码了。
修改代码注意事项
- 代码风格保持一致。Koupleless arklet 和 sofa-ark 通过 Maven 插件来保持代码格式一致,在提交代码前,务必先本地执行:
mvn clean compile
- 补充单元测试代码。
- 确保新修改通过所有单元测试。
- 如果是 bug 修复,应该提供新的单元测试来证明以前的代码存在 bug,而新的代码已经解决了这些 bug。对于 arklet 和 sofa-ark 您可以用如下命令运行所有测试:
mvn clean test
对于 module-controller 和 arkctl 项目,您可以用如下命令运行所有测试:
make test
也可以通过 IDE 来辅助运行。
其它注意事项
- 请保持您编辑的代码使用原有风格,尤其是空格换行等。
- 对于无用的注释,请直接删除。注释必须使用英文。
- 对逻辑和功能不容易被理解的地方添加注释。
- 务必第一时间更新 docs/content/zh-cn/ 目录中的 “docs”、“contribution-guidelines” 目录中的相关文档。
修改完代码后,执行如下命令提交所有修改到本地:
git commit -am '添加xx功能'
提交代码到远程仓库
在代码提交到本地后,就是与远程仓库同步代码了。执行如下命令提交本地修改到 github 上:
git push origin "branchname"
如果前面您是通过 fork 来做的,那么这里的 origin 是 push 到您的代码仓库,而不是 Koupleless 的代码仓库。
提交合并代码到主干的请求
在的代码提交到 GitHub 后,您就可以发送请求来把您改好的代码合入 Koupleless 或 SOFAArk 主干代码了。此时您需要进入您的 GitHub 上的对应仓库,按右上角的 pull request按钮。选择目标分支,一般就是 master,当前需要选择组件的 Maintainer 或 PMC 作为 Code Reviewer,如果 PR 流水线校验和 Code Review 都通过,您的代码就会合入主干成为 Koupleless 的一部分。
PR 流水线校验
PR 流水线校验包括:
- CLA 签署。第一次提交 PR 必须完成 CLA 协议的签署,如果打不开 CLA 签署页面请尝试使用代理。
- 自动为每个文件追加 Apache 2.0 License 声明和作者。
- 执行全部单元测试且必须全部通过。
- 检测覆盖率是否达到行覆盖 >= 80%,分支覆盖 >= 60%。
- 检测提交的代码是否存在安全漏洞。
- 检测提交的代码是否符合基本代码规范。
以上校验必须全部通过,PR 流水线才会通过并进入到 Code Review 环节。
Code Review
当您选择对应组件的 Maintainer 或 PMC 作为 Code Reviewer 数天后,仍然没有人对您的提交给予任何回复,可以在 PR 下面留言并 at 相关人员,或者在社区钉钉协作群中(钉钉群号:24970018417)直接 at 相关人员 Review 代码。对于 Code Review 的意见,Code Reviewer 会直接备注到到对应的 PR 或者 Issue 中,如果您觉得建议是合理的,也请您把这些建议更新到您的代码中并重新提交 PR。
合并代码到主干
在 PR 流水线校验和 Code Review 都通过后,就由 Koupleless 维护人员操作合入主干了,代码合并之后您会收到合并成功的提示。
3.3 - 6.3.3 文档、Issue、流程贡献
文档贡献
使用文档、技术文档、官网内容需要社区每一位 Contributor 共同维护,对任意文档和官网内容做出贡献的同学都是我们的 Contributor,并且根据活跃度有机会成为 Koupleless 组件的 Committer 甚至 PMC 成员,共同主导 Koupleless 的技术演进。
Issue 提交与回复贡献
任何使用过程中的问题、Bug、新功能、改进优化请创建 GitHub Issue,社区每天会有值班同学负责跟进 Issue。任何人提出或者回复 Issue 都是 Koupleless 的 Contributor,对回复 Issue 活跃的 Contributor 可以晋升为 Committer,如果特别活跃甚至可以晋升为 PMC 成员,共同主导 Koupleless 的技术演进。
Issue 模板
Koupleless(含 SOFAArk)Issue 有两种模板,一种是 “Question or Bug Report”,一种是 “Feature Request”。
Question or Bug Report
所有使用过程中遇到的问题或者疑似 Bug,请选择 “Question or Bug Report”,并提供详细的复现信息如下:
### Describe the question or bug
A clear and concise description of what the question or bug is.
### Expected behavior
A clear and concise description of what you expected to happen.
### Actual behavior
A clear and concise description of what actually happened.
### Steps to reproduce
Steps to reproduce the problem:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
### Screenshots
If applicable, add screenshots to help explain your problem.
### Minimal yet complete reproducer code (or GitHub URL to code)
### Environment
- SOFAArk version:
- JVM version (e.g. `java -version`):
- OS version (e.g. `uname -a`):
- Maven version:
- IDE version:
Feature Request
新功能、已有功能改进优化或者其它讨论,请选择 “Feature Request”。
流程贡献
Koupleless 当前制定了代码规约、PR 流程、CI 流水线、迭代管理、周会、交流渠道等各种协作规范,您可以对我们的协作规范和流程在 GitHub 上提出建议,即可成为我们的 Contributor。
3.4 - 6.3.4 组织会议和运营布道
我们鼓励大家宣传、布道 Koupleless,通过运营成为 Koupleless 的 Contributor、Committer 甚至 PMC,每一次 Contributor 的晋升,我们也会发放纪念品奖励。运营方式包括但不限于:
- 在线上或线下技术会议、Meetup 中发表 Koupleless 的使用或者技术实现相关演讲。
- 与其他企业分享交流 Koupleless 的使用场景等。
- 在各种渠道发表关于 Koupleless 的使用或者技术实现相关文章或视频。
- 其它运营方式。
4 - 6.4 社区角色与晋升
角色职责与晋升机制
Koupleless 社区角色参考了 Apache 开源产品组织方式,SOFAArk、Arklet、ModuleController、ArkCtl 每个组件都有各自的角色。每个组件的角色职责从低到高分别是:Contributor、Committer、PMC (Project Management Committee)、Maintainer。
| 角色 | 责任与权限 | 晋升到更高角色机制 |
|---|---|---|
| Contributor | 所有在社区提 Issue、回答 Issue、对外运营、提交文档内容或者提交任意代码的同学,都是相应组件的 Contributor。Contributor 拥有 Issue 提交、Issue 回复、官网或文档内容提交、代码提交(不包括代码评审)和对外发表文章权限。 | 当 Contributor 完成合并的代码或者文档内容足够多,就可以由该组件的 PMC 成员投票晋升为 Committer。当 Contributor 回答的 Issue 或者参与的运营活动足够多,也可以被 PMC 成员投票晋升为 Committer。 |
| Committer | 所有在社区积极回答 Issue、对外运营、提交文档内容或者提交代码的同学,按积极度都有可能被 PMC 成员投票晋升为 Committer。Committer 额外拥有代码评审、技术方案评审、Contributor 培养的责任与权限。 | 对长期积极投入或持续有突出贡献的 Committer,经 PMC 成员投票可以晋升为相应组件的 PMC 成员。 |
| PMC | 对相应组件持续贡献且特别活跃的同学有机会晋升为 PMC 成员。PMC 成员额外拥有组件的 RoadMap 制定、技术方案和代码评审、Issue 和迭代管理、Contributor 和 Committer 培养等责任与权限。 | |
| Maintainer | Maintainer 额外拥有密钥管理和仓库管理等管理员权限,除此之外在其他方面和 PMC 成员的责任与权限是完全对等的。 |
社区角色成员名单
SOFAArk
Maintainer
yuanyuancin
lvjing2
PMC (Project Management Comittee)
glmapper
Committer
zjulbj5
gaosaroma
QilongZhang133
straybirdzls13
caojie0911
Contributor
lylingzhen10
khotyn
FlyAbner (260+ 行提交,提名 Comitter?)
alaneuler
sususama
ujjboy
JoeKerouac
Lunarscave
HzjNeverStop
AiWu4Damon
vchangpengfei
HuangDayu
shenchao45
DalianRollingKing
nobodyiam
lanicc
azhsmesos
wuqian0808
KangZhiDong
suntao4019
huangyunbin
jiangyunpeng
michalyao
rootsongjc
Zwl0113
tofdragon
lishiguang4
hionwi
343585776
g-stream
zkitcast
davidzj
zyclove
WindSearcher
lovejin52022
smalljunHw
vchangpengfei
sq1015
xwh1108
yuanChina
blysin
yuwenkai666
hadoop835
gitYupan
thirdparty-core
Estom
jijuanwang
DCLe-DA
linkoog
springcoco
zhaowwwjian
xingcici
ixufeng
jnan806
lizhi12q
kongqq
wangxiaotao00
由于篇幅有限,23 年之前提交 Issue 的 Contributor 不在此一一列举,也同样感谢大家对 SOFAArk 的使用和咨询
Arklet
Maintainer
yuanyuancin
lvjing2
PMC (Project Management Committee)
TomorJM
Committer
暂无
Contributor
glmapper
Lunarscave
lylingzhen
ModuleController
Maintainer
CodeNoobKing
PMC (Project Management Committee)
暂无
Committer
暂无
Contributor
liu-657667
Charlie17Li
lylingzhen
Arkctl
Maintainer
yuanyuancin
lvjing2
PMC (Project Management Committee)
暂无
Committer
暂无
Contributor
暂无
5 - 6.5 技术原理
5.1 - 6.5.1 SOFAArk 技术文档
SOFAArk 2.0 介绍
Ark 容器启动流程
Ark 容器插件机制
Ark 容器类加载机制
打包插件源码解析
启动过程源码解析
动态热部署源码解析
类委托加载源码解析
多 Web 应用合并部署源码解析
5.2 - 6.5.2 Arklet 技术文档
Overview
概述
Arklet 提供了 SOFAArk 基座和模块的运维接口,通过 Arklet 可以轻松灵活的进行 Ark Biz 的发布和运维。
Arklet 内部由 ArkletComponent 构成
- ApiClient: The core components responsible for interacting with the outside world
- ApiClient: 负责与外界交互的核心组件
- CommandService: Arklet 暴露能力指令定义和扩展
- OperationService: Ark Biz 与 SOFAArk 交互,增删改查,封装基础能力
- HealthService: 基于基座、模块系统等指标统计健康和稳定性
这些组件之间的关联关系如下图

当然,您也可以通过实现 ArkletComponent 接口来扩展 Arklet 的组件功能。
Command Extension
指令扩展
Arklet 通过外部暴露指令 API,通过每个 API 映射的 CommandHandler 内部处理指令。
CommandHandler 相关扩展属于 CommandService 组件统一管理
你可以通过继承 AbstractCommandHandler 来自定义扩展指令
内置指令 API
下面所有的指令 API 都是通过 POST(application/json) 请求格式访问 arklet
使用的是 http 协议,1238 端口
你可以通过设置
koupleless.arklet.http.portJVM 启动参数覆盖默认端口
查询支持的指令
- URL: 127.0.0.1:1238/help
- input sample:
{}
- output sample:
{
"code":"SUCCESS",
"data":[
{
"desc":"query all ark biz(including master biz)",
"id":"queryAllBiz"
},
{
"desc":"list all supported commands",
"id":"help"
},
{
"desc":"uninstall one ark biz",
"id":"uninstallBiz"
},
{
"desc":"switch one ark biz",
"id":"switchBiz"
},
{
"desc":"install one ark biz",
"id":"installBiz"
}
]
}
安装一个模块
- URL: 127.0.0.1:1238/installBiz
- 输入例子:
{
"bizName": "test",
"bizVersion": "1.0.0",
// local path should start with file://, alse support remote url which can be downloaded
"bizUrl": "file:///Users/jaimezhang/workspace/github/sofa-ark-dynamic-guides/dynamic-provider/target/dynamic-provider-1.0.0-ark-biz.jar"
}
- 输出例子(success):
{
"code":"SUCCESS",
"data":{
"bizInfos":[
{
"bizName":"dynamic-provider",
"bizState":"ACTIVATED",
"bizVersion":"1.0.0",
"declaredMode":true,
"identity":"dynamic-provider:1.0.0",
"mainClass":"io.sofastack.dynamic.provider.ProviderApplication",
"priority":100,
"webContextPath":"provider"
}
],
"code":"SUCCESS",
"message":"Install Biz: dynamic-provider:1.0.0 success, cost: 1092 ms, started at: 16:07:47,769"
}
}
- 输出例子(failed):
{
"code":"FAILED",
"data":{
"code":"REPEAT_BIZ",
"message":"Biz: dynamic-provider:1.0.0 has been installed or registered."
}
}
卸载一个模块
- URL: 127.0.0.1:1238/uninstallBiz
- 输入例子:
{
"bizName":"dynamic-provider",
"bizVersion":"1.0.0"
}
- 输出例子(success):
{
"code":"SUCCESS"
}
- 输出例子(failed):
{
"code":"FAILED",
"data":{
"code":"NOT_FOUND_BIZ",
"message":"Uninstall biz: test:1.0.0 not found."
}
}
切换一个模块
- URL: 127.0.0.1:1238/switchBiz
- 输入例子:
{
"bizName":"dynamic-provider",
"bizVersion":"1.0.0"
}
- 输出例子:
{
"code":"SUCCESS"
}
查询所有模块
- URL: 127.0.0.1:1238/queryAllBiz
- 输入例子:
{}
- 输出例子:
{
"code":"SUCCESS",
"data":[
{
"bizName":"dynamic-provider",
"bizState":"ACTIVATED",
"bizVersion":"1.0.0",
"mainClass":"io.sofastack.dynamic.provider.ProviderApplication",
"webContextPath":"provider"
},
{
"bizName":"stock-mng",
"bizState":"ACTIVATED",
"bizVersion":"1.0.0",
"mainClass":"embed main",
"webContextPath":"/"
}
]
}
查询健康与状态信息
- URL: 127.0.0.1:1238/health
查询所有健康与状态信息
- 输入信息:
{}
- 输出信息:
{
"code": "SUCCESS",
"data": {
"healthData": {
"jvm": {
"max non heap memory(M)": -9.5367431640625E-7,
"java version": "1.8.0_331",
"max memory(M)": 885.5,
"max heap memory(M)": 885.5,
"used heap memory(M)": 137.14127349853516,
"used non heap memory(M)": 62.54662322998047,
"loaded class count": 10063,
"init non heap memory(M)": 2.4375,
"total memory(M)": 174.5,
"free memory(M)": 37.358726501464844,
"unload class count": 0,
"total class count": 10063,
"committed heap memory(M)": 174.5,
"java home": "****\\jre",
"init heap memory(M)": 64.0,
"committed non heap memory(M)": 66.203125,
"run time(s)": 34.432
},
"cpu": {
"count": 4,
"total used (%)": 131749.0,
"type": "****",
"user used (%)": 9.926451054656962,
"free (%)": 81.46475495070172,
"system used (%)": 6.249762806548817
},
"masterBizInfo": {
"webContextPath": "/",
"bizName": "bookstore-manager",
"bizState": "ACTIVATED",
"bizVersion": "1.0.0"
},
"pluginListInfo": [
{
"artifactId": "web-ark-plugin",
"groupId": "com.alipay.sofa",
"pluginActivator": "com.alipay.sofa.ark.web.embed.WebPluginActivator",
"pluginName": "web-ark-plugin",
"pluginUrl": "file:/****/2.2.3-SNAPSHOT/web-ark-plugin-2.2.3-20230901.090402-2.jar!/",
"pluginVersion": "2.2.3-SNAPSHOT"
},
{
"artifactId": "runtime-sofa-boot-plugin",
"groupId": "com.alipay.sofa",
"pluginActivator": "com.alipay.sofa.runtime.ark.plugin.SofaRuntimeActivator",
"pluginName": "runtime-sofa-boot-plugin",
"pluginUrl": "file:/****/runtime-sofa-boot-plugin-3.11.0.jar!/",
"pluginVersion": "3.11.0"
}
],
"masterBizHealth": {
"readinessState": "ACCEPTING_TRAFFIC"
},
"bizListInfo": [
{
"bizName": "bookstore-manager",
"bizState": "ACTIVATED",
"bizVersion": "1.0.0",
"webContextPath": "/"
}
]
}
}
}
查询系统健康与状态信息
- 输入例子:
{
"type": "system",
// [OPTIONAL] if metrics is null -> query all system health info
"metrics": ["cpu", "jvm"]
}
- 输出例子:
{
"code": "SUCCESS",
"data": {
"healthData": {
"jvm": {...},
"cpu": {...},
// "masterBizHealth": {...}
}
}
}
查询模块健康与状态信息
- 输入例子:
{
"type": "biz",
// [OPTIONAL] if moduleName is null and moduleVersion is null -> query all biz
"moduleName": "bookstore-manager",
// [OPTIONAL] if moduleVersion is null -> query all biz named moduleName
"moduleVersion": "1.0.0"
}
- 输出例子:
{
"code": "SUCCESS",
"data": {
"healthData": {
"bizInfo": {
"bizName": "bookstore-manager",
"bizState": "ACTIVATED",
"bizVersion": "1.0.0",
"webContextPath": "/"
}
// "bizListInfo": [
// {
// "bizName": "bookstore-manager",
// "bizState": "ACTIVATED",
// "bizVersion": "1.0.0",
// "webContextPath": "/"
// }
// ]
}
}
}
查询插件健康与状态信息
- 输入例子:
{
"type": "plugin",
// [OPTIONAL] if moduleName is null -> query all biz
"moduleName": "web-ark-plugin"
}
- 输出例子:
{
"code": "SUCCESS",
"data": {
"healthData": {
"pluginListInfo": [
{
"artifactId": "web-ark-plugin",
"groupId": "com.alipay.sofa",
"pluginActivator": "com.alipay.sofa.ark.web.embed.WebPluginActivator",
"pluginName": "web-ark-plugin",
"pluginUrl": "file:/****/web-ark-plugin-2.2.3-20230901.090402-2.jar!/",
"pluginVersion": "2.2.3-SNAPSHOT"
}
]
}
}
}
使用 Endpoint 来查询健康信息
使用 endpoint 来查询 k8s 模块的健康信息
** 默认配置 **
- endpoints path:
/ - endpoints 服务端口:
8080
** http 结果码 **
HEALTHY(200): 所有健康指标都健康UNHEALTHY(400): 至少有一个健康指标已经不健康ENDPOINT_NOT_FOUND(404): 路径或参数不存在ENDPOINT_PROCESS_INTERNAL_ERROR(500): 遇到异常
查询所有健康信息
- url: 127.0.0.1:8080/arkletHealth
- method: GET
- 输出例子
{
"healthy": true,
"code": 200,
"codeType": "HEALTHY",
"data": {
"jvm": {...},
"masterBizHealth": {...},
"cpu": {...},
"masterBizInfo": {...},
"bizListInfo": [...],
"pluginListInfo": [...]
}
}
查询所有模块的健康信息
- url: 127.0.0.1:8080/arkletHealth/{moduleType} (moduleType must in [‘biz’, ‘plugin’])
- method: GET
- 输出例子
{
"healthy": true,
"code": 200,
"codeType": "HEALTHY",
"data": {
"bizListInfo": [...],
// "pluginListInfo": [...]
}
}
查询单个模块的健康信息
- url: 127.0.0.1:8080/arkletHealth/{moduleType}/moduleName/moduleVersion (moduleType must in [‘biz’, ‘plugin’])
- method: GET
- 输出例子
{
"healthy": true,
"code": 200,
"codeType": "HEALTHY",
"data": {
"bizInfo": {...},
// "pluginInfo": {...}
}
}
5.3 - 6.5.3 多模块运行时适配或最佳实践
5.3.1 - 6.5.3.1 Koupleless 多应用治理补丁治理
Koupleless 为什么需要多应用治理补丁?
Koupleless 是一种多应用的架构,而传统的中间件可能只考虑了一个应用的场景,故在一些行为上无法兼容多应用共存的行为,会发生共享变量污染、classLoader 加载异常、class 判断不符合预期等问题。 由此,在使用 Koupleless 中间件时,我们需要对一些潜在的问题做补丁,覆盖掉原有中间件的实现,使开源的中间件也能兼容多应用的模式。
Koupleless 多应用治理补丁方案调研
在多应用兼容性治理中,我们不仅仅只考虑生产部署,还要考虑用户本地开发的兼容性(IDEA 点击 Debug),单测编写的兼容性(如 @SpringbootTest)等等。
下面是不同方案的对比表格。
方案对比
| 方案名 | 接入成本 | 可维护性 | 部署兼容性 | IDE 兼容性 | 单测兼容性 |
|---|---|---|---|---|---|
| A:将补丁包的依赖放在 maven dependency 的首部,以此保证补丁类能优先被 classLoader 加载。 | 低。 用户只需要控制 maven 家在的顺序。 | 低 用户需要严格保证相关依赖在最前面,且启动的时候不手动传入 classpath。 | 兼容✅ | 兼容✅ | 兼容✅ |
| B:通过 maven 插件修改 springboot 构建产物的索引文件的顺序。 | 低。 只需要新增一个 package 周期的 maven 插件即可,用户感知低。 | 中 用户需要保证启动的时候不手动传入 classpath。 | 兼容✅ | 不兼容❌ jetbrains 无法兼容,jetbrains 会自己构建 cli 命令行把 classpath 按照 maven 依赖的顺序传进去,这会导致 adapter 的顺序加载不一定是最优先的。 | 不兼容❌ 单测不走 repackage 周期,不依赖 classpath.idx 文件。 |
| C:新增自定义的 springboot 的 jarlaunch 启动器,通过启动器控制 classLoader 加载的行为。 | 高。 需要用户修改自己的基座启动逻辑,使用 Koupleless 自定义的 jarlaunch。 | 高 自定义的 jarlaunch 可以通过钩子控制代码的加载顺序。 | 兼容✅ | 兼容✅ 但需要配置 IDE 使用自定义的 jarlaunch。 | 不兼容❌ 因为单测不会走 jarlaunch 逻辑。 |
| D:增强基座的 classloader, 保证优先搜索和加载补丁类。 | 高。 用户需要初始化增强的代码,且该模式对 sofa-ark 识别 master biz 的逻辑也有侵入,需要改造支持。 | 高 基座的 classloader 可以编程化地控制依赖加载的顺序。 | 兼容✅ | 兼容✅ | 兼容✅ |
| E:通过 maven 插件配置配置拷贝补丁类代码到当前项目中, 当前项目的文件会被优先加载。 | 高。 maven 目前的拷贝插件无法用通配符,所以接入一个 adapter 就得多一个配置。 | 高 用户只要配置了,就可以保证依赖有限被加载(因为本地项目的类最优先被加载)。 | 兼容✅ | 兼容✅ | 不兼容❌ 因为单测不会走到 package 周期,而 maven 的拷贝插件是在 package 周期生效的。 |
结论
综合地来看,没有办法完全做到用户 0 感知接入,每个方法都需要微小程度的业务改造。 在诸多方案中,A 和 D 能做到完全兼容,不过 A 方案不需要业务改代码,也不会侵入运行时逻辑,仅需要用户在 maven dependency 的第一行中加入如下依赖:
<dependency>
<groupId>com.alipay.sofa.koupleless</groupId>
<artifactId>koupleless-base-starter</artifactId>
<version>${koupleless.runtime.version}</version>
<type>pom</type>
</dependency>
故我们将采取方案 A。
如果你有更多的想法,或输入,欢迎开源社区讨论!
5.3.2 - 6.5.3.2 Koupleless 三方包补丁指南
Koupleless 三方包补丁原理
Koupleless 是一种多应用的架构,而传统的中间件可能只考虑了一个应用的场景,故在一些行为上无法兼容多应用共存的行为,会发生共享变量污染、classLoader 加载异常、class 判断不符合预期等问题。
由此,在使用 Koupleless 中间件时,我们需要对一些潜在的问题做补丁,覆盖掉原有中间件的实现,使开源的中间件也能兼容多应用的模式。
‼️版本要求:koupleless-base-build-plugin
- jdk8: >= 1.3.3
- jdk17: >= 2.2.8
目前,koupleless 的三方包补丁生效原理为:
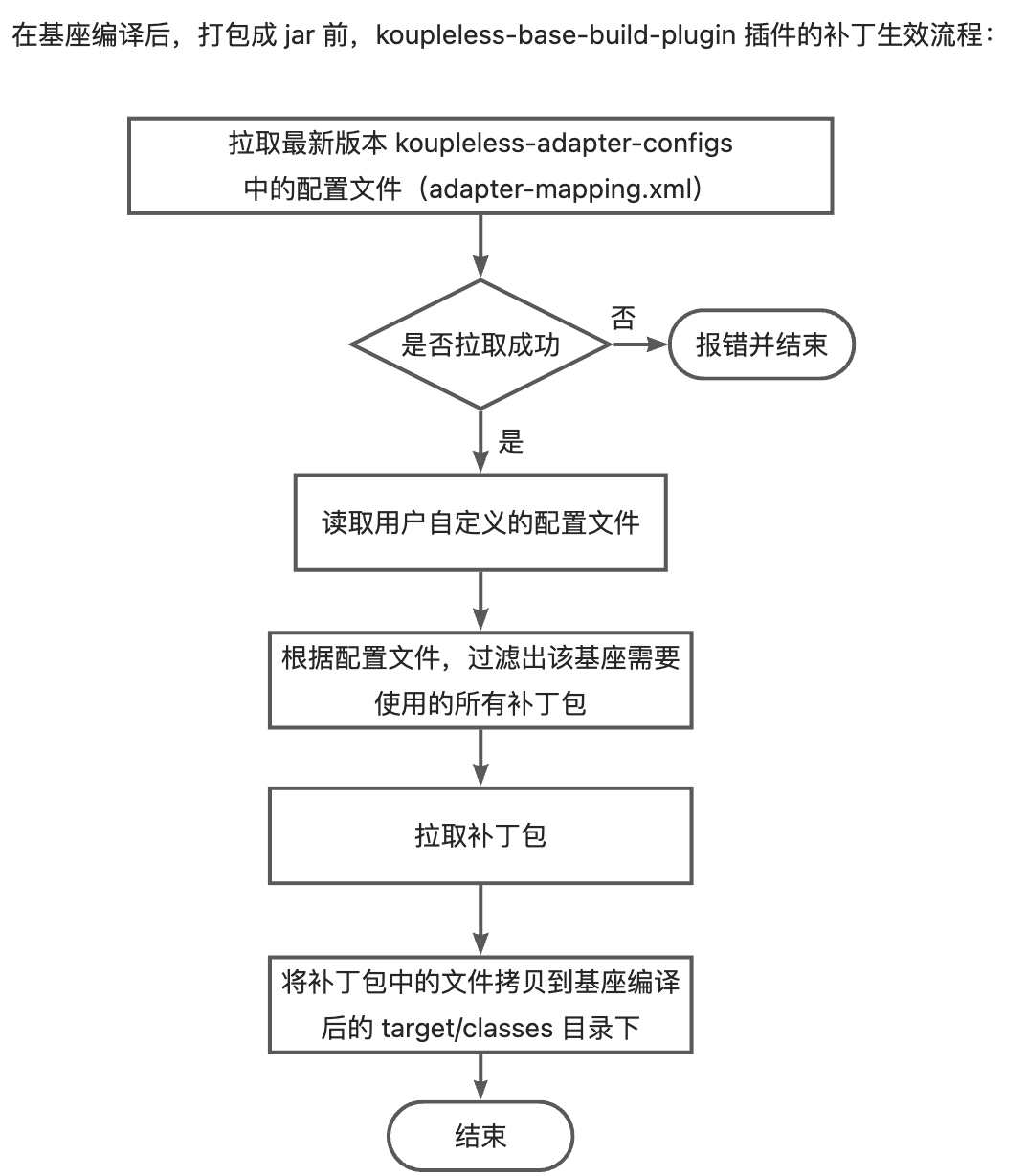
- 在基座编译后、打包前, koupleless-base-build-plugin 插件会获取 adapter 配置文件,该文件中描述了
符合版本范围的中间件依赖使用的补丁包,如:
version: 1.2.3
adapterMappings:
- matcher:
groupId: org.springframework.boot
artifactId: spring-boot
versionRange: "[2.5.1,2.7.14]"
adapter:
artifactId: koupleless-adapter-spring-boot-logback-2.7.14
groupId: com.alipay.sofa.koupleless
该配置文件的含义为:当基座依赖了 org.springframework.boot:spring-boot 版本范围在 [2.5.1, 2.7.14] 的版本时,则使用 koupleless-adapter-spring-boot-logback-2.7.14 版本为 1.2.3 的补丁包。
- 获取基座所有使用的依赖,根据 adapter 配置文件过滤出该基座需要使用的所有补丁包;
- 拉取补丁包,将补丁包中的文件拷贝到基座编译后的 target/classes 目录下。
其中,adapter 配置文件分两种:
- koupleless 管理的配置文件:在打包时,koupleless-base-build-plugin 插件会尝试拉取最新版本的 adapter 配置文件;如果拉取失败,则报错。目前,由 koupleless 管理的开源三方包补丁在 koupleless-adapter 仓库中,目前已有 20+ 个补丁包。
- 用户自定义的配置文件:用户可以自行在基座中添加 adapter 配置文件,该配置文件会和 koupleless 管理的通用配置文件同时生效。
注意: 这个自定义 yml 配置文件内容要放到基座工程代码根目录 conf/ark/adapter-mapping.yaml 文件里,并且要按照 1 中的 yaml 格式来配置。
怎么开发开源三方包的补丁包
👏 欢迎大家一起建设开源三方包补丁:
- 开发补丁代码文件:复制需要补丁的文件,修改其中的代码,使其符合多应用的场景。
特别注意 1: 有些 SDK,自己使用 reshade 和 relocation 方式在构建阶段重命名了其间接依赖的 SDK 包名,典型如 MyBatis 里把 ognl 包重命名为了 org.apache.ibatis.ognl,这就导致你在适配覆写 MyBatis OgnlCache 类的时候,文件开头的 import 语句,要从 MyBatis 源代码里的 import ognl.xxx 都改成 import org.apache.ibatis.ognl.xxx ,否则就会遇到运行期 ClassNoDef 报错。具体案例详见对 MyBatis 的适配。
特别注意 2: adapter 提供了 koupleless-adapter-utils 工具包,里面提供了查找当前 Thread ClassLoader、反射调用等工具方法,如果需要,请把它以 compile 依赖方式放到你写的 adapter 子工程 pom.xml 中,在覆盖 SpringBoot 应用时,adapter 里 compile 依赖的 SDK 也会被打包到对方的 SpringBoot 工程中,不会发生 ClassNoDef 之类的问题。 - 确认该补丁生效的依赖包版本范围(即:在该版本范围内,开源包的该代码文件完全相同),如,对于版本范围在:[2.5.1, 2.7.14] 的 org.springframework.boot:spring-boot 的
org.springframework.boot.logging.logback.LogbackLoggingSystem文件都相同。 - 在 koupleless-adapter 仓库中,创建补丁包模块,如:
koupleless-adapter-spring-boot-logback-2.7.14,在该模块中覆盖写需要补丁的文件,如:org.springframework.boot.logging.logback.LogbackLoggingSystem - 在
koupleless-adapter-spring-boot-logback-2.7.14根目录下,创建conf/adapter-mappings.yaml文件,描述该补丁生效的匹配规则,并完成单测。 - 提交 PR
以 koupleless-adapter-spring-boot-logback-2.7.14 补丁包为例,补丁包代码可见 koupleless-adapter-spring-boot-logback-2.7.14。
怎么开发内部二方包的补丁包
- 开发补丁代码文件:复制需要补丁的文件,修改其中的代码,使其符合多应用的场景
- 确认该补丁生效的依赖包版本范围(即:在该版本范围内,二方包的该代码文件完全相同),如,对于版本范围在:[2.5.1, 2.7.14] 的 yyy:xxx 的
yyy.xxx.CustomSystem文件都相同。 - 开发补丁包,如:
koupleless-adapter-xxx-2.1.0,在该包中覆盖写需要补丁的文件,如:com.xxx.YYY,并打包发布为 jar 包。 - 在基座的
conf/ark/adapter-mapping.yaml中,添加该补丁包的依赖配置,如:
adapterMappings:
- matcher:
groupId: yyy
artifactId: xxx
versionRange: "[2.5.1,2.7.14]"
adapter:
artifactId: koupleless-adapter-xxx-2.1.0
groupId: yyy
version: 1.0.0
5.3.3 - 6.5.3.2 多模块集成测试框架介绍
本文着重介绍多模块继承测试框架的设计思路、实现细节、使用方式。
为什么需要多模块集成测试框架?
假设没有集成测试框架,当开发者想要验证多模块部署的进程是否行为正确时,开发者需要进行如下步骤:
- 构建基座和所有模块的 jar 包。
- 启动基座进程。
- 安装模块 jar 包到基座中。
- 进行 HTTP / RPC 接口的掉用。
- 验证返回结果是否正确。
上述工作流看起来简单,但是开发者面临如下困扰:
- 反复在命令行和代码中来回切换。
- 如果验证结果不正确,还需要反复修改代码和重新构建 + 远程 debug。
- 如果 APP 本来只提供内部方法,为了验证多模块部署的行为,还需要修改代码通过 HTTP / RPC 暴露接口。
上述困扰导致开发者的效率低下,体验不友好。因此,我们需要一个集成测试框架来提供一站式的验证体验。
集成测试框架需要解决哪些问题?
集成测试框架需要能在同一个进程中,通过一次启动,模拟多模块部署的行为。 同时也允许开发者直接对模块 / 基座进行直接的代码调用,验证模块的行为是否正确。 这需要解决如下几个技术问题:
- 模拟基座 springboot 的启动。
- 模拟模块 springboot 的启动,同时支持直接从 dependency 中而非 jar 包中加载模块。
- 模拟 ark-plugin 的加载。
- 和 maven 的测试命令集成兼容。
由于默认的 sofa-ark 是通过 jar 包的方式加载模块的 executable-jar 包和 ark-plugin。 而显然,这会需要开发者在每次验证时都需要重新构建 jar 包 / 发布到仓库,降低验证效率。 所以,框架需要能够拦截掉对应的加载行为,直接从 maven 依赖中加载模块,模拟多模块部署的行为。完成相关工作的代码有:
- TestBizClassLoader: 完成模拟 biz 模块的加载工作,是原来 BizClassLoader 的派生类, 解决了在同一个 jar 包下按需加载类到不同的 ClassLoader 的问题。
- TestBiz: 完成模拟 biz 模块的启动工作,是原来 Biz 的派生类,封装了初始化 TestBizClassLoader 的逻辑。
- TestBootstrap: 完成 ArkContainer 的初始化,并完成 ark-plugin 的加载等。
- TestClassLoaderHook: 通过 Hook 机制控制 resource 的加载顺序,例如 biz jar 包中的 application.properties 会被优先加载。
- BaseClassLoader: 模拟正常的基座 ClassLoader 行为,会和 surefire 等测试框架进行适配。
- TestMultiSpringApplication: 模拟多模块的 springboot 启动行为。
如何使用集成测试框架?
在同一个进程中同时启动基座和模块 springboot
样例代码如下:
public void demo() {
new TestMultiSpringApplication(MultiSpringTestConfig
.builder()
.baseConfig(BaseSpringTestConfig
.builder()
.mainClass(BaseApplication.class) // 基座的启动类
.build())
.bizConfigs(Lists.newArrayList(
BizSpringTestConfig
.builder()
.bizName("biz1") // 模块1的名称
.mainClass(Biz1Application.class) // 模块1的启动类
.build(),
BizSpringTestConfig
.builder()
.bizName("biz2") // 模块2的名称
.mainClass(Biz2Application.class) // 模块2的启动类
.build()
))
.build()
).run();
}
进行 Assert 逻辑的编写
可以通过如下方式获取模块的服务:
public void getService() {
StrategyService strategyService = SpringServiceFinder.
getModuleService(
"biz1-web-single-host",
"0.0.1-SNAPSHOT",
"strategyServiceImpl",
StrategyService.class
);
}
获取到服务后,可以进行断言逻辑的编写。
用例参考
更完整的用例可以参考 tomcat 多模块集成测试用例
5.3.4 - 6.5.3.3 dubbo2.7 的多模块化适配
为什么需要做适配
原生 dubbo2.7 在多模块场景下,无法支持模块发布自己的dubbo服务,调用时存在序列化、类加载异常等一系列问题。
多模块适配方案
dubbo2.7多模块适配SDK 在基座构建时 koupleless-base-build-plugin 会自动将 patch 代码打包到基座代码里,该适配逻辑主要从类加载、服务发布、服务卸载、服务隔离、模块维度服务管理、配置管理、序列化等方面进行适配。
1. AnnotatedBeanDefinitionRegistryUtils使用基座classloader无法加载模块类
com.alibaba.spring.util.AnnotatedBeanDefinitionRegistryUtils#isPresentBean
public static boolean isPresentBean(BeanDefinitionRegistry registry, Class<?> annotatedClass) {
...
// ClassLoader classLoader = annotatedClass.getClassLoader(); // 原生逻辑
ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); // 改为使用tccl加载类
for (String beanName : beanNames) {
BeanDefinition beanDefinition = registry.getBeanDefinition(beanName);
if (beanDefinition instanceof AnnotatedBeanDefinition) {
...
String className = annotationMetadata.getClassName();
Class<?> targetClass = resolveClassName(className, classLoader);
...
}
}
return present;
}
2. 模块维度的服务、配置资源管理
- com.alipay.sofa.koupleless.support.dubbo.ServerlessServiceRepository 替代原生 org.apache.dubbo.rpc.model.ServiceRepository
原生service采用interfaceName作为缓存,在基座、模块发布同样interface,不同group服务时,无法区分,替代原生service缓存模型,采用Interface Class类型作为key,同时采用包含有group的path作为key,支持基座、模块发布同interface不同group的场景
private static ConcurrentMap<Class<?>, ServiceDescriptor> globalClassServices = new ConcurrentHashMap<>();
private static ConcurrentMap<String, ServiceDescriptor> globalPathServices = new ConcurrentHashMap<>();
com.alipay.sofa.koupleless.support.dubbo.ServerlessConfigManager 替代原生 org.apache.dubbo.config.context.ConfigManager
为原生config添加classloader维度的key,不同模块根据classloader隔离不同的配置
final Map<ClassLoader, Map<String, Map<String, AbstractConfig>>> globalConfigsCache = new HashMap<>();
public void addConfig(AbstractConfig config, boolean unique) {
...
write(() -> {
Map<String, AbstractConfig> configsMap = getCurrentConfigsCache().computeIfAbsent(getTagName(config.getClass()), type -> newMap());
addIfAbsent(config, configsMap, unique);
});
}
private Map<String, Map<String, AbstractConfig>> getCurrentConfigsCache() {
ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader(); // 根据当前线程classloader隔离不同配置缓存
globalConfigsCache.computeIfAbsent(contextClassLoader, k -> new HashMap<>());
return globalConfigsCache.get(contextClassLoader);
}
ServerlessServiceRepository 和 ServerlessConfigManager 都依赖 dubbo ExtensionLoader 的扩展机制,从而替代原生逻辑,具体原理可参考 org.apache.dubbo.common.extension.ExtensionLoader.createExtension
3. 模块维度服务发布、服务卸载
override DubboBootstrapApplicationListener 禁止原生dubbo模块启动、卸载时发布、卸载服务
- com.alipay.sofa.koupleless.support.dubbo.BizDubboBootstrapListener
原生dubbo2.7只在基座启动完成后发布dubbo服务,在多模块时,无法支持模块的服务发布,Ark采用监听器监听模块启动事件,并手动调用dubbo进行模块维度的服务发布
private void onContextRefreshedEvent(ContextRefreshedEvent event) {
try {
ReflectionUtils.getMethod(DubboBootstrap.class, "exportServices")
.invoke(dubboBootstrap);
ReflectionUtils.getMethod(DubboBootstrap.class, "referServices").invoke(dubboBootstrap);
} catch (Exception e) {
}
}
原生dubbo2.7在模块卸载时会调用DubboShutdownHook,将JVM中所有dubbo service unexport,导致模块卸载后基座、其余模块服务均被卸载,Ark采用监听器监听模块spring上下文关闭事件,手动卸载当前模块的dubbo服务,保留基座、其余模块的dubbo服务
private void onContextClosedEvent(ContextClosedEvent event) {
// DubboBootstrap.unexportServices 会 unexport 所有服务,只需要 unexport 当前 biz 的服务即可
Map<String, ServiceConfigBase<?>> exportedServices = ReflectionUtils.getField(dubboBootstrap, DubboBootstrap.class, "exportedServices");
Set<String> bizUnexportServices = new HashSet<>();
for (Map.Entry<String, ServiceConfigBase<?>> entry : exportedServices.entrySet()) {
String serviceKey = entry.getKey();
ServiceConfigBase<?> sc = entry.getValue();
if (sc.getRef().getClass().getClassLoader() == Thread.currentThread().getContextClassLoader()) { // 根据ref服务实现的类加载器区分模块服务
bizUnexportServices.add(serviceKey);
configManager.removeConfig(sc); // 从configManager配置管理中移除服务配置
sc.unexport(); // 进行服务unexport
serviceRepository.unregisterService(sc.getUniqueServiceName()); // 从serviceRepository服务管理中移除配置
}
}
for (String service : bizUnexportServices) {
exportedServices.remove(service); // 从DubboBootstrap中移除该service
}
}
4. 服务路由
- com.alipay.sofa.koupleless.support.dubbo.ConsumerRedefinePathFilter
dubbo服务调用时通过path从ServiceRepository中获取正确的服务端服务模型(包括interface、param、return类型等)进行服务调用、参数、返回值的序列化,原生dubbo2.7采用interfaceName作为path查找service model,无法支持多模块下基座模块发布同interface的场景,Ark自定义consumer端filter添加group信息到path中,以便provider端进行正确的服务路由
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
if (invocation instanceof RpcInvocation) {
RpcInvocation rpcInvocation = (RpcInvocation) invocation;
// 原生path为interfaceName,如com.alipay.sofa.rpc.dubbo27.model.DemoService
// 修改后path为serviceUniqueName,如masterBiz/com.alipay.sofa.rpc.dubbo27.model.DemoService
rpcInvocation.setAttachment("interface", rpcInvocation.getTargetServiceUniqueName()); // 原生path为interfaceName,如
}
return invoker.invoke(invocation);
}
5. 序列化
- org.apache.dubbo.common.serialize.java.JavaSerialization
- org.apache.dubbo.common.serialize.java.ClassLoaderJavaObjectInput
- org.apache.dubbo.common.serialize.java.ClassLoaderObjectInputStream
在获取序列化工具JavaSerialization时,使用ClassLoaderJavaObjectInput替代原生JavaObjectInput,传递provider端service classloader信息
// org.apache.dubbo.common.serialize.java.JavaSerialization
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new ClassLoaderJavaObjectInput(new ClassLoaderObjectInputStream(null, is)); // 使用ClassLoaderJavaObjectInput替代原生JavaObjectInput,传递provider端service classloader信息
}
// org.apache.dubbo.common.serialize.java.ClassLoaderObjectInputStream
private ClassLoader classLoader;
public ClassLoaderObjectInputStream(final ClassLoader classLoader, final InputStream inputStream) {
super(inputStream);
this.classLoader = classLoader;
}
- org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcInvocation 服务端反序列化参数
// patch begin
if (in instanceof ClassLoaderJavaObjectInput) {
InputStream is = ((ClassLoaderJavaObjectInput) in).getInputStream();
if (is instanceof ClassLoaderObjectInputStream) {
ClassLoader cl = serviceDescriptor.getServiceInterfaceClass().getClassLoader(); // 设置provider端service classloader信息到ClassLoaderObjectInputStream中
((ClassLoaderObjectInputStream) is).setClassLoader(cl);
}
}
// patch end
- org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcResult 客户端反序列化返回值
// patch begin
if (in instanceof ClassLoaderJavaObjectInput) {
InputStream is = ((ClassLoaderJavaObjectInput) in).getInputStream();
if (is instanceof ClassLoaderObjectInputStream) {
ClassLoader cl = invocation.getInvoker().getInterface().getClassLoader(); // 设置consumer端service classloader信息到ClassLoaderObjectInputStream中
((ClassLoaderObjectInputStream) is).setClassLoader(cl);
}
}
// patch end
多模块 dubbo2.7 使用样例
5.3.5 - 6.5.3.4 ehcache 的多模块化最佳实践
为什么需要最佳实践
CacheManager 初始化的时候存在共用 static 变量,多应用使用相同的 ehcache name,导致缓存互相覆盖。
最佳实践的几个要求
- 基座里必须引入 ehcache,模块里复用基座
在 springboot 里 ehcache 的初始化需要通过 Spring 里定义的 EhCacheCacheConfiguration 来创建,由于 EhCacheCacheConfiguration 是属于 Spring, Spring 统一放在基座里。

这里在初始化的时候,在做 Bean 初始化的条件判断时会走到类的检验,

如果 net.sf.ehcache.CacheManager 是。这里会走到 java native 方法上做判断,从当前类所在的 ClassLoader 里查找 net.sf.ehcache.CacheManager 类,所以基座里必须引入这个依赖,否则会报 ClassNotFound 的错误。

- 模块里将引入的 ehcache 排包掉(scope设置成 provide,或者使用自动瘦身能力)
模块使用自己 引入的 ehcache,照理可以避免共用基座 CacheManager 类里的 static 变量,而导致报错的问题。但是实际测试发现,模块安装的时候,在初始化 enCacheCacheManager 时,



所以结论是,这里需要全部委托给基座加载。
最佳实践的方式
- 模块 ehcache 排包瘦身委托给基座加载
- 如果多个模块里有多个相同的 cacheName,需要修改 cacheName 为不同值。
- 如果不想改代码的方式修改 cache name,可以通过打包插件的方式动态替换 cacheName
<plugin>
<groupId>com.google.code.maven-replacer-plugin</groupId>
<artifactId>replacer</artifactId>
<version>1.5.3</version>
<executions>
<!-- 打包前进行替换 -->
<execution>
<phase>prepare-package</phase>
<goals>
<goal>replace</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- 自动识别到项目target文件夹 -->
<basedir>${build.directory}</basedir>
<!-- 替换的文件所在目录规则 -->
<includes>
<include>classes/j2cache/*.properties</include>
</includes>
<replacements>
<replacement>
<token>ehcache.ehcache.name=f6-cache</token>
<value>ehcache.ehcache.name=f6-${parent.artifactId}-cache</value>
</replacement>
</replacements>
</configuration>
</plugin>
- 需要把 FactoryBean 的 shared 设置成 false
@Bean
public EhCacheManagerFactoryBean ehCacheManagerFactoryBean() {
EhCacheManagerFactoryBean factoryBean = new EhCacheManagerFactoryBean();
// 需要把 factoryBean 的 share 属性设置成 false
factoryBean.setShared(true);
// factoryBean.setShared(false);
factoryBean.setCacheManagerName("biz1EhcacheCacheManager");
factoryBean.setConfigLocation(new ClassPathResource("ehcache.xml"));
return factoryBean;
}
否则会进入这段逻辑,初始化 CacheManager 的static 变量 instance. 该变量如果有值,且如果模块里 shared 也是ture 的化,就会重新复用 CacheManager 的 instance,从而拿到基座的 CacheManager, 从而报错。


最佳实践的样例
样例工程请参考这里
5.3.6 - 6.5.3.5 logback 的多模块化适配
为什么需要做适配
原生 logback 只有默认日志上下文,各个模块间日志配置无法隔离,无法支持独立的模块日志配置,最终导致在合并部署多模块场景下,模块只能使用基座的日志配置,对模块日志打印带来不便。
多模块适配方案
Logback 支持原生扩展 ch.qos.logback.classic.selector.ContextSelector,该接口支持自定义上下文选择器,Ark 默认实现了 ContextSelector 对多个模块的 LoggerContext 进行隔离 (参考 com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector),不同模块使用各自独立的 LoggerContext,确保日志配置隔离
启动期,经由 spring 日志系统 LogbackLoggingSystem 对模块日志配置以及日志上下文进行初始化
指定上下文选择器为 com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector,添加JVM启动参数
-Dlogback.ContextSelector=com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector
当使用 slf4j 作为日志门面,logback 作为日志实现框架时,在基座启动时,首次进行 slf4j 静态绑定时,将初始化具体的 ContextSelector,当没有自定义上下文选择器时,将使用 DefaultContextSelector, 当我们指定上下文选择器时,将会初始化 ArkLogbackContextSelector 作为上下文选择器
ch.qos.logback.classic.util.ContextSelectorStaticBinder.init
public void init(LoggerContext defaultLoggerContext, Object key) {
...
String contextSelectorStr = OptionHelper.getSystemProperty(ClassicConstants.LOGBACK_CONTEXT_SELECTOR);
if (contextSelectorStr == null) {
contextSelector = new DefaultContextSelector(defaultLoggerContext);
} else if (contextSelectorStr.equals("JNDI")) {
// if jndi is specified, let's use the appropriate class
contextSelector = new ContextJNDISelector(defaultLoggerContext);
} else {
contextSelector = dynamicalContextSelector(defaultLoggerContext, contextSelectorStr);
}
}
static ContextSelector dynamicalContextSelector(LoggerContext defaultLoggerContext, String contextSelectorStr) {
Class<?> contextSelectorClass = Loader.loadClass(contextSelectorStr);
Constructor cons = contextSelectorClass.getConstructor(new Class[] { LoggerContext.class });
return (ContextSelector) cons.newInstance(defaultLoggerContext);
}
在 ArkLogbackContextSelector 中,我们使用 ClassLoader 区分不同模块,将模块 LoggerContext 根据 ClassLoader 缓存
根据 classloader 获取不同的 LoggerContext,在 Spring 环境启动时,根据 spring 日志系统初始化日志上下文,通过 org.springframework.boot.logging.logback.LogbackLoggingSystem.getLoggerContext 获取日志上下文,此时将会使用 Ark 实现的自定义上下文选择器 com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector.getLoggerContext() 返回不同模块各自的 LoggerContext
public LoggerContext getLoggerContext() {
ClassLoader classLoader = this.findClassLoader();
if (classLoader == null) {
return defaultLoggerContext;
}
return getContext(classLoader);
}
获取 classloader 时,首先获取线程上下文 classloader,当发现是模块的classloader时,直接返回,若tccl不是模块classloader,则从ClassContext中获取调用Class堆栈,遍历堆栈,当发现模块classloader时直接返回,这样做的目的是为了兼容tccl没有保证为模块classloader时的场景, 比如在模块代码中使用logger打印日志时,当前类由模块classloader自己加载,通过ClassContext遍历可以最终获得当前类,获取到模块classloader,以便确保使用模块对应的 LoggerContext
private ClassLoader findClassLoader() {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
if (classLoader != null && CONTAINER_CLASS_LOADER.equals(classLoader.getClass().getName())) {
return null;
}
if (classLoader != null && BIZ_CLASS_LOADER.equals(classLoader.getClass().getName())) {
return classLoader;
}
Class<?>[] context = new SecurityManager() {
@Override
public Class<?>[] getClassContext() {
return super.getClassContext();
}
}.getClassContext();
if (context == null || context.length == 0) {
return null;
}
for (Class<?> cls : context) {
if (cls.getClassLoader() != null
&& BIZ_CLASS_LOADER.equals(cls.getClassLoader().getClass().getName())) {
return cls.getClassLoader();
}
}
return null;
}
获取到合适 classloader 后,为不同 classloader选择不同的 LoggerContext 实例,所有模块上下文缓存在 com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector.CLASS_LOADER_LOGGER_CONTEXT 中,以 classloader 为 key
private LoggerContext getContext(ClassLoader cls) {
LoggerContext loggerContext = CLASS_LOADER_LOGGER_CONTEXT.get(cls);
if (null == loggerContext) {
synchronized (ArkLogbackContextSelector.class) {
loggerContext = CLASS_LOADER_LOGGER_CONTEXT.get(cls);
if (null == loggerContext) {
loggerContext = new LoggerContext();
loggerContext.setName(Integer.toHexString(System.identityHashCode(cls)));
CLASS_LOADER_LOGGER_CONTEXT.put(cls, loggerContext);
}
}
}
return loggerContext;
}
多模块 logback 使用样例
5.3.7 - 6.5.3.6 log4j2 的多模块化适配
为什么需要做适配
原生 log4j2 在多模块下,模块没有独立打印的日志目录,统一打印到基座目录里,导致日志和对应的监控无法隔离。这里做适配的目的就是要让模块能有独立的日志目录。
普通应用 log4j2 的初始化
在 Spring 启动前,log4j2 会使用默认值初始化一次各种 logContext 和 Configuration,然后在 Spring 启动过程中,监听 Spring 事件进行初始化
org.springframework.boot.context.logging.LoggingApplicationListener,这里会调用到 Log4j2LoggingSystem.initialize 方法

该方法会根据 loggerContext 来判断是否已经初始化过了
这里在多模块下会存在问题一
这里的 getLoggerContext 是根据 org.apache.logging.log4j.LogManager 所在 classLoader 来获取 LoggerContext。根据某个类所在 ClassLoader 来提取 LoggerContext 在多模块化里会存在不稳定,因为模块一些类可以设置为委托给基座加载,所以模块里启动的时候,可能拿到的 LoggerContext 是基座的,导致这里 isAlreadyInitialized 直接返回,导致模块的 log4j2 日志无法进一步根据用户配置文件配置。
如果没初始化过,则会进入 super.initialize, 这里需要做两部分事情:
- 获取到日志配置文件
- 解析日志配置文件里的变量值 这两部分在多模块里都可能存在问题,先看下普通应用过程是如何完成这两步的
获取日志配置文件

可以看到是通过 ResourceUtils.getURL 获取的 location 对应日志配置文件的 url,这里通过获取到当前线程上下文 ClassLoader 来获取 URL,这在多模块下没有问题(因为每个模块启动时线程上下文已经是 模块自身的 ClassLoader )。

解析日志配置值
配置文件里有一些变量,例如这些变量

这些变量的解析逻辑在 org.apache.logging.log4j.core.lookup.AbstractLookup 的具体实现里,包括
| 变量写法 | 代码逻辑地址 | |
|---|---|---|
| ${bundle:application:logging.file.path} | org.apache.logging.log4j.core.lookup.ResourceBundleLookup | 根据 ResourceBundleLookup 所在 ClassLoader 提前到 application.properties, 读取里面的值 |
| ${ctx:logging.file.path} | org.apache.logging.log4j.core.lookup.ContextMapLookup | 根据 LoggerContext 上下文 ThreadContex 存储的值来提起,这里需要提前把 applicaiton.properties 的值设置到 ThreadContext 中 |
根据上面判断通过 bundle 的方式配置在多模块里不可行,因为 ResourceBundleLookup 可能只存在于基座中,导致始终只能拿到基座的 application.properties,导致模块的日志配置路径与基座相同,模块日志都打到基座中。所以需要改造成使用 ContextMapLookup。
static final修饰的Logger导致三方组件下沉基座后日志打印不能正常隔离
如:
private static final Logger LOG = LoggerFactory.getLogger(CacheManager.class);
- static final修饰的变量只会在类加载的时候初始化话一次
- 组件依赖下沉基座后,类加载器使用的为基座的类加载器,初始化log实例时使用的是基座的log配置,所以会打印到基座文件中,不能正常隔离
具体获取log源码如下:
//org.apache.logging.log4j.spi.AbstractLoggerAdapter
@Override
public L getLogger(final String name) {
//关键是LoggerContext获取是否正确,往下追
final LoggerContext context = getContext();
final ConcurrentMap<String, L> loggers = getLoggersInContext(context);
final L logger = loggers.get(name);
if (logger != null) {
return logger;
}
loggers.putIfAbsent(name, newLogger(name, context));
return loggers.get(name);
}
//获取LoggerContext
protected LoggerContext getContext() {
Class<?> anchor = LogManager.getFactory().isClassLoaderDependent() ? StackLocatorUtil.getCallerClass(Log4jLoggerFactory.class, CALLER_PREDICATE) : null;
LOGGER.trace("Log4jLoggerFactory.getContext() found anchor {}", anchor);
return anchor == null ? LogManager.getContext(false) : this.getContext(anchor);
}
//获取LoggerContext,关键在这里
protected LoggerContext getContext(final Class<?> callerClass) {
ClassLoader cl = null;
if (callerClass != null) {
//会优先使用当前类相关的类加载器,这里肯定是基座的类加载,所以返回的是基座的LoggerContext
cl = callerClass.getClassLoader();
}
if (cl == null) {
cl = LoaderUtil.getThreadContextClassLoader();
}
return LogManager.getContext(cl, false);
}
预期多模块合并下的日志
基座与模块都能使用独立的日志配置、配置值,完全独立。但由于上述分析中,存在两处可能导致模块无法正常初始化的逻辑,故这里需要多 log4j2 进行适配。 static修饰的log在三方组件下沉基座后也会导致相关日志不能正常隔离打印,所以这里也需要做 log4j2 进行适配。
多模块适配点
- getLoggerContext() 能拿到模块自身的 LoggerContext

需要调整成使用 ContextMapLookup,从而模块日志能获取到模块应用名,日志能打印到模块目录里
a. 模块启动时将 application.properties 的值设置到 ThreadContext 中 b. 日志配置时,只能使用 ctx:xxx:xxx 的配置方式
LoggerFactory.getLogger()获取的是org.apache.logging.slf4j.Log4jLogger实例,他是一个包装类,所以有一定操作空间, 针对Log4jLogger进行复写改造,根据当前线程上下文类加载器动态获取底层ExtendedLogger对象
public class Log4JLogger implements LocationAwareLogger, Serializable {
private transient final Map<ClassLoader, ExtendedLogger> loggerMap = new ConcurrentHashMap<>();
private static final Map<ClassLoader, LoggerContext> LOGGER_CONTEXT_MAP = new ConcurrentHashMap<>();
pubblic void info(final String format, final Object o) {
//每次调用都获取对应的ExtendedLogger
getLogger().logIfEnabled(FQCN, Level.INFO, null, format, o);
}
//根据当前线程类加载器动态获取ExtendedLogger
private ExtendedLogger getLogger() {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
ExtendedLogger extendedLogger = loggerMap.get(classLoader);
if (extendedLogger == null) {
LoggerContext loggerContext = LOGGER_CONTEXT_MAP.get(classLoader);
if (loggerContext == null) {
loggerContext = LogManager.getContext(classLoader, false);
LOGGER_CONTEXT_MAP.put(classLoader, loggerContext);
}
extendedLogger = loggerContext.getLogger(this.name);
loggerMap.put(classLoader, extendedLogger);
}
return extendedLogger;
}
}
模块改造方式
5.3.8 - 6.5.3.7 模块使用宝蓝德 web 服务器
koupleless-adapter-bes
koupleless-adapter-bes 是为了适配宝蓝德(BES)容器,以支持基座模块复用相同的端口。仓库地址为 koupleless-adapter-bes(感谢社区同学陈坚贡献)。
项目目前仅在BES 9.5.5.004 版本中验证过,其他版本需要自行验证,必要的话需要根据相同的思路进行调整。
如果多个BIZ模块不需要使用同一端口来发布服务,只需要关注下文安装依赖章节提到的注意事项即可,不需要引入本项目相关的依赖。
快速开始
0. 前置条件
jdk8
koupleless >= 1.3.1 sofa-ark >= 2.2.14
jdk17
koupleless >= 2.1.6 sofa-ark >= 3.1.7
如果不满足改条件,需要按照该文档的老版本进行操作,可通过 github 文档源码查看该文档的老版本。
1. 安装依赖
首先需要确保已经在maven仓库中导入了BES相关的依赖,参考导入脚本如下:
mvn install:install-file -Dfile=D:/software/xc/BES-EMBED/bes-lite-spring-boot-starter-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-lite-spring-boot-starter -Dversion=9.5.5.004 -Dpackaging=jar
mvn install:install-file -Dfile=D:/software/xc/BES-EMBED/bes-gmssl-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-gmssl -Dversion=9.5.5.004 -Dpackaging=jar
mvn install:install-file -Dfile=D:/software/xc/BES-EMBED/bes-jdbcra-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-jdbcra -Dversion=9.5.5.004 -Dpackaging=jar
mvn install:install-file -Dfile=D:/software/xc/BES-EMBED/bes-websocket-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-websocket -Dversion=9.5.5.004 -Dpackaging=jar
2. 编译安装本项目插件
进入本项目的 bes9-web-adapter 目录执行 mvn install 命令即可。
项目将会安装 bes-web-ark-plugin 和 bes-sofa-ark-springboot-starter 两个模块。
3. 使用本项目组件
首先需要根据koupleless的文档,将项目升级为Koupleless基座
然后将依赖中提到的
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>web-ark-plugin</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
替换为本项目的坐标
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>bes-web-ark-plugin</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>bes-sofa-ark-springboot-starter</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
引入BES相关依赖(同时需要exclude tomcat的依赖)。参考依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>sofa-ark-bes-lite-spring-boot-starter</artifactId>
<version>9.5.5.004</version>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>bes-gmssl</artifactId>
<version>9.5.5.004</version>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>bes-jdbcra</artifactId>
<version>9.5.5.004</version>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>bes-websocket</artifactId>
<version>9.5.5.004</version>
</dependency>
4. 基座中增加宝蓝德特殊配置
为什么需要这个配置, 是因为 koupleless其中 SOFAArk组件对于依赖包的识别机制与BES的包结构冲突,参考这里
需要在模块根目录 ark 配置文件中(conf/ark/bootstrap.properties 或 conf/ark/bootstrap.yml)增加白名单
declared.libraries.whitelist=com.bes.besstarter:bes-sofa-ark-springboot-starter
5. 完成
完成上述步骤后,即可在 Koupleless 基座和模块中使用 BES 启动项目。
5.3.9 - 6.5.3.8 模块使用东方通 web 服务器
koupleless-adapter-tongweb
koupleless-adapter-tongweb 是为了适配东方通(TongWEB)容器,仓库地址为:koupleless-adapter-tongweb(感谢社区同学陈坚贡献)。
项目目前仅在tongweb-embed-7.0.E.6_P7 版本中验证过,其他版本需要自行验证,必要的话需要根据相同的思路进行调整。
如果多个BIZ模块不需要使用同一端口来发布服务,只需要关注下文安装依赖章节提到的注意事项即可,不需要引入本项目相关的依赖。
快速开始
0. 前置条件
jdk8
koupleless >= 1.3.1 sofa-ark >= 2.2.14
jdk17
koupleless >= 2.1.6 sofa-ark >= 3.1.7
如果不满足改条件,需要按照该文档的老版本进行操作,可通过 github 文档源码查看该文档的老版本。
1. 安装依赖
首先需要确保已经在 maven 仓库中导入了 TongWEB 相关的依赖,参考导入脚本如下:
mvn install:install-file -DgroupId=com.tongweb.springboot -DartifactId=tongweb-spring-boot-starter -Dversion=7.0.E.6_P7 -Dfile="XXX/tongweb-spring-boot-starter-7.0.E.6_P7.jar" -Dpackaging=jar
mvn install:install-file -DgroupId=com.tongweb -DartifactId=tongweb-embed-core -Dversion=7.0.E.6_P7 -Dfile="XXX/tongweb-embed-core-7.0.E.6_P7.jar" -Dpackaging=jar
mvn install:install-file -DgroupId=com.tongweb -DartifactId=tongweb-lic-sdk -Dversion=4.5.0.0 -Dfile="XXX/tongweb-lic-sdk-4.5.0.0.jar" -Dpackaging=jar
2. 编译安装本项目插件
进入本项目的 tongweb7-web-adapter 目录执行 mvn install 命令即可。
项目将会安装 tongweb7-web-ark-plugin 和 tongweb7-sofa-ark-springboot-starter 两个模块。
3. 使用本项目组件
首先需要根据koupleless的文档,将项目升级为Koupleless基座
然后将依赖中提到的
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>web-ark-plugin</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
替换为本项目的坐标
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>tongweb7-web-ark-plugin</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>tongweb7-sofa-ark-springboot-starter</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
引入TongWEB相关依赖(同时需要exclude tomcat的依赖)。参考依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.tongweb.springboot</groupId>
<artifactId>tongweb-spring-boot-starter</artifactId>
<version>7.0.E.6_P7</version>
</dependency>
<dependency>
<groupId>com.tongweb</groupId>
<artifactId>tongweb-embed-core</artifactId>
<version>7.0.E.6_P7</version>
</dependency>
<dependency>
<groupId>com.tongweb</groupId>
<artifactId>tongweb-lic-sdk</artifactId>
<version>4.5.0.0</version>
</dependency>
4. 基座中增加宝蓝德特殊配置
为什么需要这个配置, 是因为 koupleless其中 SOFAArk组件对于依赖包的识别机制与BES的包结构冲突,参考这里
需要在基座根目录 ark 配置文件中(conf/ark/bootstrap.properties 或 conf/ark/bootstrap.yml)增加白名单
declared.libraries.whitelist=com.tongweb.springboot:tongweb-spring-boot-starter,com.tongweb:tongweb-embed-core,com.tongweb:tongweb-lic-sdk
5. 完成
完成上述步骤后,即可在 Koupleless 基座和模块中使用 TongWEB 启动项目。
5.3.10 - 6.5.3.9 模块使用 Dubbo
模块拦截器(Filter)
模块可以使用本模块上定义的拦截器,也可以使用基座上定义的拦截器。
⚠️注意:避免模块拦截器的名称与基座拦截器名称一致。如果名称一致,则将使用基座拦截器。
5.3.11 - 6.5.3.10 基座与模块间类委托加载原理介绍
多模块间类委托加载
SOFAArk 框架是基于多 ClassLoader 的通用类隔离方案,提供类隔离和应用的合并部署能力。本文档并不打算介绍 SOFAArk 类隔离的原理与机制,这里主要介绍多 ClassLoader 当前的最佳实践。
当前基座与模块部署在 JVM 上的 ClassLoader 模型如图:

当前类委托加载机制
当前一个模块在启动与运行时查找的类,有两个来源:当前模块本身,基座。这两个来源的理想优先级顺序是,优先从模块中查找,如果模块找不到再从基座中查找,但当前存在一些特例:
- 当前定义了一份白名单,白名单范围内的依赖会强制使用基座里的依赖。
- 模块可以扫描到基座里的所有类:
- 优势:模块可以引入较少依赖
- 劣势:模块会扫描到模块代码里不存在的类,例如会扫描到一些 AutoConfiguration,初始化时由于第四点扫描不到对应资源,所以会报错。
- 模块不能扫描到基座里的任何资源:
- 优势:不会与基座重复初始化相同的 Bean
- 劣势:模块启动如果需要基座的资源,会因为查找不到资源而报错,除非模块里显示引入(Maven 依赖 scope 不设置成 provided)
- 模块调用基座时,部分内部处理传入模块里的类名到基座,基座如果存在直接从基座 ClassLoader 查找模块传入的类,会查找不到。因为委托只允许模块委托给基座,从基座发起的类查找不会再次查找模块里的。
使用时需要注意事项
模块要升级委托给基座的依赖时,需要让基座先升级,升级之后模块再升级。
类委托的最佳实践
类委托加载的准则是中间件相关的依赖需要放在同一个的 ClassLoader 里进行加载执行,达到这种方式的最佳实践有两种:
强制委托加载
由于中间件相关的依赖一般需要在同一个 ClassLoader 里加载运行,所以我们会制定一个中间件依赖的白名单,强制这些依赖委托给基座加载。
使用方法
application.properties 里增加配置 sofa.ark.plugin.export.class.enable=true。
优点
模块开发者不需要感知哪些依赖属于需要强制加载由同一个 ClassLoader 加载的依赖。
缺点
白名单里要强制加载的依赖列表需要维护,列表的缺失需要更新基座,较为重要的升级需要推所有的基座升级。
自定义委托加载
模块里 pom 通过设置依赖的 scope 为 provided主动指定哪些要委托给基座加载。通过模块瘦身把与基座重复的依赖委托给基座加载,并在基座里预置中间件的依赖(可选,虽然模块暂时不会用到,但可以提前引入,以备后续模块需要引入的时候不需再发布基座即可引入)。这里:
- 基座尽可能的沉淀通用的逻辑和依赖,特别是中间件相关以
xxx-alipay-sofa-boot-starter命名的依赖。 - 基座里预置一些公共依赖(可选)。
- 模块里的依赖如果基座里面已经有定义,则模块里的依赖尽可能的委托给基座,这样模块会更轻(提供自动模块瘦身的工具)。模块里有两种途径设置为委托给基座:
- 依赖里的 scope 设置为 provided,注意通过 mvn dependency:tree 查看是否还有其他依赖设置成了 compile,需要所有的依赖引用的地方都设置为 provided。
- biz 打包插件
sofa-ark-maven-plugin里设置excludeGroupIds或excludeArtifactIds
<plugin>
<groupId>com.alipay.sofa</groupId>
<artifactId>sofa-ark-maven-plugin</artifactId>
<configuration>
<excludeGroupIds>io.netty,org.apache.commons,......</excludeGroupIds>
<excludeArtifactIds>validation-api,fastjson,hessian,slf4j-api,junit,velocity,......</excludeArtifactIds>
<declaredMode>true</declaredMode>
</configuration>
</plugin>
通过 2.a 的方法需要确保所有声明的地方 scope 都设置为provided,通过2.b的方法只要指定一次即可,建议使用方法 2.b。
- 只有模块声明过的依赖才可以委托给基座加载。
模块启动的时候,Spring 框架会有一些扫描逻辑,这些扫描如果不做限制会查找到模块和基座的所有资源,导致一些模块明明不需要的功能尝试去初始化,从而报错。SOFAArk 2.0.3 之后新增了模块的 declaredMode, 来限制只有模块里声明过的依赖才可以委托给基座加载。只需在模块的打包插件的 Configurations 里增加 <declaredMode>true</declaredMode>即可。
优点
不需要维护 plugin 的强制加载列表,当部分需要由同一 ClassLoader 加载的依赖没有设置为统一加载时,可以修改模块就可以修复,不需要发布基座(除非基座确实依赖)。
缺点
对模块瘦身的依赖较强。
对比与总结
| 依赖缺失排查成本 | 修复成本 | 模块改造成本 | 维护成本 | |
|---|---|---|---|---|
| 强制加载 | 类转换失败或类查找失败,成本中 | 更新 plugin,发布基座,高 | 低 | 高 |
| 自定义委托加载 | 类转换失败或类查找失败,成本中 | 更新模块依赖,如果基座依赖不足,需要更新基座并发布,中 | 高 | 低 |
| 自定义委托加载 + 基座预置依赖 + 模块瘦身 | 类转换失败或类查找失败,成本中 | 更新模块依赖,设置为 provided,低 | 低 | 低 |
结论:推荐自定义委托加载方式
- 模块自定义委托加载 + 模块瘦身。
- 模块开启 declaredMode。
- 基座预置依赖。
declaredMode 开启方式
开启条件
declaredMode 的本意是让模块能合并部署到基座上,所以开启前需要确保模块能本地启动成功。
如果是 SOFABoot 应用且涉及到模块调用基座服务的,本地启动因为没有基座服务,可以通过在模块 application.properties 添加这两个参数进行跳过(SpringBoot 应用无需关心):
# 如果是 SOFABoot,则:
# 配置健康检查跳过 JVM 服务检查
com.alipay.sofa.boot.skip-jvm-reference-health-check=true
# 忽略未解析的占位符
com.alipay.sofa.ignore.unresolvable.placeholders=true
开启方式
模块打包插件里增加如下配置:

开启后的副作用
如果模块委托给基座的依赖里有发布服务,那么基座和模块会同时发布两份。
5.3.12 - 6.3.5.11 如果模块独立引入 SpringBoot 框架部分会怎样?
由于多模块运行时的逻辑在基座引入和加载,例如一些 Spring 的 Listener。如果模块启动使用完全自己的 SpringBoot,则会出现一些类的转换或赋值判断失败,例如:
CreateSpringFactoriesInstances

name = ‘com.alipay.sofa.ark.springboot.listener.ArkApplicationStartListener’, ClassUtils.forName 获取到的是从基座 ClassLoader 的类

而 type 是模块启动时加载的,也就是使用模块 BizClassLoader 加载。

此时这里做 isAssignable 判断,则会报错。
com.alipay.sofa.koupleless.plugin.spring.ServerlessApplicationListener is not assignable to interface org.springframework.context.ApplicationListener
所以模块框架这部分需要委托给基座加载。
5.4 - 6.5.4 模块拆分工具
5.4.1 - 6.5.4.1 半自动化拆分工具使用指南
背景
从大单体 SpringBoot 应用中拆出 Koupleless 模块时,用户拆分的学习和试错成本较高。用户需要先从服务入口分析要拆出哪些类至模块,然后根据 Koupleless 模块编码方式改造模块。
为了降低学习和试错成本,KouplelessIDE 插件提供半自动化拆分能力:分析依赖,并自动化修改。
快速开始
1. 安装插件
从 IDEA 插件市场安装插件 KouplelessIDE:
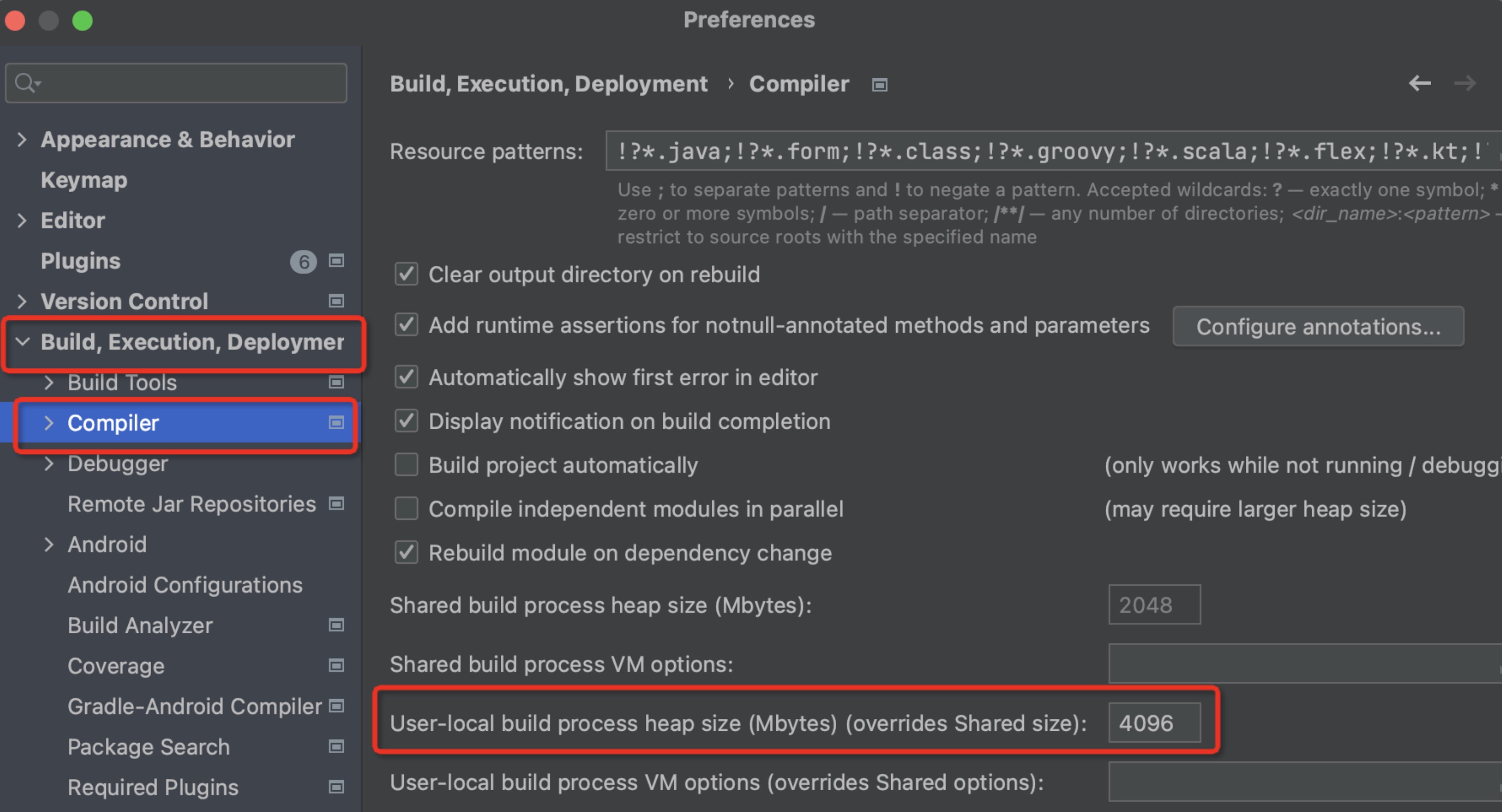
2. 配置 IDEA
确保 IDEA -> Preferences -> Builder -> Compiler 的 “User-local build process heap size” 至少为 4096
3. 选择模块
步骤一:用 IDEA 打开需要拆分的 SpringBoot 应用,在面板右侧打开 ServerlessSplit
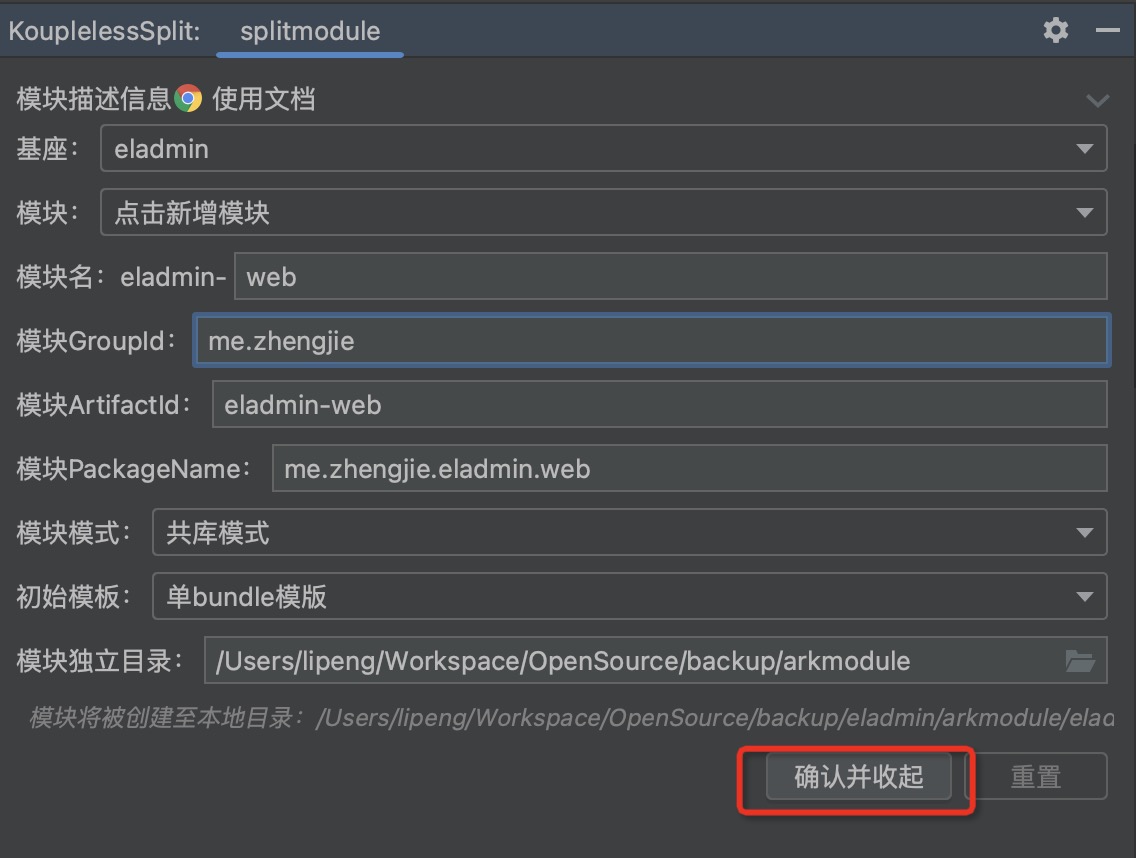
步骤二:按需选择拆分方式,点击“确认并收起”
4. 依赖分析
在拆分时,需要分析类和Bean之间的依赖。可以通过插件可视化依赖关系,由业务方决定某个类是否要拆分到模块中。
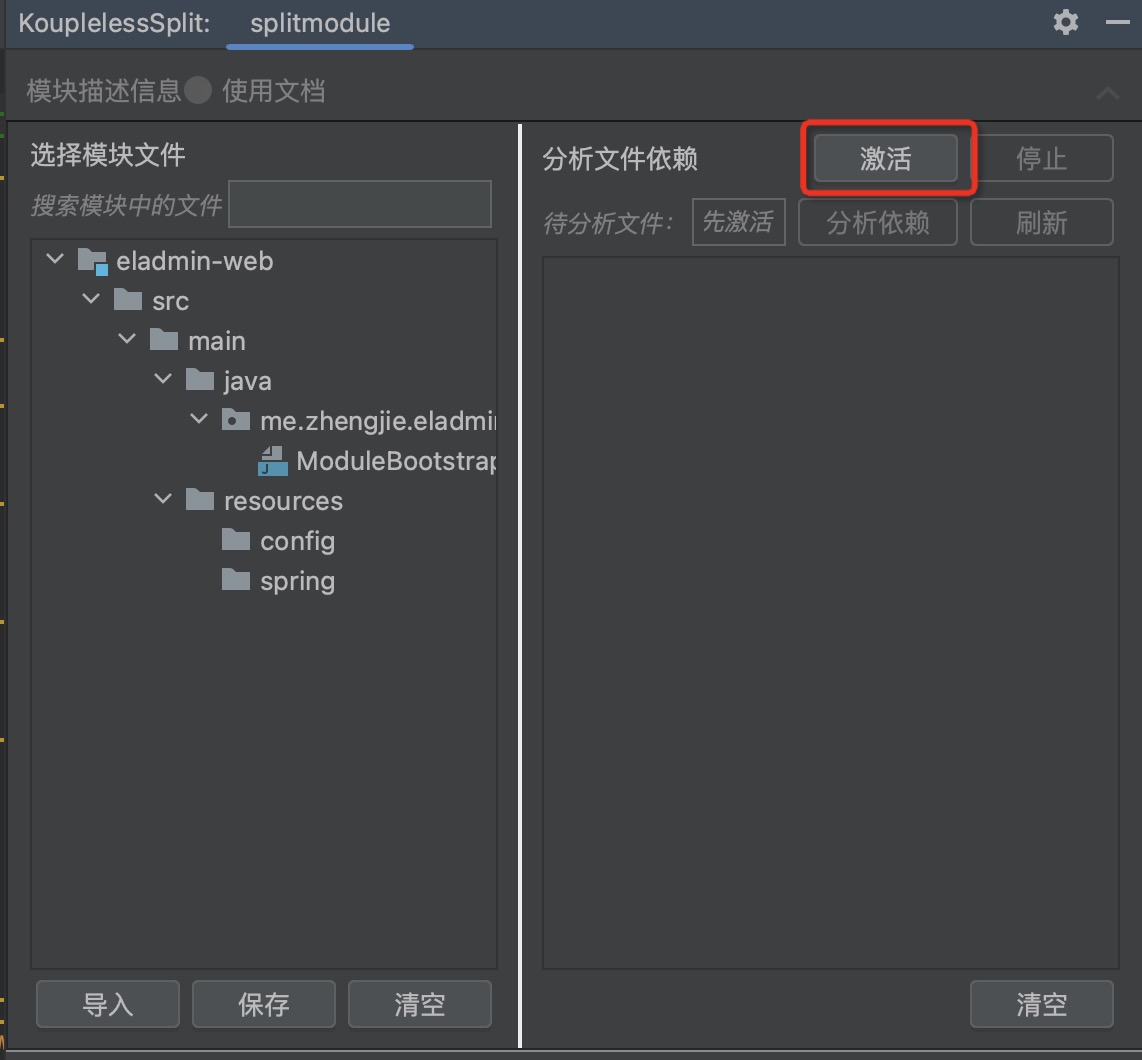
步骤一:点击激活
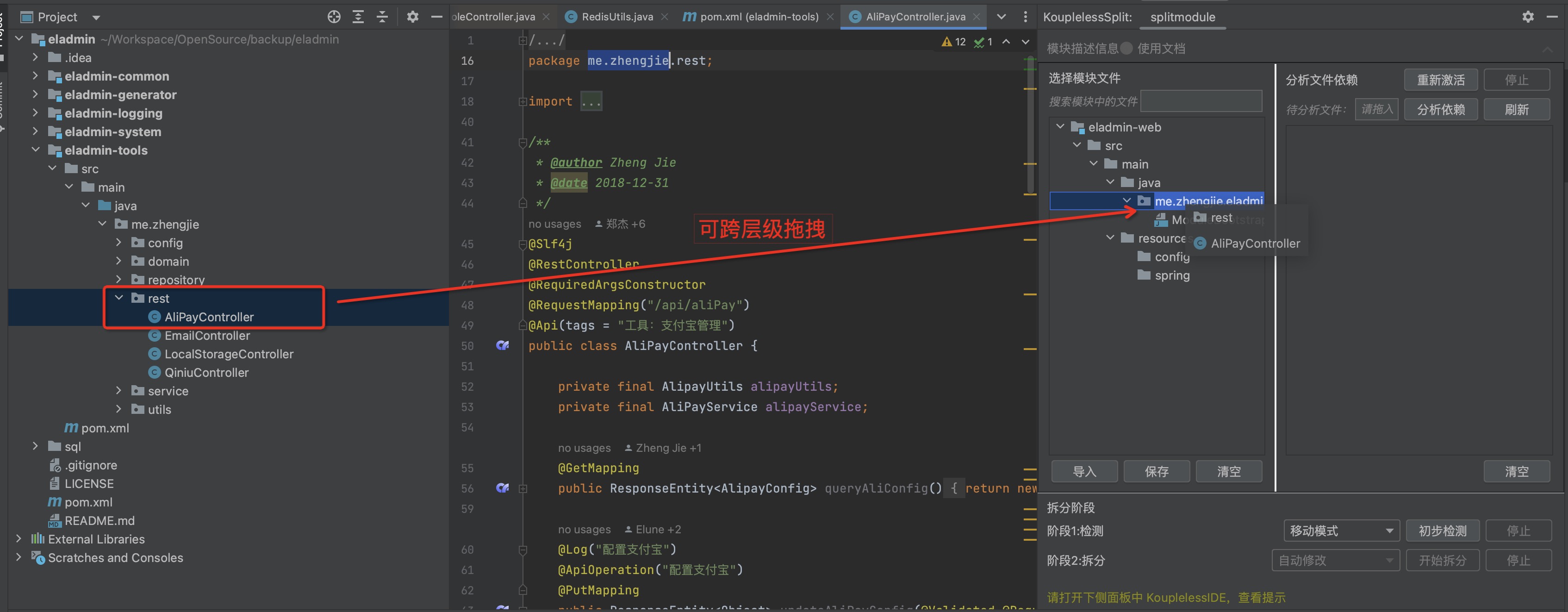
步骤二:拖拽服务入口至模块,支持跨层级拖拽
拖拽结果:
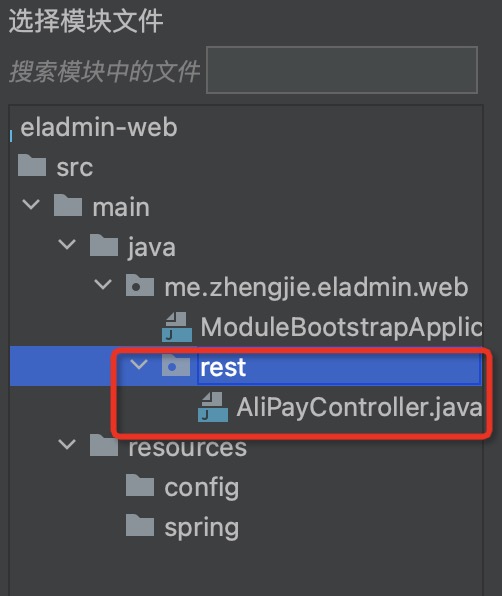
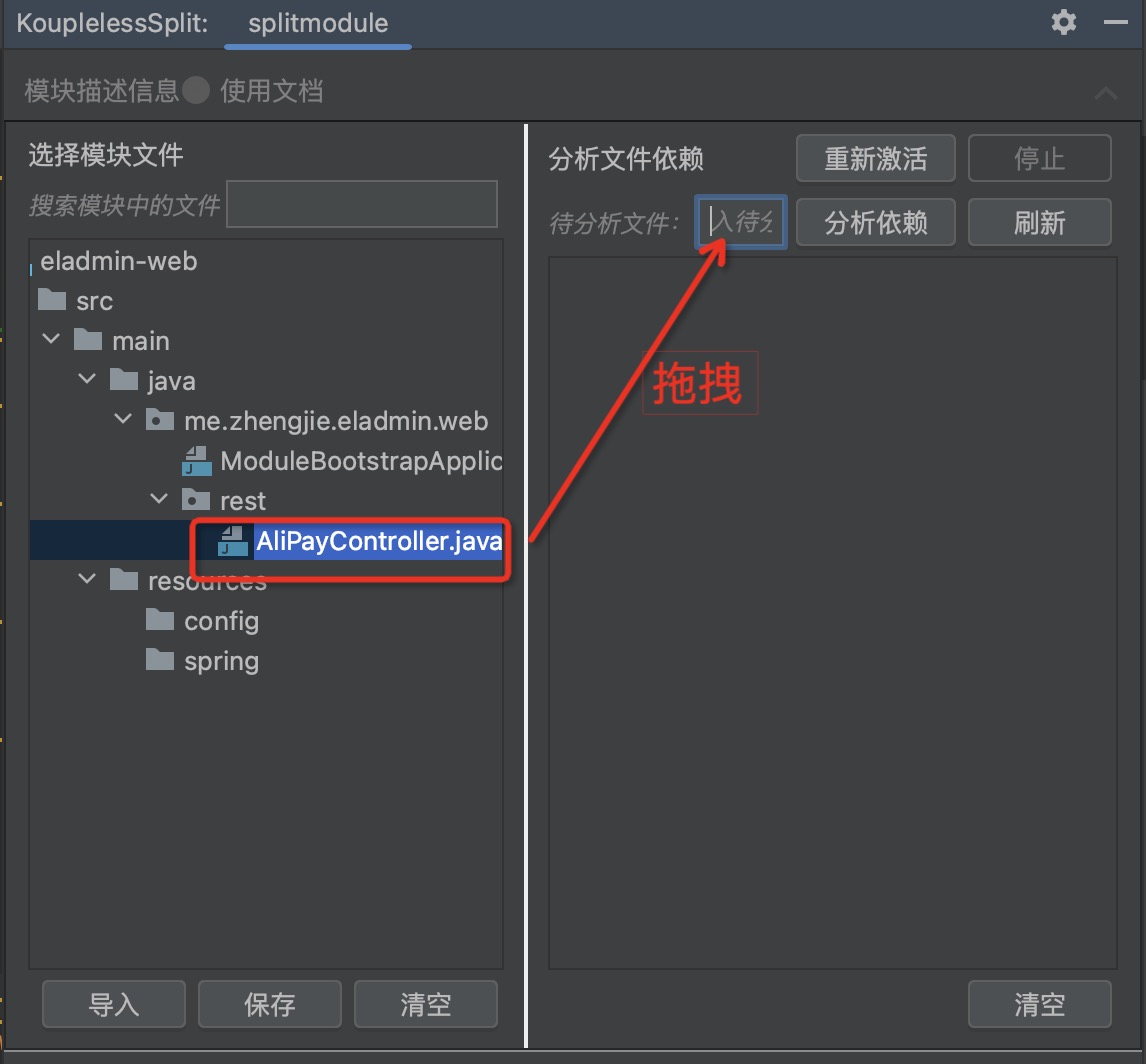
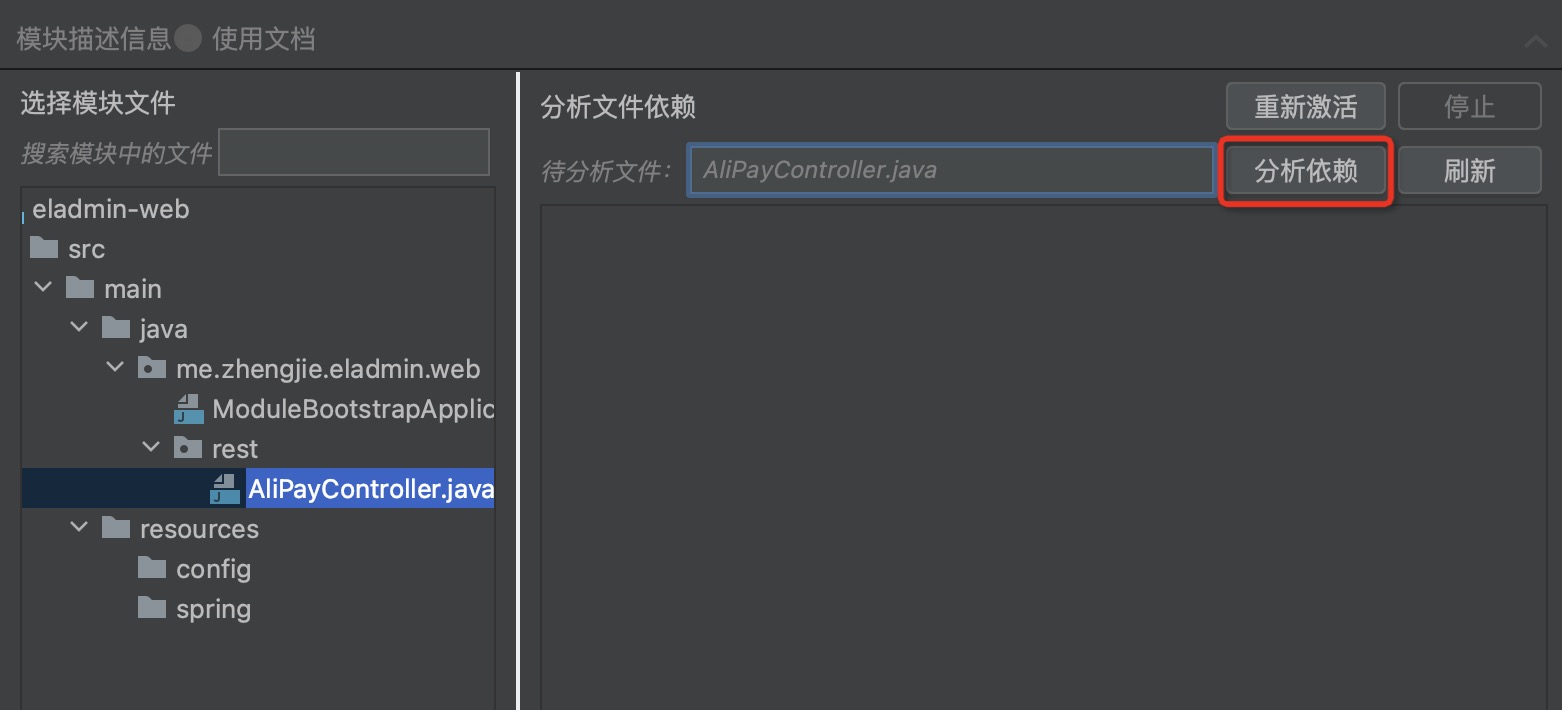
步骤三:拖拽“待分析文件”,点击分析依赖,查看类/Bean的依赖关系,如下图:
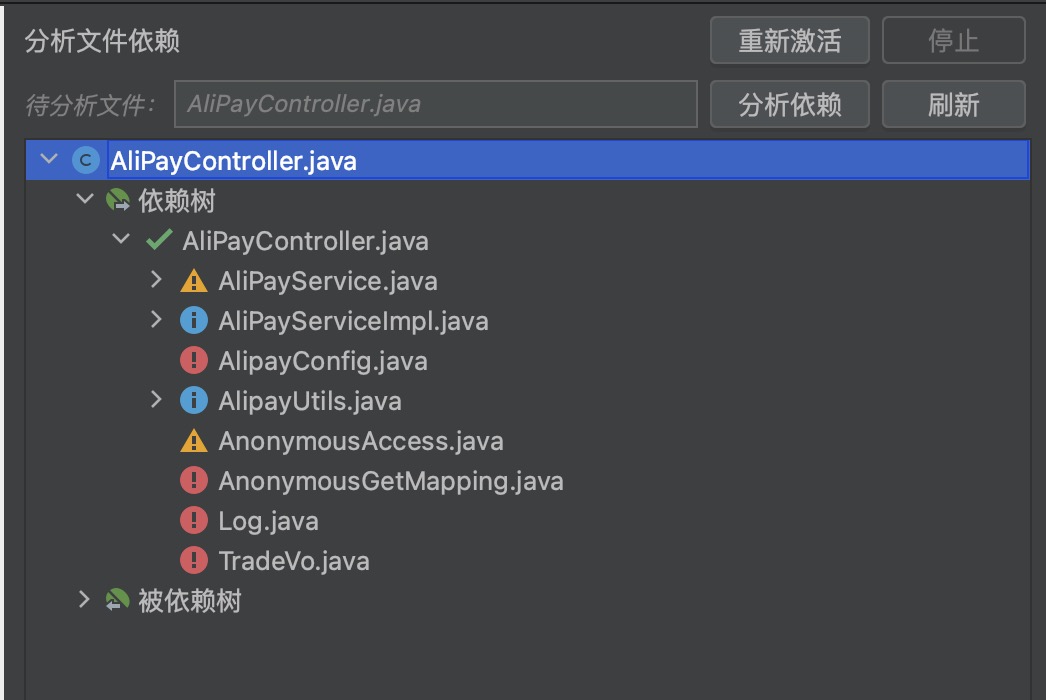
其中,各图标表示:
| 图标 | 含义 | 用户需要的操作 |
|---|---|---|
| 已在模块 | 无需操作 | |
 | 可移入模块 | 拖拽至模块 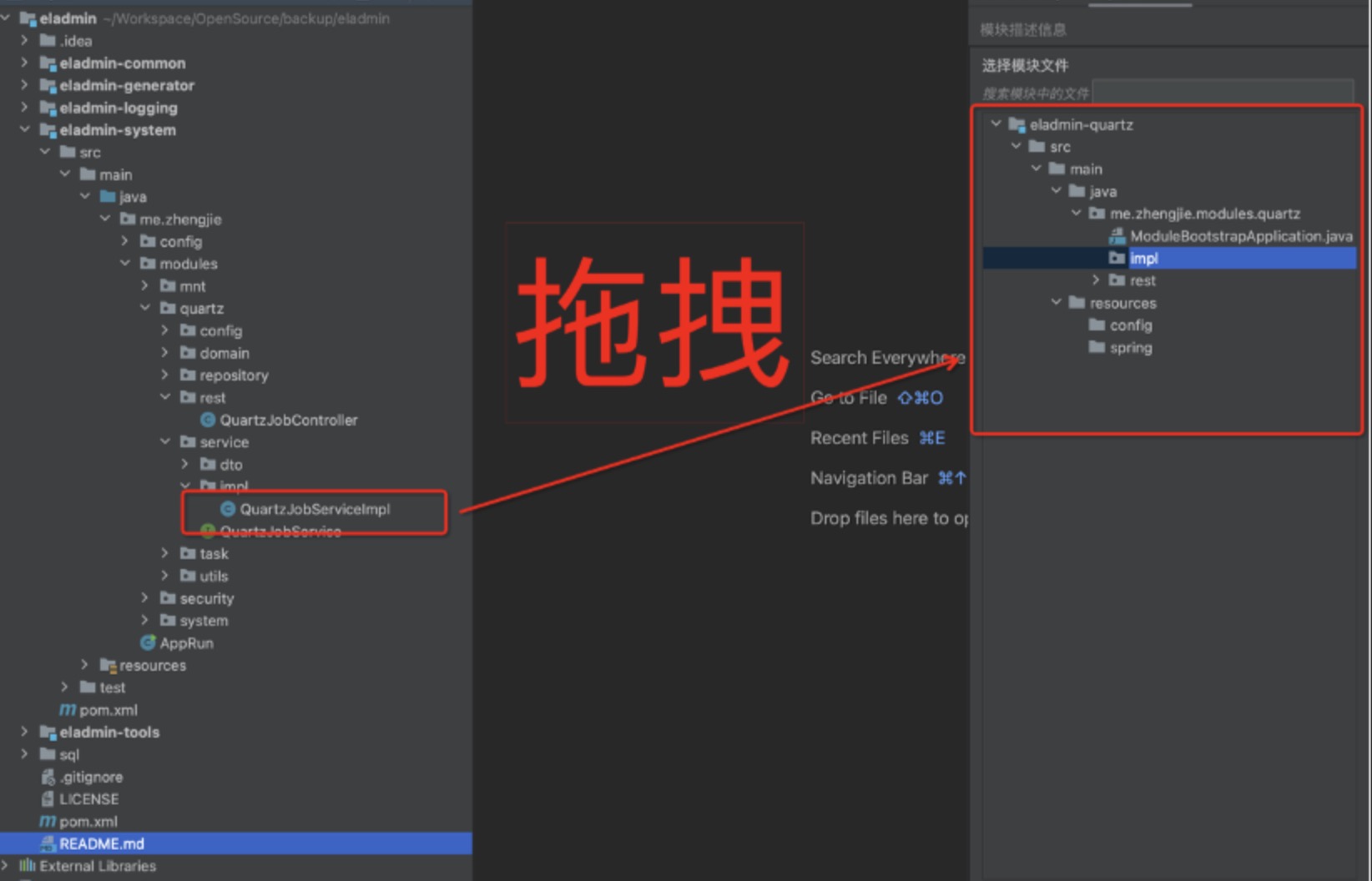 |
| 建议分析被依赖关系 | 拖拽至分析 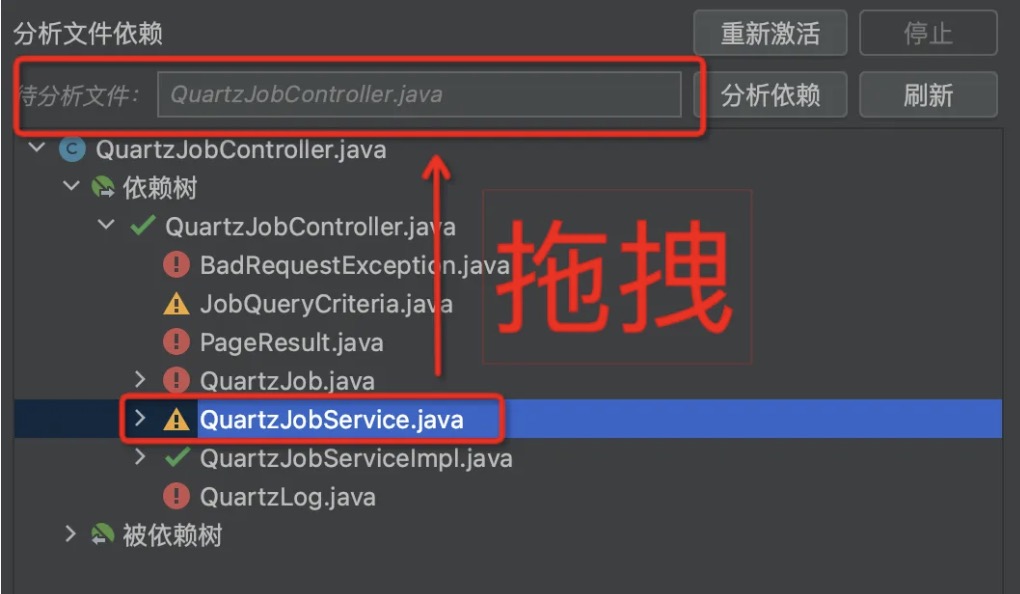 | |
| 不应该移入模块 | 鼠标悬停,查看该类被依赖情况 |
步骤四:根据提示,通过拖拽,一步步分析,导入需要的模块文件
5. 检测
点击初步检测,将提示用户此次拆分可能的问题,以及哪些中间件需要人工。
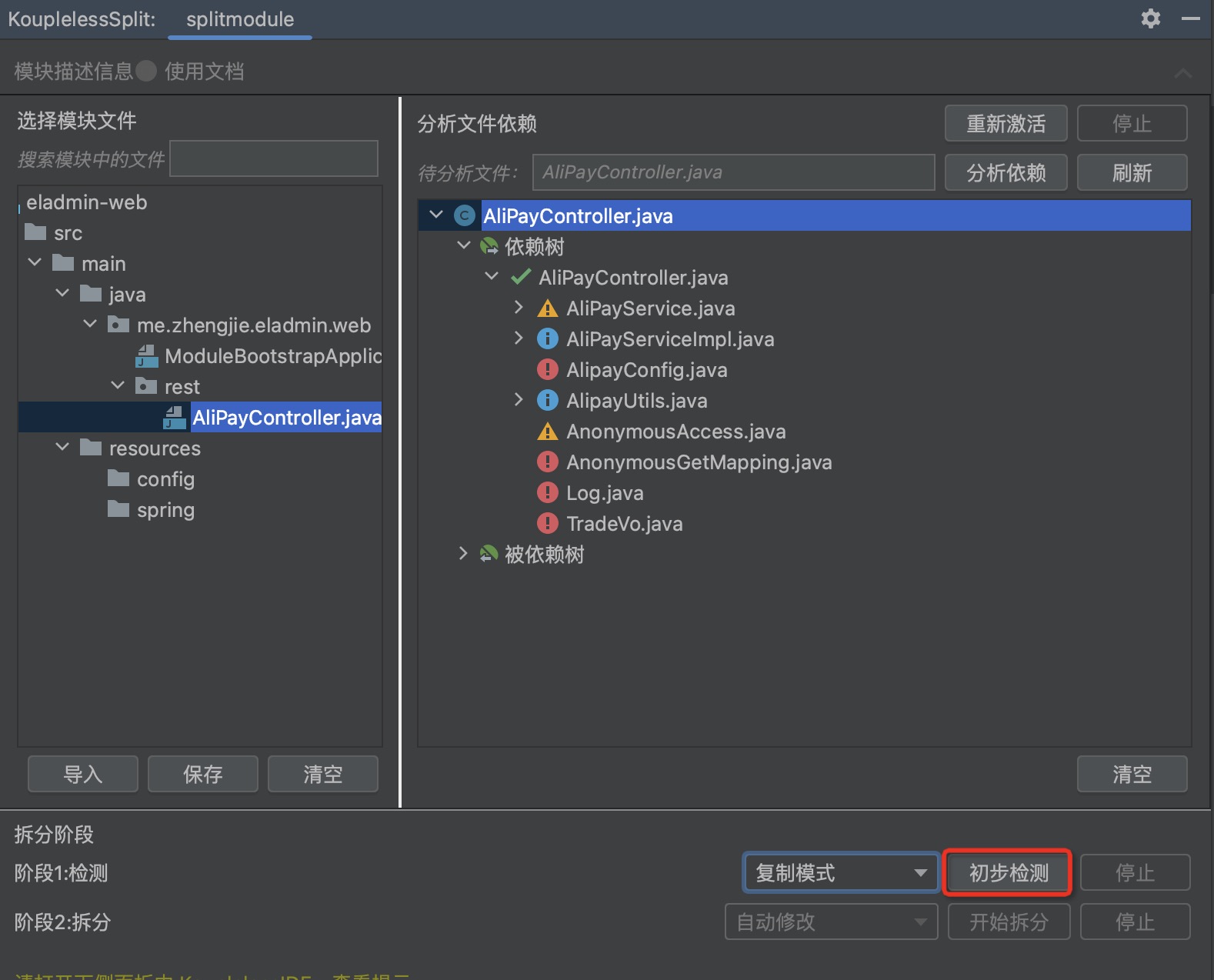
打开下侧面板中 KouplelessIDE,查看提示。
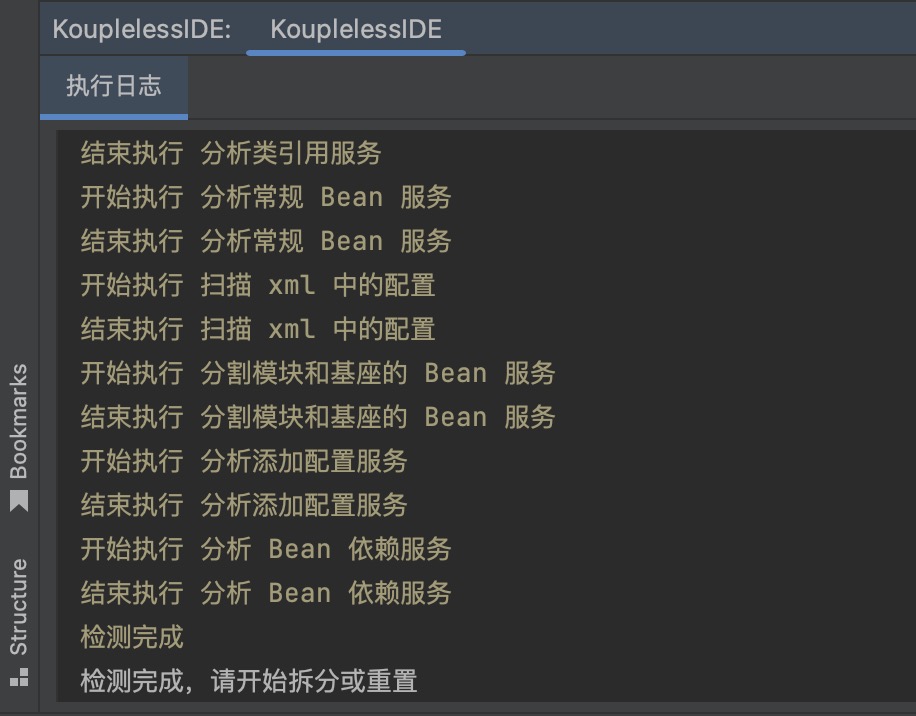
6. 拆分
点击开始拆分。
打开下侧面板中 KouplelessIDE,查看提示。

5.4.2 - 6.5.4.2 单体应用协作开发太难?Koupleless 带来拆分插件,帮你抽丝剥茧提高协作开发效率!
背景
你的企业应用协作效率低吗?
明明只改一行,但代码编译加部署要十分钟;
多人开发一套代码库,调试却频频遇到资源抢占和相互覆盖,需求上线也因此相互等待……
当项目代码逐渐膨胀,业务逐渐发展,代码耦合、发布耦合以及资源耦合的问题日益加重,开发效率一降再降。
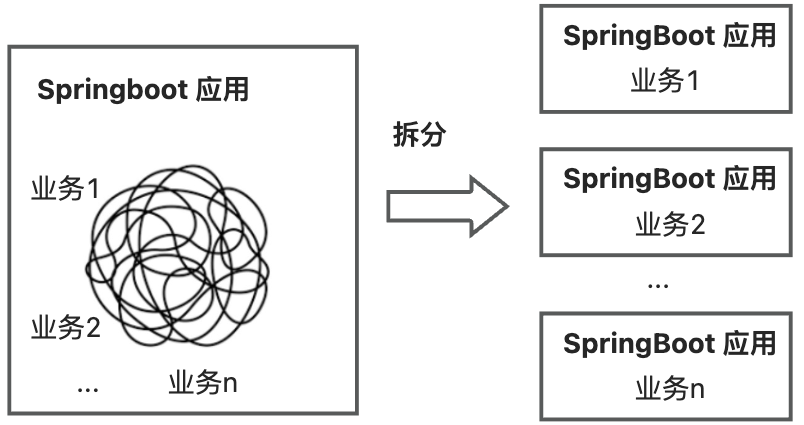
如何解决?来试试把单个 Springboot 应用拆分为多个 Springboot 应用吧!拆出后,多个 Springboot 应用并行开发,互不干扰。在 Koupleless 模式下,业务可以将 Springboot 应用拆分成一个基座和多个 Koupleless 模块(Koupleless 模块也是 Springboot 应用)。
🙌拉到「Koupleless 拆分插件解决方案」部分,可直接查看单体应用拆分的插件演示视频!
关键挑战
从单个 Springboot 应用拆出 多个 Springboot 应用有三大关键挑战:
一是拆子应用前,复杂单体应用中代码耦合高、依赖关系复杂、项目结构复杂,难以分析各文件间的耦合性,更难从中拆出子应用,因此需要解决拆分前复杂单体应用中的文件依赖分析问题。
二是拆子应用时,拆出操作繁琐、耗时长、用户需要一边分析依赖关系一边拆出,对用户要求极高,因此需要降低拆分时用户交互成本。
三是拆子应用后,单体应用演进为多应用共存,其编码模式会发生改变。Bean 调用方式由单应用调用演进为跨应用调用,特殊的多应用编码模式也需根据框架文档调整,比如在 koupleless 中,为了减少模块的数据源连接,模块会按照某种方式使用基座的数据源,其学习成本与调整成本极高,因此需要解决拆分后多应用编码模式演进问题。
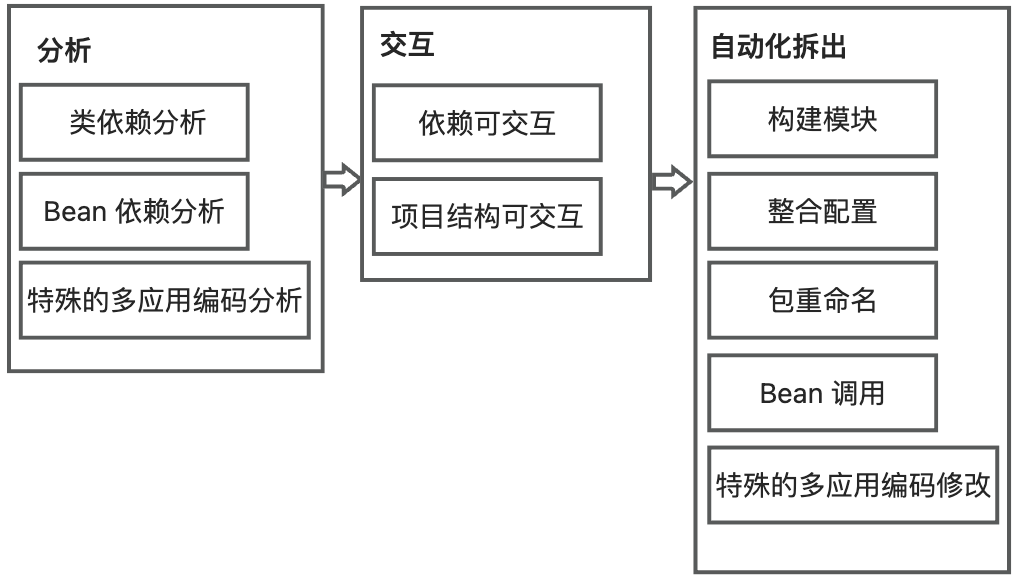
Koupleless 拆分插件解决方案
针对以上三大关键挑战,Koupleless IntelliJ IDEA 插件将解决方案分为 3 个部分:分析、交互和自动化拆出,提供依赖分析、友好交互和自动化拆出能力,如下图:
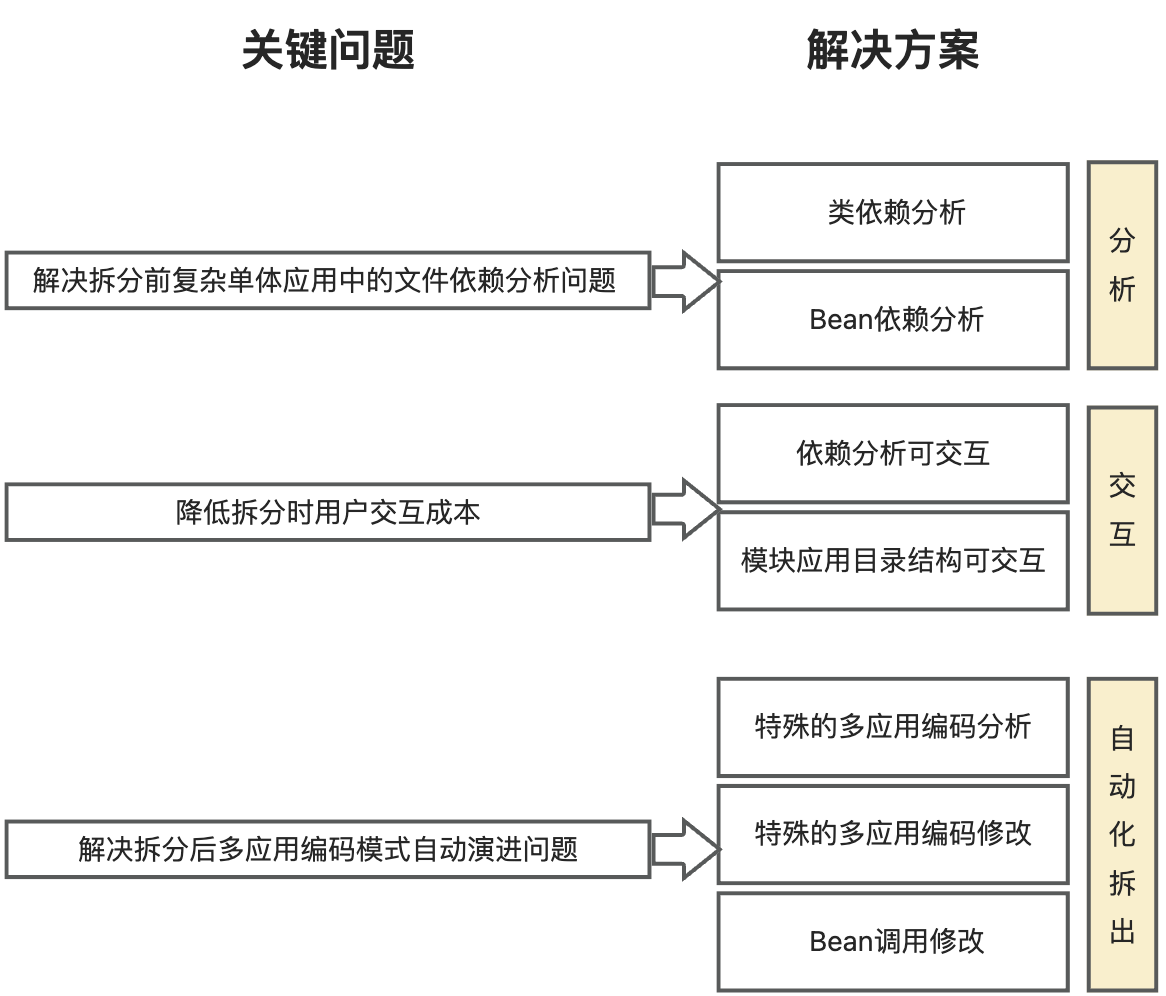
- 在分析中,分析项目中的依赖关系,包括类依赖和Bean依赖分析,解决拆分前复杂单体应用中的文件依赖分析问题;
- 在交互中,可视化类文件之间的依赖关系,帮助用户梳理关系。同时,可视化模块目录结构,让用户以拖拽的方式决定要拆分的模块文件,降低拆分时的用户交互成本;
- 在自动化拆出中,插件将构建模块,并根据特殊的多应用编码修改代码,解决拆分后多应用编码模式演进问题。
🙌 此处有 Koupleless 半自动拆分演示视频,带你更直观了解插件如何在分析、交互、自动化拆出中提供帮助。
一个示例 秒懂 Koupleless 解决方案优势
假设某业务需要将与 system 相关的代码都拆出到模块,让通用能力保留在基座。这里我们以 system 的入口服务 QuartzJobController 为例。
步骤一:分析项目文件依赖关系
首先,我们会分析 QuartzJobController 依赖了哪些类和 Bean。
方式一:使用 Idea 专业版,对 Controller 做 Bean 分析和类分析,得到以下 Bean 依赖图和类依赖关系图
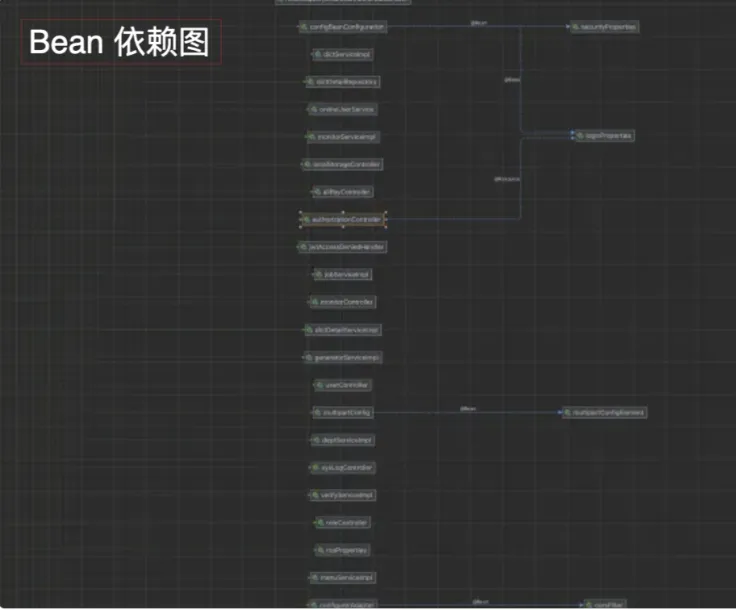 |  |
|---|
- 优势:借助 IDEA 专业版,分析全面
- 劣势:需要对每个类文件都做一次分析,Bean 依赖图可读性不强。
方式二:凭借脑力分析
当 A 类依赖了B、C、D、…、N类,在拆出时需要分析每一个类有没有被其它类依赖,能不能够拆出到模块应用。
- 优势:直观
- 劣势:当 A 的依赖类众多,需要层层脑力递归。
方式三:使用 Koupleless 辅助工具,轻松分析!
选择你想要分析的任意类文件,点击“分析依赖”,插件帮你分析~ 不仅帮你分析类文件依赖的类和 Bean,还提示你哪些类可以拆出,哪些类不能拆出。 以 QuartzJobController 为例,当选定的模块中有 QuartzJobController, QuartzJobService 和 QuartzJobServiceImpl 时,QuartzJobController 依赖的类和Bean关系如下图所示:
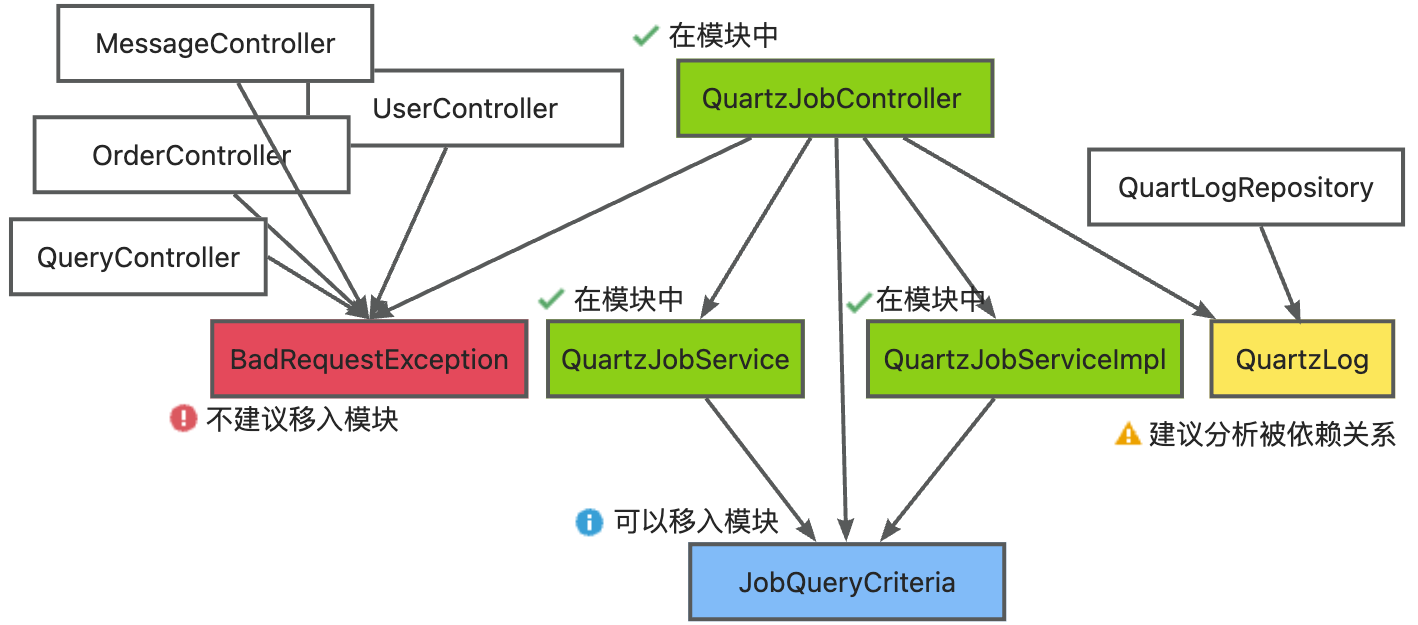
QuartzJobController 的依赖类/Bean 分为四类:已在模块、可移入模块、建议分析被依赖关系和不建议移入模块:
- 如果在模块中,则被标记为绿色“已在模块”,如: QuartzJobService 和 QuartzJobServiceImpl;
- 如果只被模块类依赖,那么被标记为蓝色“可移入模块”,如 JobQueryCriteria;
- 如果只被一个非模块类依赖,那么被标记为黄色“建议分析被依赖关系”,如 QuartLog;
- 如果被大量非模块类依赖,那么被标记为红色“不建议移入模块”,如 BadRequestException。
当使用插件对 QuartzJobController 和 JobQueryCriteria 进行分析时,依赖树和被依赖树如下,与上述分析对应:
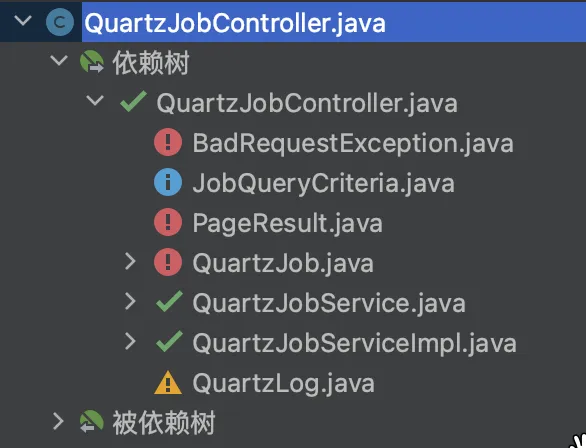 |  |
|---|
- 优势:直观、操作便捷、提示友好
- 劣势:插件只支持分析常见的 Bean 定义和类引用
步骤二:拆出到模块&修改单应用编码为多应用编码模式
选择相关的类文件拆出到模块。
方式一:复制粘贴每个文件、脑力分析所有模块基座之间的Bean调用、根据多应用编码模式修改代码。
在拆出时容易有灵魂发问:刚拆到哪儿了?这文件在没在模块里?我要不要重构这些包名?Bean调用跨应用吗?多应用编码的文档在哪?
- 优势:可以处理插件无法处理的多应用编码模式
- 劣势:用户不仅需要分析跨应用Bean依赖关系,还需要学习多应用编码方式,人工成本较高。
方式二:使用 Koupleless 辅助工具,轻松拆出!
根据你想要的模块目录结构,拖拽需要拆出的文件至面板。点击“拆出”,插件帮你分析,帮你根据 Koupleless 多应用编码模式修改~
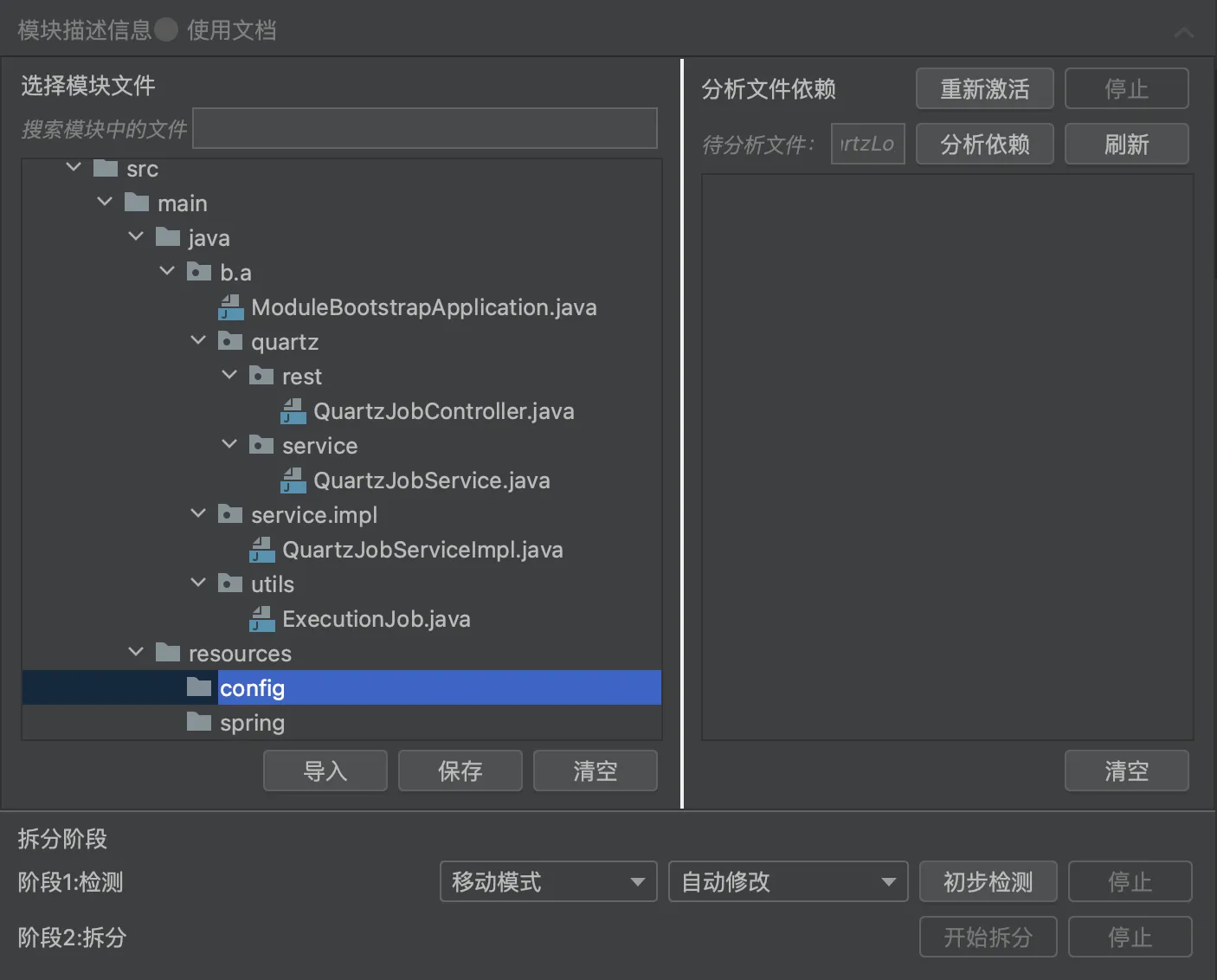
- 优势:直观、交互方便、插件自动修改跨应用 Bean 调用方式和部分特殊的多应用编码模式
- 劣势:插件只能根据部分多应用编码模式修改代码,因此用户需要了解插件能力的范围
技术方案
插件将整体流程分为 3 个阶段:分析阶段、交互阶段和自动化拆出阶段,整体流程如下图所示:
在分析阶段中,分析项目中的依赖关系,包括类依赖、Bean 依赖和特殊的多应用编码分析,如:MyBatis 配置依赖;
在交互阶段,可视化类文件之间的依赖关系和模块目录结构;
在自动化拆出阶段,插件首先将构建模块并整合配置,然后根据用户需要重构包名,接着修改模块基座 Bean 调用方式,并根据特殊的多应用编码修改代码,如:自动复用基座数据源。
接下来,我们将简单介绍分析阶段、交互阶段和自动化拆出阶段的主要技术。
分析阶段
插件分别使用 JavaParser 和 commons-configuration2 扫描项目中的 Java 文件和配置文件。
类依赖分析
为了准确地分析出项目的类依赖关系,插件需要完整分析一个类文件代码中所有使用到的项目类,即:分析代码中每个涉及类型的语句。
插件首先扫描所有类信息,然后用 JavaParser 扫描每一个类的代码代码,分析它依赖的项目类文件所有涉及类型的语句,并解析涉及到的类型,最后记录其关联关系。涉及类型的语句如下:
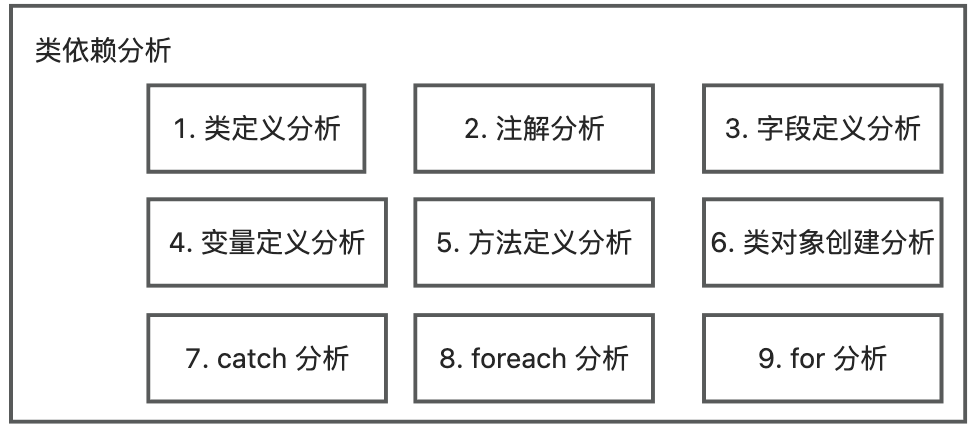
- 类定义分析: 解析父类类型和实现接口类型,作为引用的类型;
- 注解分析:解析注解类型,作为引用的类型;
- 字段定义分析:解析字段类型,作为引用的类型;
- 变量定义分析:解析变量类型,作为引用的类型;
- 方法定义分析:解析方法的返回类型、入参类型、注解以及抛出类型,作为引用的类型;
- 类对象创建分析:解析类对象创建语句的对象类型,作为引用的类型;
- catch分析:解析 catch 的对象类型,作为引用的类型;
- foreach分析:解析 foreach 的对象类型,作为引用的类型;
- for分析:解析 for 的对象类型,作为引用的类型;
为了快速解析对象类型,由于直接使用 JavaParser 解析较慢,因此先通过 imports 解析是否有匹配的类型,如果匹配失败,则使用 JavaParser 解析。
Bean 依赖分析
为了准确地分析出项目的Bean依赖关系,插件需要扫描项目中所有的 Bean 定义和依赖注入方式,然后通过静态代码分析的方式解析类文件依赖的所有项目 Bean。
Bean 定义主要有三种方式:类名注解、方法名注解和 xml。不同方式的 Bean 定义对应着不同的 Bean 依赖注入分析方式,最终依赖的 Bean 又由依赖注入类型决定,整体流程如下:
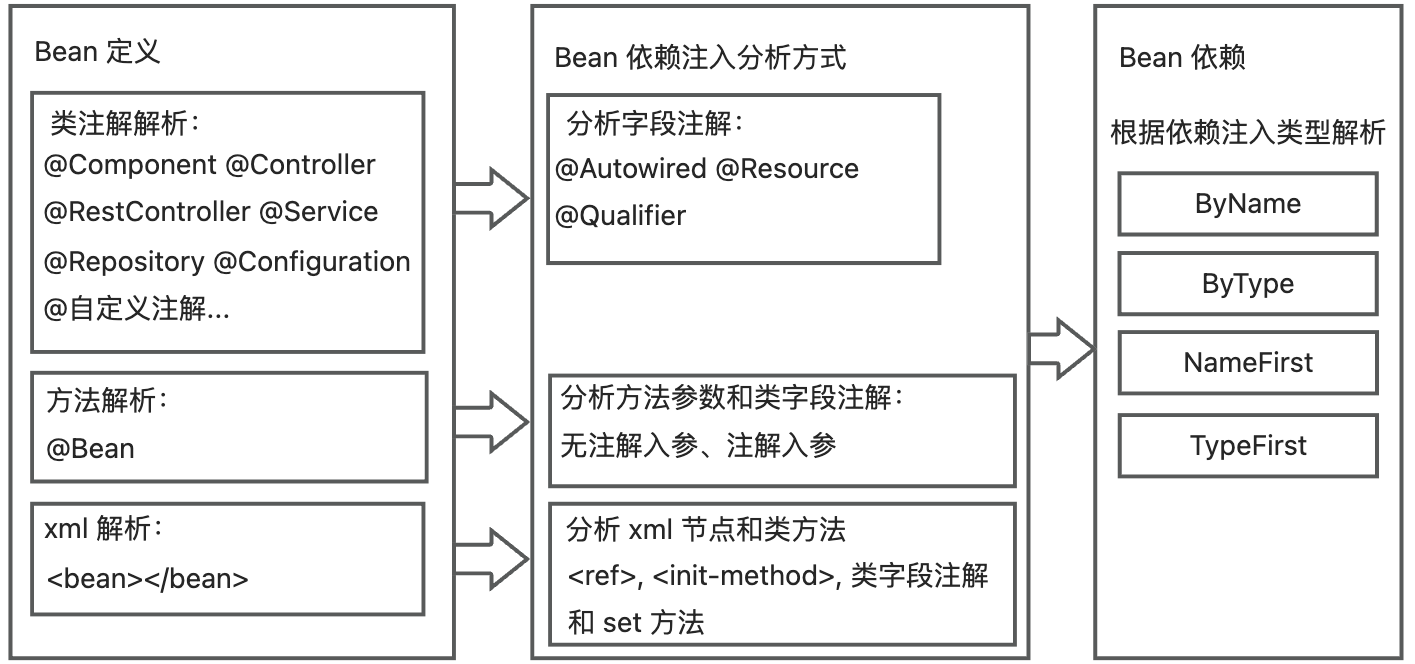
在扫描 Bean 时,解析并记录 bean 信息、依赖注入类型和依赖的Bean信息。
- 对于以类注解定义的类,将以字段注解,解析该字段的依赖注入类型和依赖的Bean信息。
- 对于以方法定义的类,将以入参信息,解析该入参数的依赖注入类型和依赖的Bean信息。
- 对于以 xml 定义的类,将通过解析 xml 和类方法的方式解析依赖注入:
- 以 和
解析 byName类型的依赖Bean信息 - 以字段解析依赖注入类型和依赖Bean信息。
- 如果 xml 的依赖注入方式不为 no,那么解析依赖注入类型和 set方法对应依赖Bean信息。
- 以 和
最后按照依赖注入类型,在项目记录的Bean定义中查找依赖的Bean信息,以实现Bean依赖关系的分析。
特殊的多应用编码分析
这里我们以 MyBatis 配置依赖分析为例。
在拆出 Mapper 至模块时,模块需要复用基座数据源,因此插件需要分析 Mapper 关联的所有 MyBatis 配置类。MyBatis 的各项配置类和 Mapper 文件之间通过 MapperScanner 配置连接,整体关系如下图:
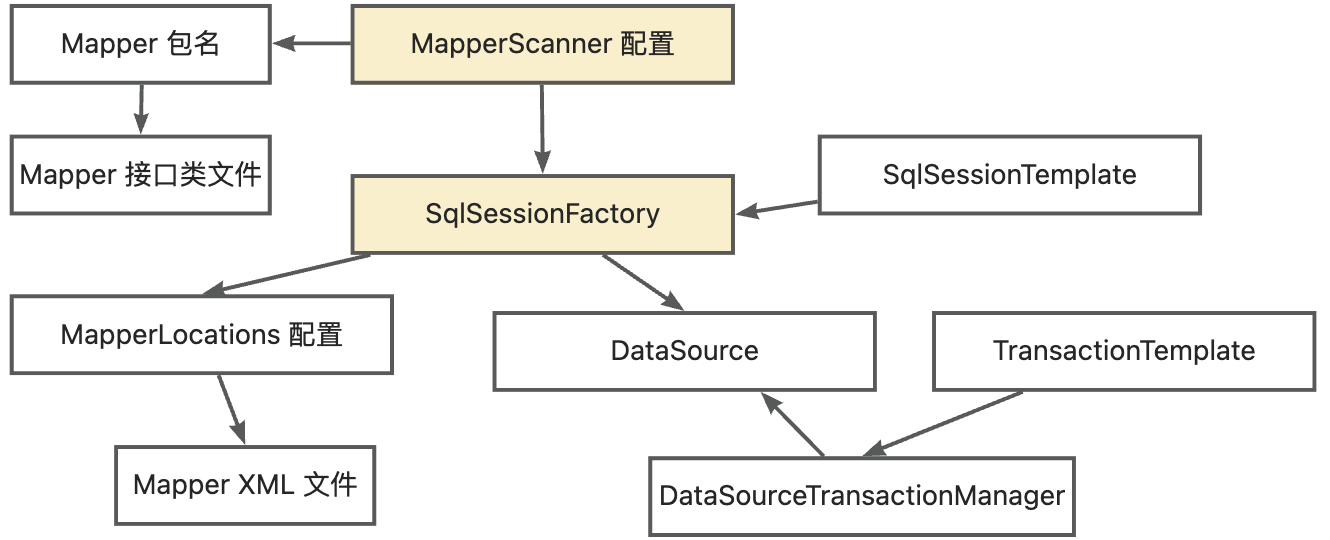
因此,插件记录所有的 Mapper 类文件和 XML 文件,解析与之关联的 MapperScanner,并解析与 MapperScanner 配置关联的所有 Mybatis 配置 Bean 信息。
交互阶段
这里简述依赖关系可视化和跨层级导入的实现。
- 可视化依赖关系:插件通过递归的方式解析所有类文件之间的依赖关系(包括类依赖关系和 Bean 依赖关系)。由于类文件间可能有循环依赖,因此使用缓存记录所有类文件节点。在递归时优先从缓存中取依赖节点,避免导致构建树节点时出现栈溢出问题。
- 跨层级导入:记录所有标记的选中文件,如果需选中了文件夹及文件夹中文件,导入时只导入标记过的文件。
自动化拆出阶段
这里简述包重命名、配置整合、Bean调用和特殊的多应用编码修改(以“复用基座数据源”为例)的实现。
- 包重命名:当用户自定义包名时,插件将修改类包名,并根据类依赖关系,将其 import 字段修改为新包的名称。
- 配置整合:针对子应用的每一个模块,读取所有拆出文件所在的原模块配置,并整合到新模块中;自动抽出子应用相关的 xml 的 bean 节点。
- Bean 调用:由上文分析的 Bean 依赖关系,插件过滤出模块和基座之间的 Bean 调用,并将字段注解(@Autowired @Resource @Qualifier) 修改为 @AutowiredFromBase 或 @AutowiredFromBiz
- 基座数据源复用:根据用户选择的 Mapper 文件及 MyBatis 配置依赖关系,抽取该 Mapper 相关的MyBatis 配置信息。然后把配置信息填充至数据源复用模板文件,保存在模块中。
未来展望
当前在内部已经完成上述功能开发,但还未正式开源,预计 2024年上半年将开源,敬请期待。
此外,在功能上,未来还需解决更多挑战:如何解决单测的拆分,如何验证拆出的多应用能力与单应用能力一致性。
欢迎更多感兴趣的同学关注 Koupleless 社区共同建设 Koupleless 生态。
6 - 6.6 ModuleController 技术文档
6.1 - 6.6.1 ModuleControllerV2 架构设计
简要介绍
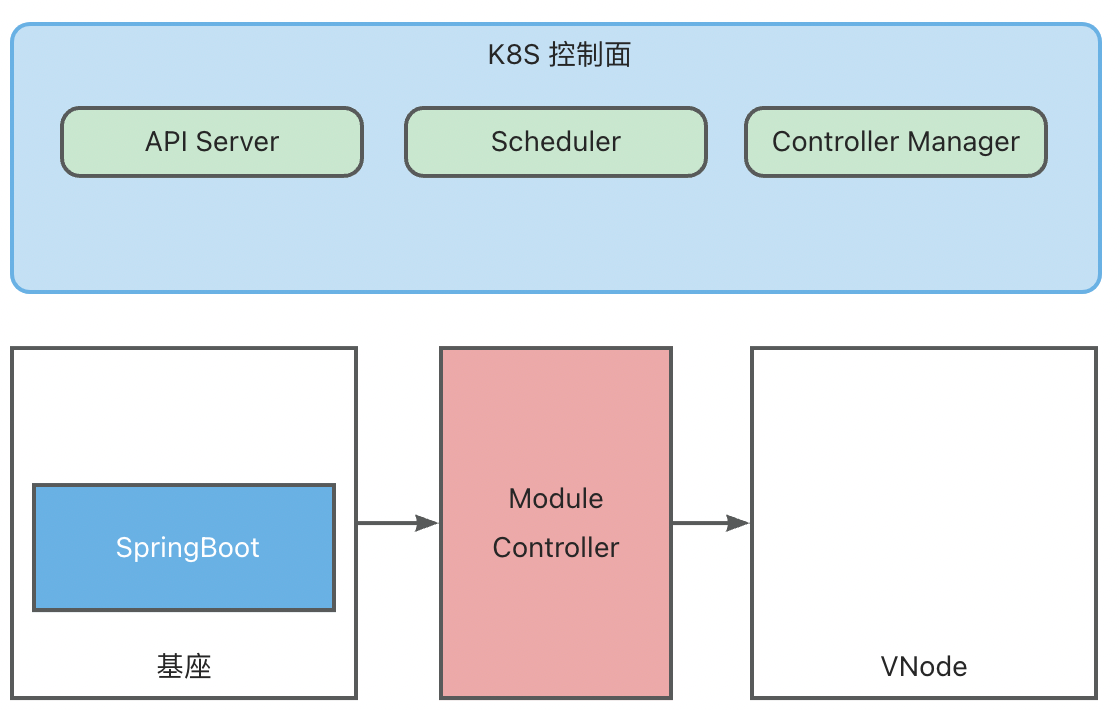
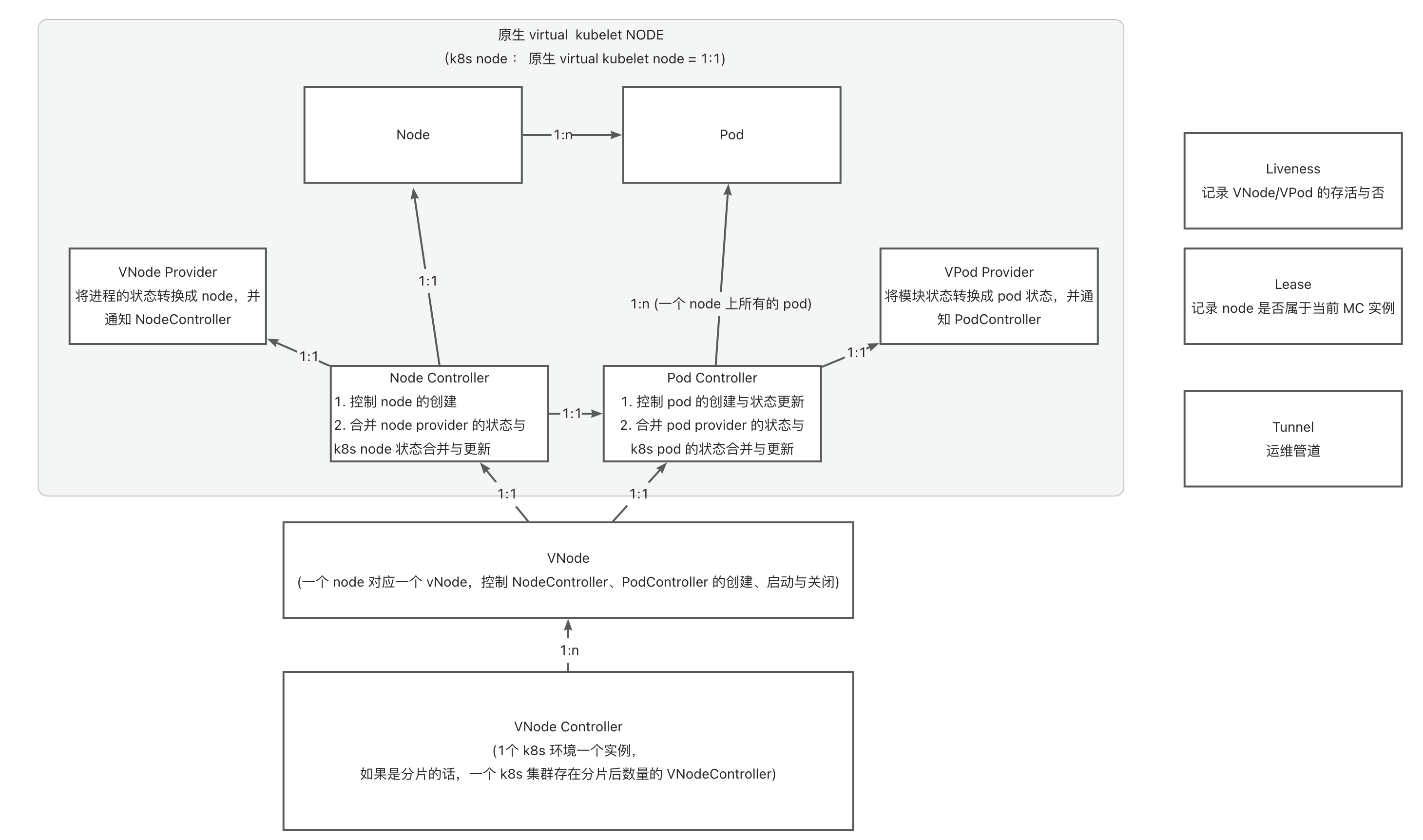
ModuleControllerV2 是一个 K8S 控制面组件,基于Virtual Kubelet能力,将基座伪装成K8S体系中的node,将模块映射为K8S体系中的Container,从而将模块运维映射成为Pod的运维,基于K8S包含的Pod生命周期管、调取,以及基于Pod的Deployment、DaemonSet、Service等现有控制器,实现了 Serverless 模块的秒级运维调度,以及与基座的联动运维能力。
背景
原有的Module Controller(以下称之为MC)基于K8S Operator技术设计。 在这种模式下,原有的MC从逻辑上是定义了另外一套与基座隔离的,专用的模块控制面板,从逻辑上将模块与基座分成了两个相对独立的类别进行分别的运维,即基座的运维通过K8S的原生能力进行运维,模块运维通过Operator封装的运维逻辑进行运维。
这样的构建方法在逻辑上很清晰,对模块和基座的概念进行了区分,但是也带来了一定的局限性:
首先由于逻辑上模块被抽象成了不同于基座模型的另一类代码,因此原来的MC除了要实现在基座上进行模块的加载、卸载以外,还需要:
- 感知当前所有的基座
- 维护基座状态(基座在线状态、模块加载情况、模块负载等)
- 维护模块状态(模块在线状态等)
- 根据业务需要实现相应的模块调度逻辑
这将为带来巨大的开发与维护成本。(单场景的Operator开发成本高)
模块能力与角色横向扩展困难。这种实现方式从逻辑上是与原先比较常见的微服务架构是相互不兼容的,微服务架构不同微服务之间的角色是相同的,然而在Operator的实现中,模块与基座的抽象层级是不同的,两者不能互通。 以Koupleless所提出的:“模块既可以以模块的形式attach到基座上,也可以以服务的形式单独运行”为例,在Operator架构下,如果想实现后者的能力,就需要单独为这种需求定制一套全新的调度逻辑,至少需要定制维护特定的依赖资源,才能够实现,这样未来每需要一种新的能力/角色,都需要定制开发大量的代码,开发维护成本很高。(横向扩展的开发成本高)
在这种架构下,模块成为了一种全新的概念,从产品的角度,会增大使用者的学习成本。
架构
ModuleControllerV2 目前包含Virtual Kubelet Manager控制面组件和Virtual Kubelet组件。Virtuakl Kubelet组件是Module Controller V2的核心,负责将基座服务映射成一个node,并对其上的Pod状态进行维护,Manager维护基座相关的信息,监听基座上下线消息,关注基座的存活状态,并维护Virtual Kubelet组件的基本运行环境。
Virtual Kubelet
Virtual Kubelet参考了官方文档 的实现
一句话做一个总结就是:VK是一个可编程的Kubelet。
就像在编程语言中的概念,VK是一个Kubelet接口,定义了一组Kubelet的标准,通过对VK这一接口进行实现,我们就可以实现属于我们自己的Kubelet。
K8S中原有的运行在Node上的Kubelet就是对VK的一种实现,通过实现VK中抽象的方法从而使得K8S控制面能够对Node上物理资源的使用与监控。
因此VK具有伪装成为Node的能力,为了区分传统意义上的Node和VK伪装的Node,下面我们将VK伪装的Node称为VNode。
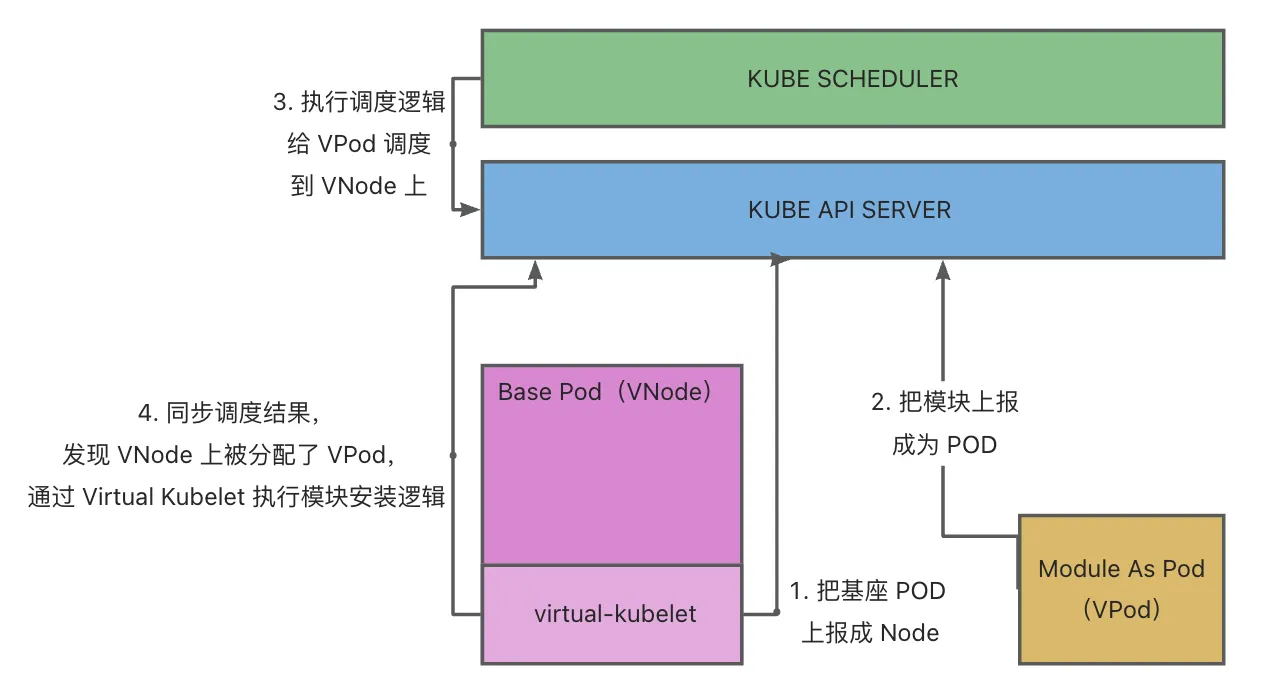
逻辑结构
在Koupleless的架构中,基座服务运行在Pod中,这些Pod由K8S进行调度与维护,分配到实际的Node上运行。
对模块调度的需求实际上和基座的调度是一致的,因此在MC V2的设计中,使用VK将基座服务伪装成传统K8S中的Node,变成基座VNode,将模块伪装成Pod, 变成模块VPod,从逻辑上抽象出第二层K8S用于管理VNode和VPod。
综上,在整体架构中会将包含两个逻辑K8S:
- 基座K8S:维护真实Node(虚拟机/物理机),负责将基座Pod调度到真实Node上
- 模块K8S:维护虚拟VNode(基座Pod), 负责将模块VPod调度到虚拟VNode上
之所以称之为逻辑K8S是因为两个K8S不一定需要是真实的两个分离的K8S,在隔离做好的情况下,可以由同一个K8S完成两部分任务。
通过这种抽象,我们就可以在不对框架做额外开发的前提下,复用K8S原生的调度和管理的能力实现:
- 基座VNode的管理(非核心能力,因为其本身就是底层K8S中的一个Pod,可以由底层K8S来维护状态,但作为Node也将包含更多的信息)
- VPod的管理(核心能力:包含模块运维,模块调度、模块生命周期状态维护等)
多租户VK架构
原生的VK基于K8S的Informer机制和ListWatch实现当前vode上pod事件的监听。但是这样也就意味着每一个vnode都需要启动一套监听逻辑,这样,随着基座数量的增加,APIServer的压力会增长的非常快,不利于规模的横向扩展。
为了解决这一问题,Module Controller V2基于Virtual Kubelet,将其中的ListWatch部分抽取出来,通过监听某一类Pod(具体实现中为包含特定label的Pod)的事件,再通过进程内通信的方式将事件转发到逻辑VNode上进行处理的方式实现Informer资源的复用,从而只需要在各VNode中维护本地上下文,而不需要启动单独的监听,降低APIServer的压力。
多租户架构下,Module Controller V2中将包含两个核心模块:
- 基座注册中心:这一模块通过特定的运维管道进行基座服务的发现,以及VK的上下文维护与数据传递。
- VK:VK保存着某个具体基座和node,pod之间的映射,实现对node和pod状态的维护以及将pod操作翻译成为对应的模块操作下发至基座。
分片架构
单点的Module Controller很显然缺乏容灾能力,并且单点的上限也很明显,因此Module Controller V2需要一套更加稳定,具备容灾和水平扩展能力的架构。
在模块运维中我们核心关注的问题是调度能力的稳定性,而在 Module Controller 当前架构下,调度的稳定性包含两个部分:
- 所依赖 K8S 的稳定性
- 基座稳定性
其中第一条无法在 Module Controller 这一层进行保证,因此 Module Controller 的高可用只关注基座层级的稳定性。
除此之外,Module Controller 的负载主要体现在对各类 Pod 事件的监听和处理,与 Pod 数量和所接管的基座数量相关,由于 K8S API Server 对单客户端的访问速率限制,导致单个 Module Controller 实例能够同时处理的事件有上限,因此同时还需要在 Module Controller 层级建设负载分片能力。
因此 Module Controller 的分片架构核心关注两个问题:
- 基座的高可用
- Pod 事件的负载均衡
而在 Module Controller 的场景下,Pod 事件与基座是强绑定的,因此实际上对 Pod 事件的负载均衡等同于所接管基座的均衡。
为了解决上述问题,Module Controller 在多租户 Virtual Kubelet 上建设了原生的分片能力,具体逻辑如下:
- 每一个 Module Controller 实例都会监听所有基座的上线信息
- 监听到基座的上线之后,每一个 Module Controller 都会创建对应的 VNode 数据,并尝试创建 VNode 的 node lease
- 由于 K8S 中同名资源的冲突性,在这一过程中只会有一个 Module Controller 实例成功创建了 Lease,此时这一 Module Controller 所持有的 VNode 就会变成主实例,而其他创建失败的 Module Controller 所持有的同一个 VNode 就会变成副本,持续对 Lease 对象进行监听,尝试重新抢主,从而实现了 VNode 的高可用
- VNode 成功启动之后会监听调度到其上的 Pod,进行交互,而未成功启动的 VNode 会忽略掉这些事件,从而实现了 Module Controller 的负载分片
因此最终形成架构:多 Module Controller 之间基于 Lease 对 VNode 负载进行分片,多 Module Controller 通过多 VNode 数据实现 VNode 的高可用。
除此之外,我们还期望多个 Module Controller 之间能够尽可能负载均衡,即每一个 Module Controller 所持有的基座数量大致均衡。
为了方便开源用户使用,降低学习成本,我们尽量在不引入额外组件的情况下基于 K8S 实现了一套自均衡能力:
- 首先每一个 Module Controller 实例都会维护自身当前工作负载,计算规则为 (当前接管的VNode数量 / 所有VNode数量),例如,当前 Module Controller 接管 3 个 VNode,集群中共有 10 个 VNode 的情况,实际工作负载即为 3/ 10 = 0.3
- 在 Module Controller 启动的时候可以指定最大工作负载等级,Module Controller 会根据这一参数将工作负载分为对应片数,例如最大工作负载等级若指定为 10,那么每个工作负载等级将会包含 1/10 的区间,即 工作负载 0-0.1 将定义为 工作负载=0,0.1-0.2 定义为 工作负载=1,以此类推
- 在配置为分片集群的情况下,Module Controller 在尝试创建 Lease 之前会首先计算当前自身的工作负载等级,根据工作负载等级进行不同程度的等待,之后再进行创建。在这种情况下,低工作负载的 Module Controller 会更早的尝试创建,创建成功的概率提高,从而实现负载均衡
以上的过程实际上基于 K8S 事件的广播机制设计,而在基座首次上线时,根据所选择运维管道的不同,还需要进行另外的考虑:
- MQTT 运维管道:由于 MQTT 本身就具有广播能力,所有 Module Controller 实例都会接收到 MQTT 上线消息,不需要额外配置
- HTTP 运维管道:HTTP 请求的特殊性使得基座在上线的时候只会与某一个 Module Controller 实例进行交互,那么此时初次上线时的负载均衡就需要通过其他能力实现。在实际部署中,多个 Module Controller 需要通过一个代理 (K8S Service/ Nginx等 )来对外提供服务,因此可以在代理层上配置负载均衡策略,实现初次上线过程中的均衡。
6.2 - 6.6.2 ModuleControllerV2 原理
模块运维架构
简要介绍
Module Controller V2 基于 Virtual Kubelet 能力,实现将基座映射为 K8S 中的 Node,进而通过将 Module 定义为 Pod 实现对 K8S 调度器以及各类控制器的复用,快速搭建模块运维调度能力。
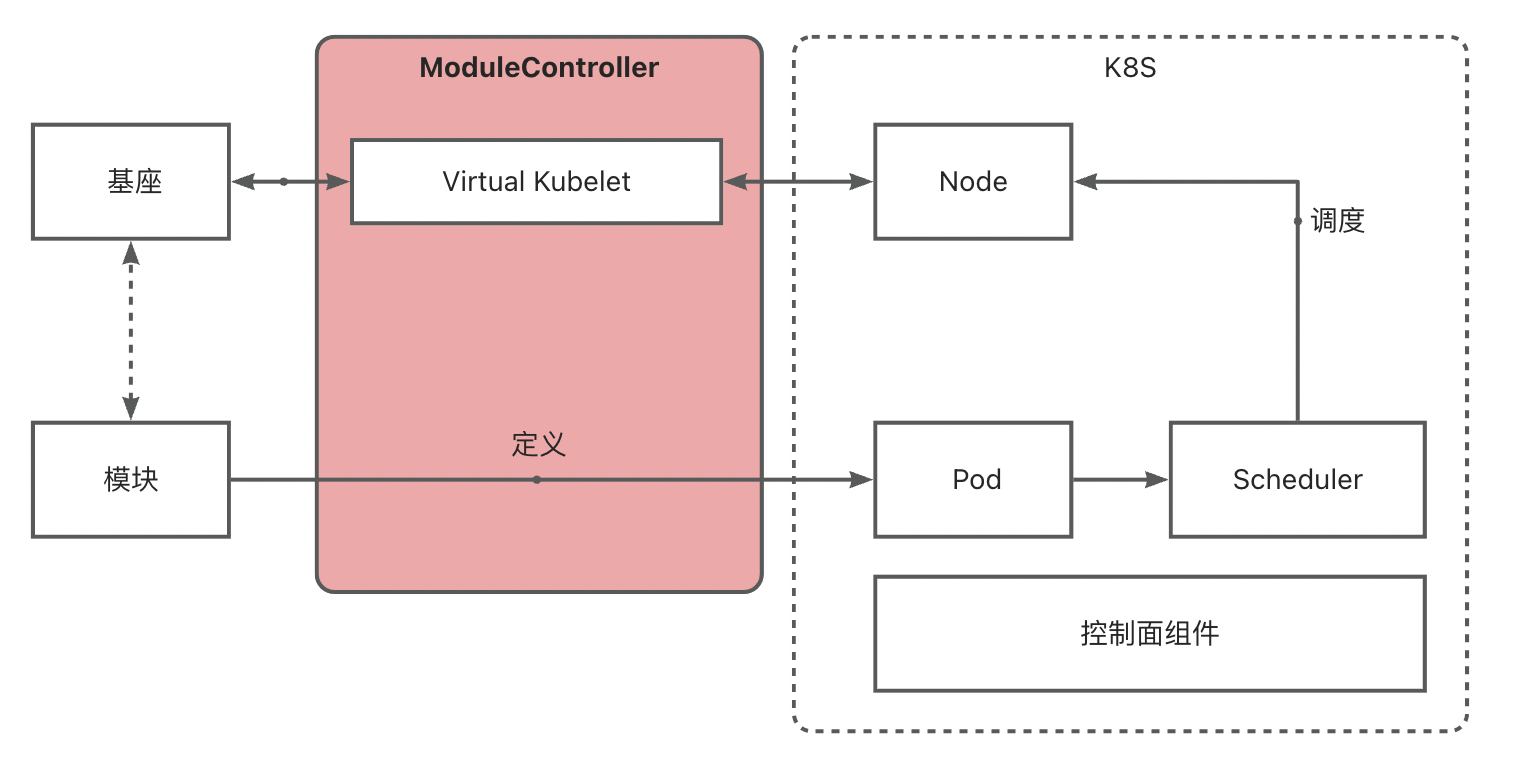
基座 <-> VNode 映射
Module Controller V2 通过 Tunnel 实现基座发现,基座发现后将会通过 Virtual Kubelet 将其伪装成 Node,以下称此类伪装的 Node 为 VNode。
基座发现时将读取基座中所配置的 Metadata 和 Network 信息,其中 Metadata 包含 Name 和 Version,Network 包含 IP 和 Hostname 信息。
Metadata 信息将变成 VNode 上的 Label 信息,用于标识基座信息, Network 信息将成为 VNode 的网络配置,未来调度到基座上的 module pod 将继承 VNode 的 IP, 用于配置 Service 等。
一个 VNode 还将包含以下关键信息:
apiVersion: v1
kind: Node
metadata:
labels:
virtual-kubelet.koupleless.io/component: vnode # vnode标记
virtual-kubelet.koupleless.io/env: dev # vnode环境标记
base.koupleless.io/name: base # 基座 Metadata 中的 Name 配置
vnode.koupleless.io/tunnel: mqtt_tunnel_provider # 基座当前归属 tunnel
base.koupleless.io/version: 1.0.0 # 基座版本号
name: vnode.2ce92dca-032e-4956-bc91-27b43406dad2 # vnode name, 后半部分为基座运维管道所生成的 uuid
spec:
taints:
- effect: NoExecute
key: schedule.koupleless.io/virtual-node # vnode 污点,防止普通 pod 调度
value: "True"
- effect: NoExecute
key: schedule.koupleless.io/node-env # node env 污点,防止非当前环境 pod 调度
value: dev
status:
addresses:
- address: 127.0.0.1
type: InternalIP
- address: local
type: Hostname
模块 <-> vPod 映射
Module Controller V2 将模块定义为 K8S 体系中的一个 Pod(为了区分,后续称为 vPod ),通过配置 Pod Yaml 实现丰富的调度能力。
一个模块 vPod 的 Yaml 配置如下:
apiVersion: v1
kind: Pod
metadata:
name: test-single-module-biz1
labels:
virtual-kubelet.koupleless.io/component: module # 必要,声明pod的类型,用于module controller管理
spec:
containers:
- name: biz1 # 模块名,需与模块 pom 中 artifactId 的配置严格对应
image: https://serverless-opensource.oss-cn-shanghai.aliyuncs.com/module-packages/stable/biz1-web-single-host-0.0.1-SNAPSHOT-ark-biz.jar # jar包地址,支持本地 file,http/https 链接
env:
- name: BIZ_VERSION # 模块版本配置
value: 0.0.1-SNAPSHOT # 需与 pom 中的 version 配置严格对应
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms: # 基座node选择
- matchExpressions:
- key: base.koupleless.io/version # 基座版本筛选
operator: In
values:
- 1.0.0 # 模块可能只能被调度到一些特殊版本的基座上,如有这种限制,则必须有这个字段。
- key: base.koupleless.io/name # 基座名筛选
operator: In
values:
- base # 模块可能只能被调度到一些特定基座上,如有这种限制,则必须有这个字段。
tolerations:
- key: "schedule.koupleless.io/virtual-node" # 确保模块能够调度到基座 vnode 上
operator: "Equal"
value: "True"
effect: "NoExecute"
- key: "schedule.koupleless.io/node-env" # 确保模块能够调度到特定环境的基座node上
operator: "Equal"
value: "test"
effect: "NoExecute"
上面的样例只展示了最基本的配置,另外还可以添加任意配置以实现丰富的调度能力,例如在 Module Deployment 发布场景中,可另外添加 Pod AntiAffinity 以防止模块的重复安装。
运维流程
基于上述结构与映射关系,我们就可以复用 K8S 原生的控制面组件,实现复杂多样的模块运维需求。
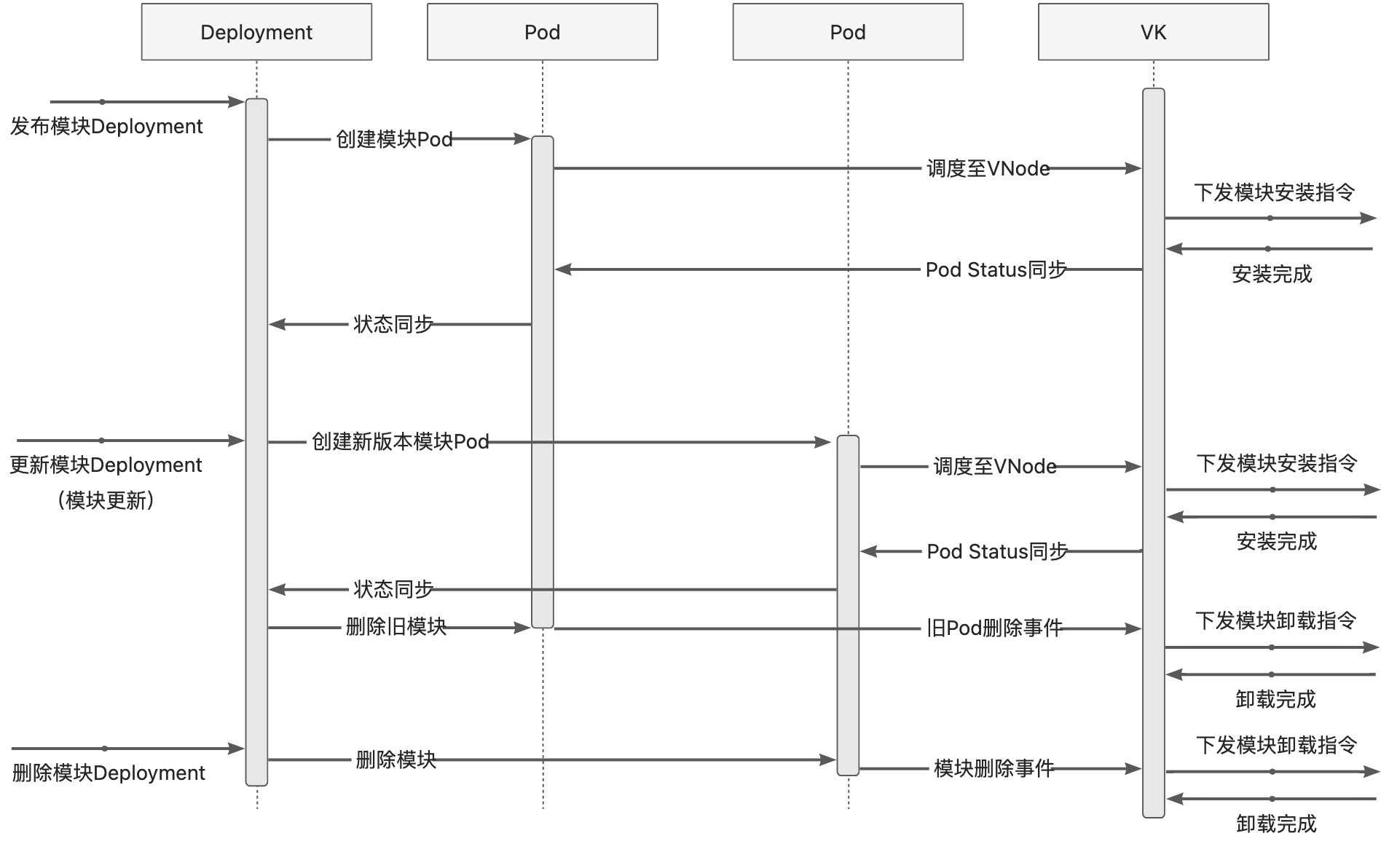
下面以模块 Deployment 为例展示整个模块运维流程,此时基座已完成启动与映射:
- 创建模块 Deployment (原生 K8S Deployment,其中 Template 中的 PodSpec 对模块信息进行了定义),K8S ControllerManager 中的 Deployment Controller 会根据 Deployment 配置创建模块vPod,此时 vPod 还未调度,状态为 Pending
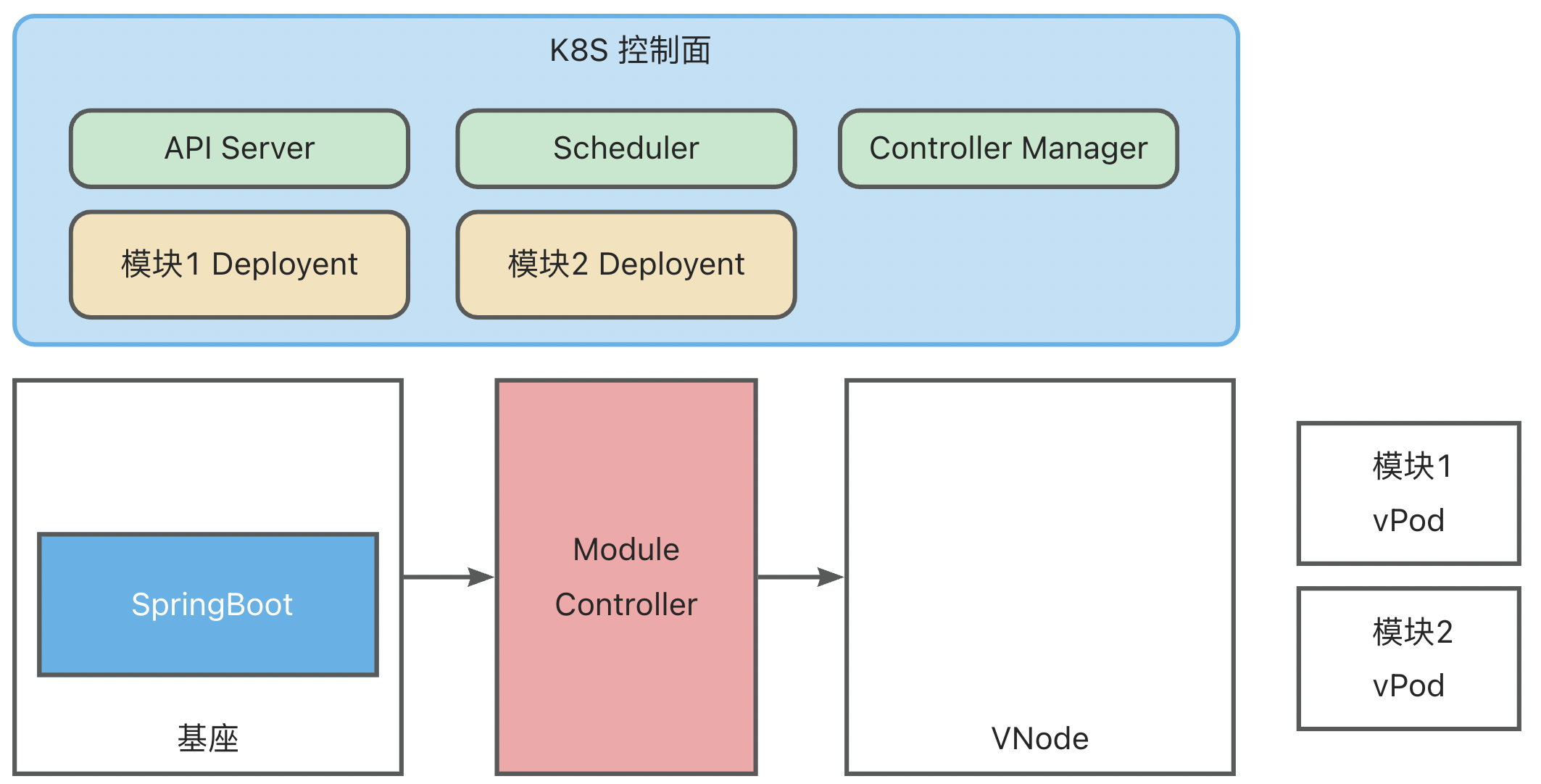
- K8S Scheduler 扫描未调度的 vPod,然后根据 selector、affinity、taint/toleration 配置将其调度到合适的 vNode 上
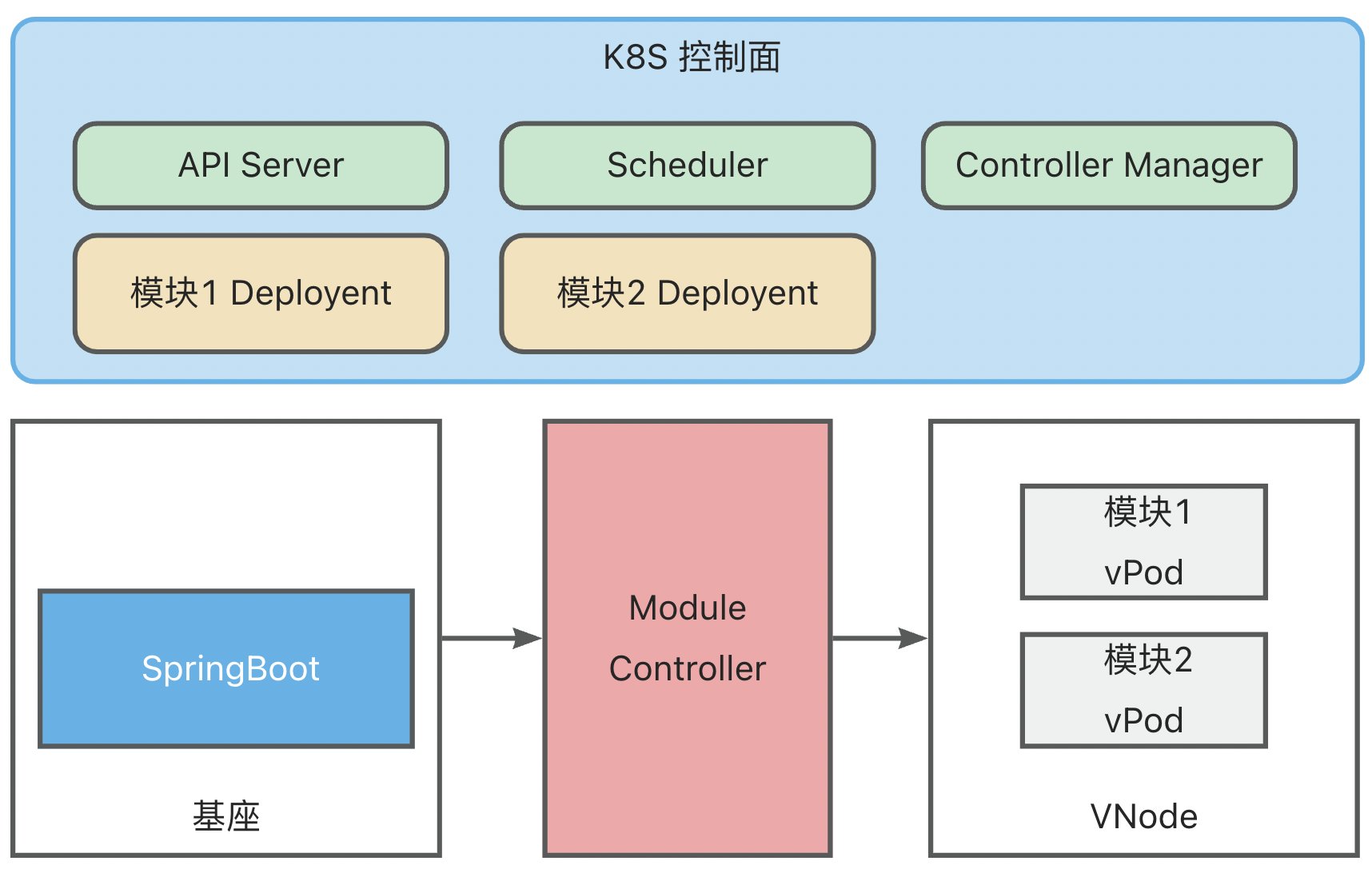
- Module Controller 监听到 vPod 完成调度,获取到 vPod 中定义的模块信息,将模块安装指令发送到基座上
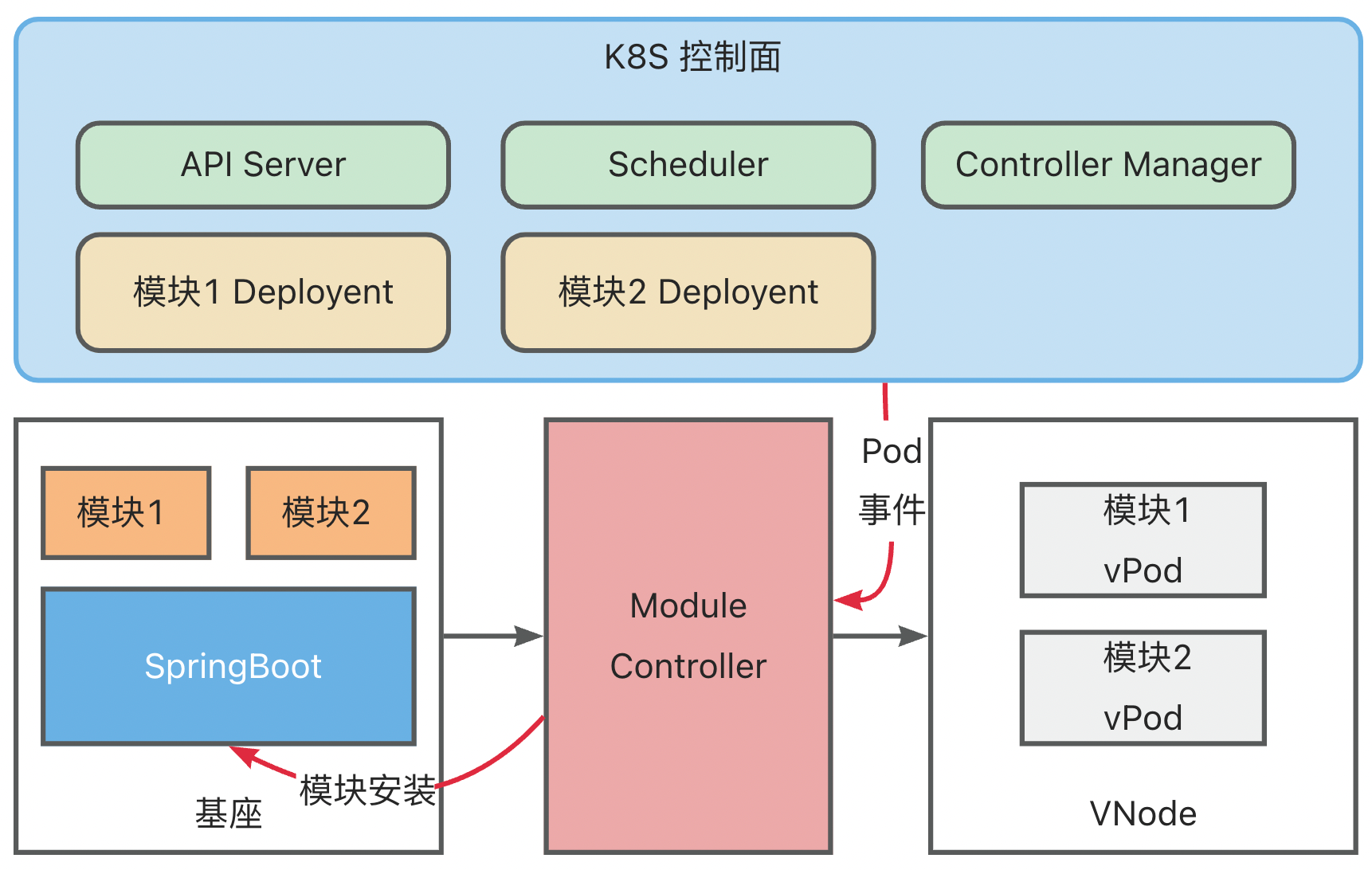
基座完成模块安装后,将模块安装状态与 Module Controller 进行同步,Module Controller 再将模块状态转换为 Container Status 同步到 K8S
同时,基座也会持续上报健康状态,Module Controller 会将 Metaspace 容量以及使用量映射为 Node Memory,更新到 K8S
实现逻辑
实现中涉及的核心逻辑如下:
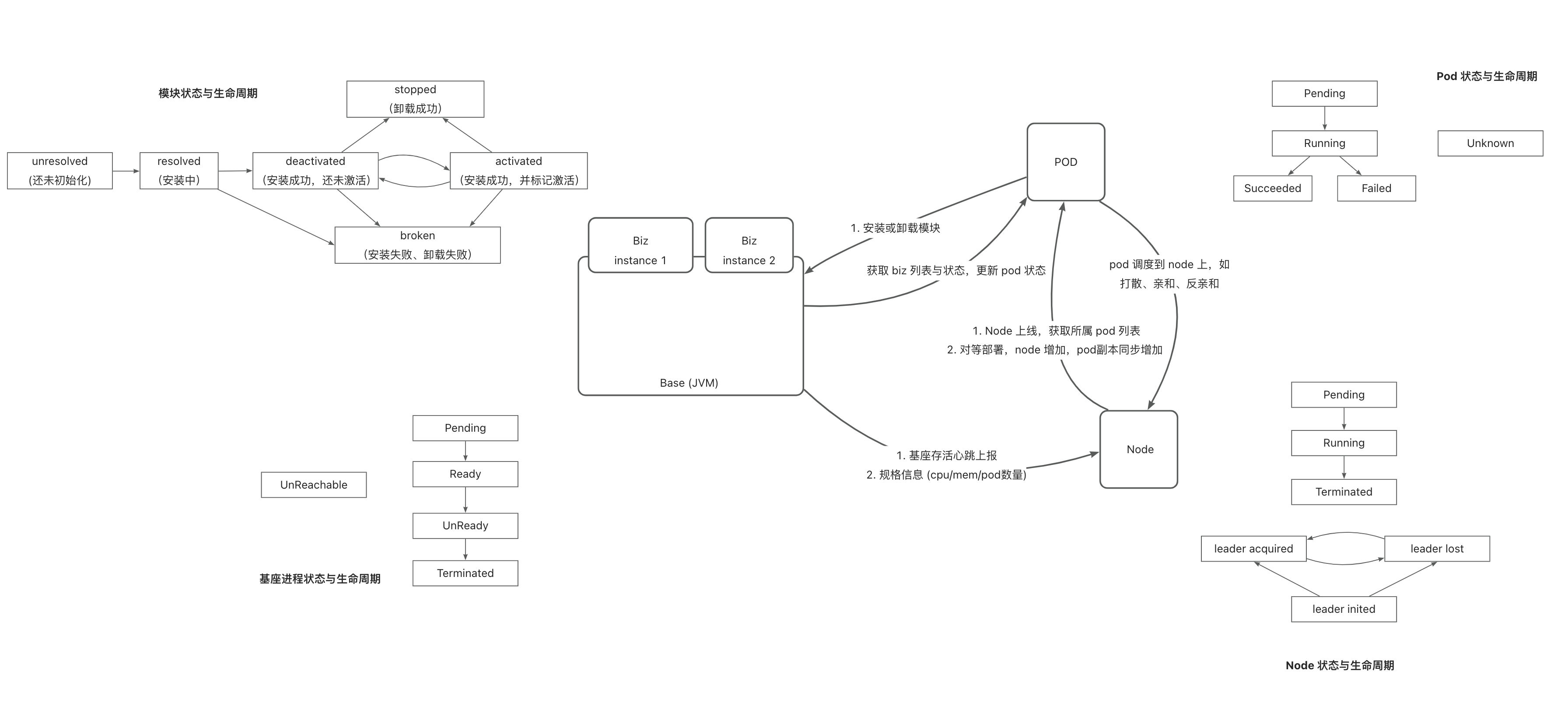
模型定义与逻辑关系:
如何 debug
- minikube 中启动 module-controller test 版本,
serverless-registry.cn-shanghai.cr.aliyuncs.com/opensource/test/module-controller-v2:v2.1.4,该镜像已经配置了 go-delve 远程 debug 环境,debug 端口为 2345
apiVersion: apps/v1
kind: Deployment
metadata:
name: module-controller
spec:
replicas: 1
selector:
matchLabels:
app: module-controller
template:
metadata:
labels:
app: module-controller
spec:
serviceAccountName: virtual-kubelet # 上一步中配置好的 Service Account
containers:
- name: module-controller
image: serverless-registry.cn-shanghai.cr.aliyuncs.com/opensource/test/module-controller-v2 # 已经打包好的镜像,镜像在 Module-controller 根目录的 debug.Dockerfile
imagePullPolicy: Always
resources:
limits:
cpu: "1000m"
memory: "400Mi"
ports:
- name: httptunnel
containerPort: 7777
- name: debug
containerPort: 2345
env:
- name: ENABLE_HTTP_TUNNEL
value: "true"
- 登录到启动后的容器
kubectl exec module-controller-544c965c78-mp758 -it -- /bin/sh
- 进入容器内部,启动 delve
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./module_controller
- 退出容器,打开 2345 端口映射
kubectl port-forward module-controller-76bdbcdd8d-fhvfd 2345:2345
- goland 或 idea 里启动远程调试,Host 为 localhost,Port 为 2345
6.3 - 6.6.3 核心流程时序
基座生命周期
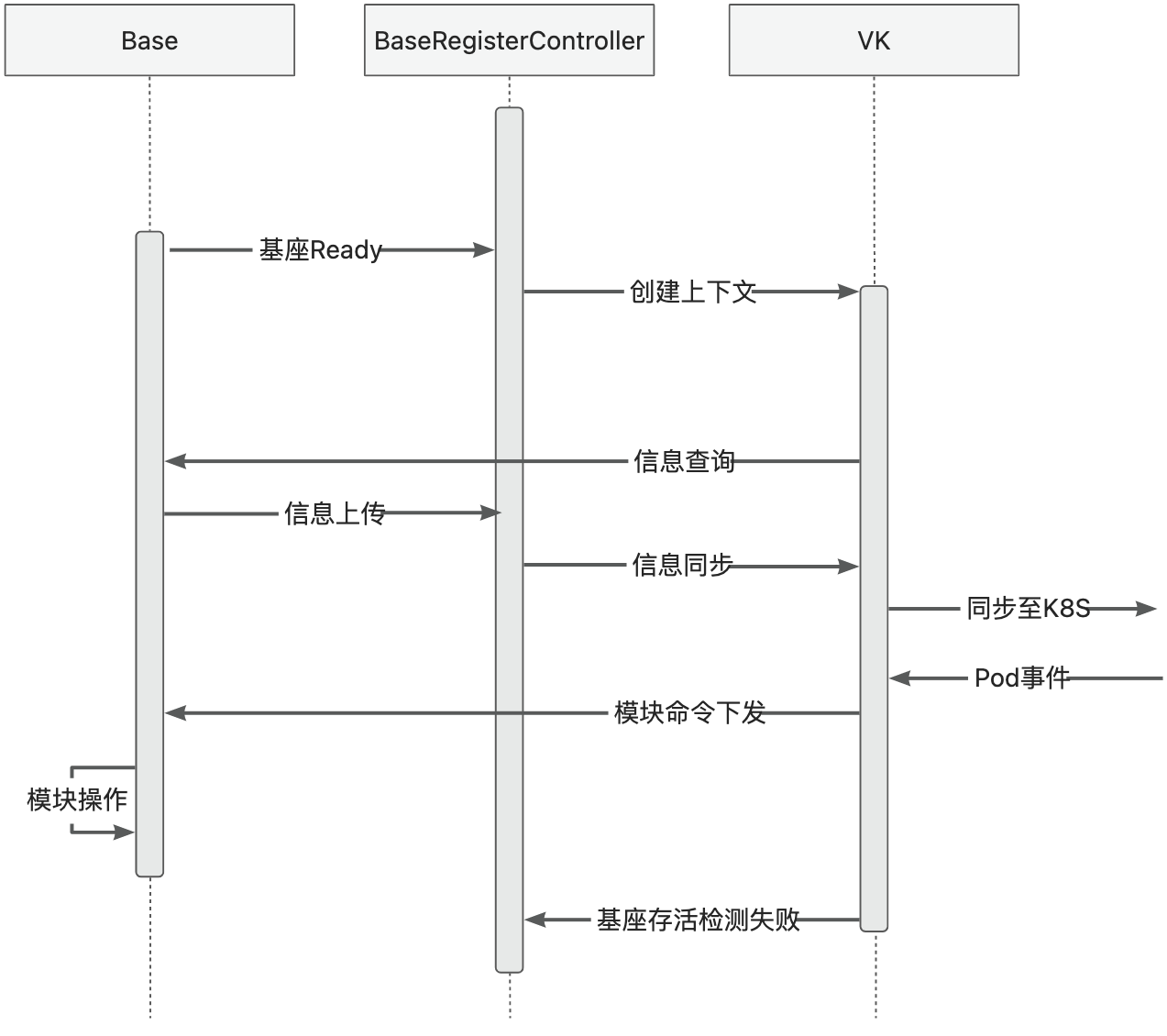
模块发布运维