6.6 ModuleController 技术文档
1 - 6.6.1 ModuleControllerV2 架构设计
简要介绍
ModuleControllerV2 是一个 K8S 控制面组件,基于Virtual Kubelet能力,将基座伪装成K8S体系中的node,将模块映射为K8S体系中的Container,从而将模块运维映射成为Pod的运维,基于K8S包含的Pod生命周期管、调取,以及基于Pod的Deployment、DaemonSet、Service等现有控制器,实现了 Serverless 模块的秒级运维调度,以及与基座的联动运维能力。
背景
原有的Module Controller(以下称之为MC)基于K8S Operator技术设计。 在这种模式下,原有的MC从逻辑上是定义了另外一套与基座隔离的,专用的模块控制面板,从逻辑上将模块与基座分成了两个相对独立的类别进行分别的运维,即基座的运维通过K8S的原生能力进行运维,模块运维通过Operator封装的运维逻辑进行运维。
这样的构建方法在逻辑上很清晰,对模块和基座的概念进行了区分,但是也带来了一定的局限性:
首先由于逻辑上模块被抽象成了不同于基座模型的另一类代码,因此原来的MC除了要实现在基座上进行模块的加载、卸载以外,还需要:
- 感知当前所有的基座
- 维护基座状态(基座在线状态、模块加载情况、模块负载等)
- 维护模块状态(模块在线状态等)
- 根据业务需要实现相应的模块调度逻辑
这将为带来巨大的开发与维护成本。(单场景的Operator开发成本高)
模块能力与角色横向扩展困难。这种实现方式从逻辑上是与原先比较常见的微服务架构是相互不兼容的,微服务架构不同微服务之间的角色是相同的,然而在Operator的实现中,模块与基座的抽象层级是不同的,两者不能互通。 以Koupleless所提出的:“模块既可以以模块的形式attach到基座上,也可以以服务的形式单独运行”为例,在Operator架构下,如果想实现后者的能力,就需要单独为这种需求定制一套全新的调度逻辑,至少需要定制维护特定的依赖资源,才能够实现,这样未来每需要一种新的能力/角色,都需要定制开发大量的代码,开发维护成本很高。(横向扩展的开发成本高)
在这种架构下,模块成为了一种全新的概念,从产品的角度,会增大使用者的学习成本。
架构
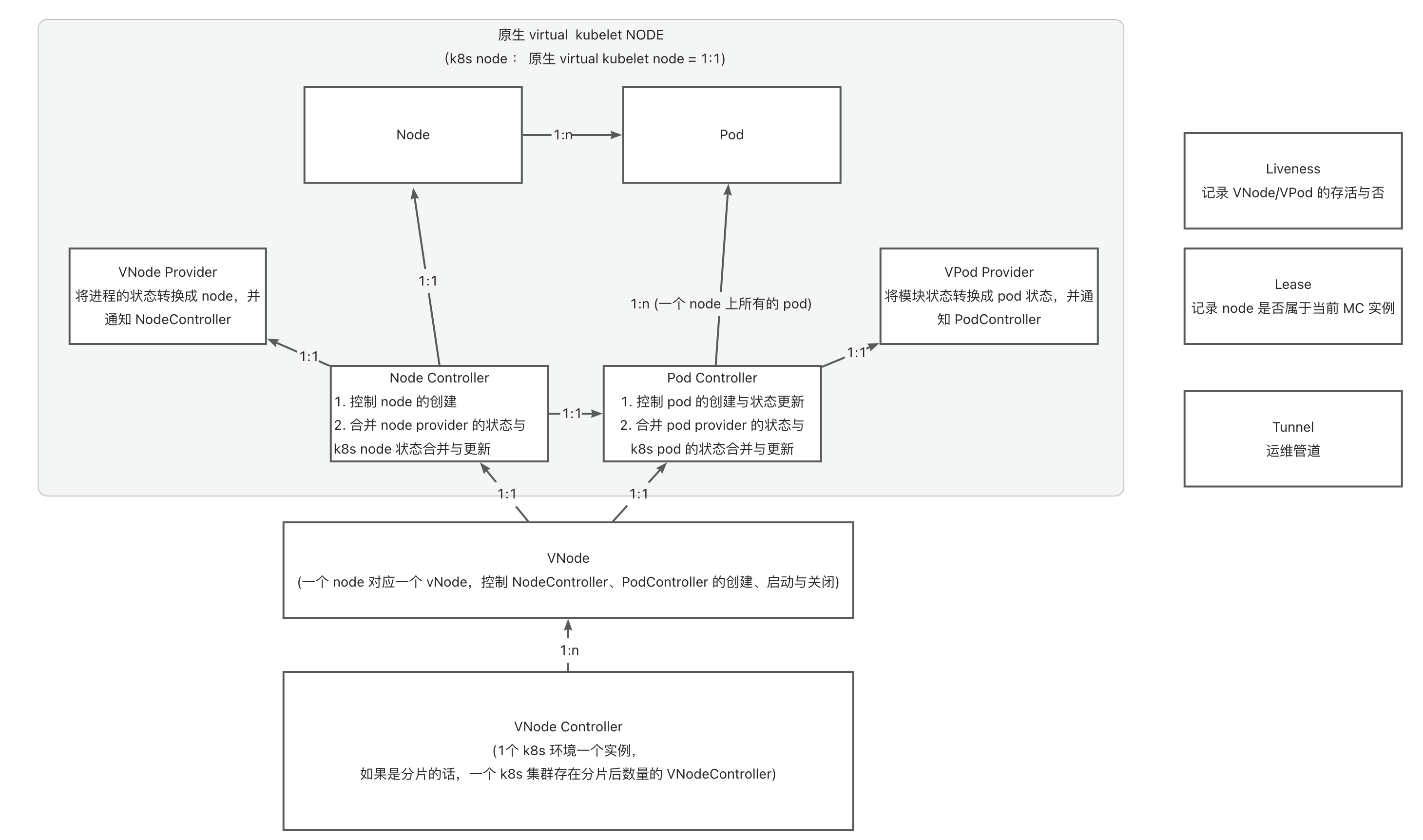
ModuleControllerV2 目前包含Virtual Kubelet Manager控制面组件和Virtual Kubelet组件。Virtuakl Kubelet组件是Module Controller V2的核心,负责将基座服务映射成一个node,并对其上的Pod状态进行维护,Manager维护基座相关的信息,监听基座上下线消息,关注基座的存活状态,并维护Virtual Kubelet组件的基本运行环境。
Virtual Kubelet
Virtual Kubelet参考了官方文档 的实现
一句话做一个总结就是:VK是一个可编程的Kubelet。
就像在编程语言中的概念,VK是一个Kubelet接口,定义了一组Kubelet的标准,通过对VK这一接口进行实现,我们就可以实现属于我们自己的Kubelet。
K8S中原有的运行在Node上的Kubelet就是对VK的一种实现,通过实现VK中抽象的方法从而使得K8S控制面能够对Node上物理资源的使用与监控。
因此VK具有伪装成为Node的能力,为了区分传统意义上的Node和VK伪装的Node,下面我们将VK伪装的Node称为VNode。
逻辑结构
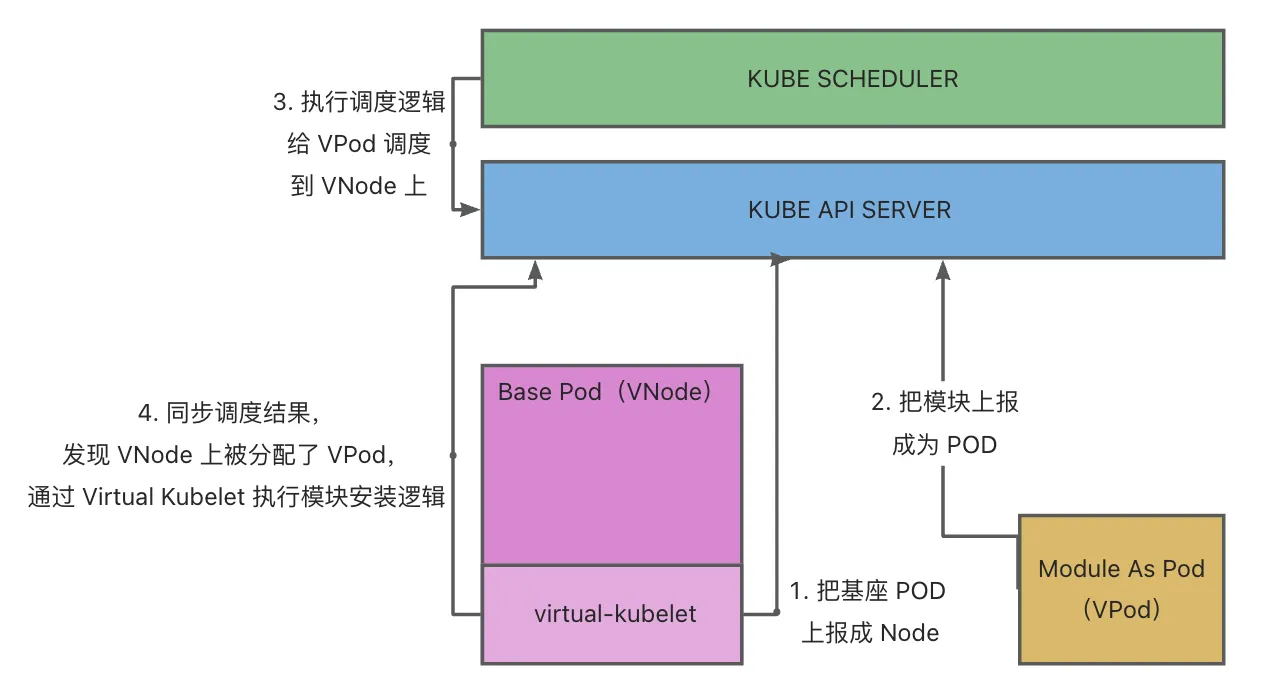
在Koupleless的架构中,基座服务运行在Pod中,这些Pod由K8S进行调度与维护,分配到实际的Node上运行。
对模块调度的需求实际上和基座的调度是一致的,因此在MC V2的设计中,使用VK将基座服务伪装成传统K8S中的Node,变成基座VNode,将模块伪装成Pod, 变成模块VPod,从逻辑上抽象出第二层K8S用于管理VNode和VPod。
综上,在整体架构中会将包含两个逻辑K8S:
- 基座K8S:维护真实Node(虚拟机/物理机),负责将基座Pod调度到真实Node上
- 模块K8S:维护虚拟VNode(基座Pod), 负责将模块VPod调度到虚拟VNode上
之所以称之为逻辑K8S是因为两个K8S不一定需要是真实的两个分离的K8S,在隔离做好的情况下,可以由同一个K8S完成两部分任务。
通过这种抽象,我们就可以在不对框架做额外开发的前提下,复用K8S原生的调度和管理的能力实现:
- 基座VNode的管理(非核心能力,因为其本身就是底层K8S中的一个Pod,可以由底层K8S来维护状态,但作为Node也将包含更多的信息)
- VPod的管理(核心能力:包含模块运维,模块调度、模块生命周期状态维护等)
多租户VK架构
原生的VK基于K8S的Informer机制和ListWatch实现当前vode上pod事件的监听。但是这样也就意味着每一个vnode都需要启动一套监听逻辑,这样,随着基座数量的增加,APIServer的压力会增长的非常快,不利于规模的横向扩展。
为了解决这一问题,Module Controller V2基于Virtual Kubelet,将其中的ListWatch部分抽取出来,通过监听某一类Pod(具体实现中为包含特定label的Pod)的事件,再通过进程内通信的方式将事件转发到逻辑VNode上进行处理的方式实现Informer资源的复用,从而只需要在各VNode中维护本地上下文,而不需要启动单独的监听,降低APIServer的压力。
多租户架构下,Module Controller V2中将包含两个核心模块:
- 基座注册中心:这一模块通过特定的运维管道进行基座服务的发现,以及VK的上下文维护与数据传递。
- VK:VK保存着某个具体基座和node,pod之间的映射,实现对node和pod状态的维护以及将pod操作翻译成为对应的模块操作下发至基座。
分片架构
单点的Module Controller很显然缺乏容灾能力,并且单点的上限也很明显,因此Module Controller V2需要一套更加稳定,具备容灾和水平扩展能力的架构。
在模块运维中我们核心关注的问题是调度能力的稳定性,而在 Module Controller 当前架构下,调度的稳定性包含两个部分:
- 所依赖 K8S 的稳定性
- 基座稳定性
其中第一条无法在 Module Controller 这一层进行保证,因此 Module Controller 的高可用只关注基座层级的稳定性。
除此之外,Module Controller 的负载主要体现在对各类 Pod 事件的监听和处理,与 Pod 数量和所接管的基座数量相关,由于 K8S API Server 对单客户端的访问速率限制,导致单个 Module Controller 实例能够同时处理的事件有上限,因此同时还需要在 Module Controller 层级建设负载分片能力。
因此 Module Controller 的分片架构核心关注两个问题:
- 基座的高可用
- Pod 事件的负载均衡
而在 Module Controller 的场景下,Pod 事件与基座是强绑定的,因此实际上对 Pod 事件的负载均衡等同于所接管基座的均衡。
为了解决上述问题,Module Controller 在多租户 Virtual Kubelet 上建设了原生的分片能力,具体逻辑如下:
- 每一个 Module Controller 实例都会监听所有基座的上线信息
- 监听到基座的上线之后,每一个 Module Controller 都会创建对应的 VNode 数据,并尝试创建 VNode 的 node lease
- 由于 K8S 中同名资源的冲突性,在这一过程中只会有一个 Module Controller 实例成功创建了 Lease,此时这一 Module Controller 所持有的 VNode 就会变成主实例,而其他创建失败的 Module Controller 所持有的同一个 VNode 就会变成副本,持续对 Lease 对象进行监听,尝试重新抢主,从而实现了 VNode 的高可用
- VNode 成功启动之后会监听调度到其上的 Pod,进行交互,而未成功启动的 VNode 会忽略掉这些事件,从而实现了 Module Controller 的负载分片
因此最终形成架构:多 Module Controller 之间基于 Lease 对 VNode 负载进行分片,多 Module Controller 通过多 VNode 数据实现 VNode 的高可用。
除此之外,我们还期望多个 Module Controller 之间能够尽可能负载均衡,即每一个 Module Controller 所持有的基座数量大致均衡。
为了方便开源用户使用,降低学习成本,我们尽量在不引入额外组件的情况下基于 K8S 实现了一套自均衡能力:
- 首先每一个 Module Controller 实例都会维护自身当前工作负载,计算规则为 (当前接管的VNode数量 / 所有VNode数量),例如,当前 Module Controller 接管 3 个 VNode,集群中共有 10 个 VNode 的情况,实际工作负载即为 3/ 10 = 0.3
- 在 Module Controller 启动的时候可以指定最大工作负载等级,Module Controller 会根据这一参数将工作负载分为对应片数,例如最大工作负载等级若指定为 10,那么每个工作负载等级将会包含 1/10 的区间,即 工作负载 0-0.1 将定义为 工作负载=0,0.1-0.2 定义为 工作负载=1,以此类推
- 在配置为分片集群的情况下,Module Controller 在尝试创建 Lease 之前会首先计算当前自身的工作负载等级,根据工作负载等级进行不同程度的等待,之后再进行创建。在这种情况下,低工作负载的 Module Controller 会更早的尝试创建,创建成功的概率提高,从而实现负载均衡
以上的过程实际上基于 K8S 事件的广播机制设计,而在基座首次上线时,根据所选择运维管道的不同,还需要进行另外的考虑:
- MQTT 运维管道:由于 MQTT 本身就具有广播能力,所有 Module Controller 实例都会接收到 MQTT 上线消息,不需要额外配置
- HTTP 运维管道:HTTP 请求的特殊性使得基座在上线的时候只会与某一个 Module Controller 实例进行交互,那么此时初次上线时的负载均衡就需要通过其他能力实现。在实际部署中,多个 Module Controller 需要通过一个代理 (K8S Service/ Nginx等 )来对外提供服务,因此可以在代理层上配置负载均衡策略,实现初次上线过程中的均衡。
2 - 6.6.2 ModuleControllerV2 原理
模块运维架构
简要介绍
Module Controller V2 基于 Virtual Kubelet 能力,实现将基座映射为 K8S 中的 Node,进而通过将 Module 定义为 Pod 实现对 K8S 调度器以及各类控制器的复用,快速搭建模块运维调度能力。
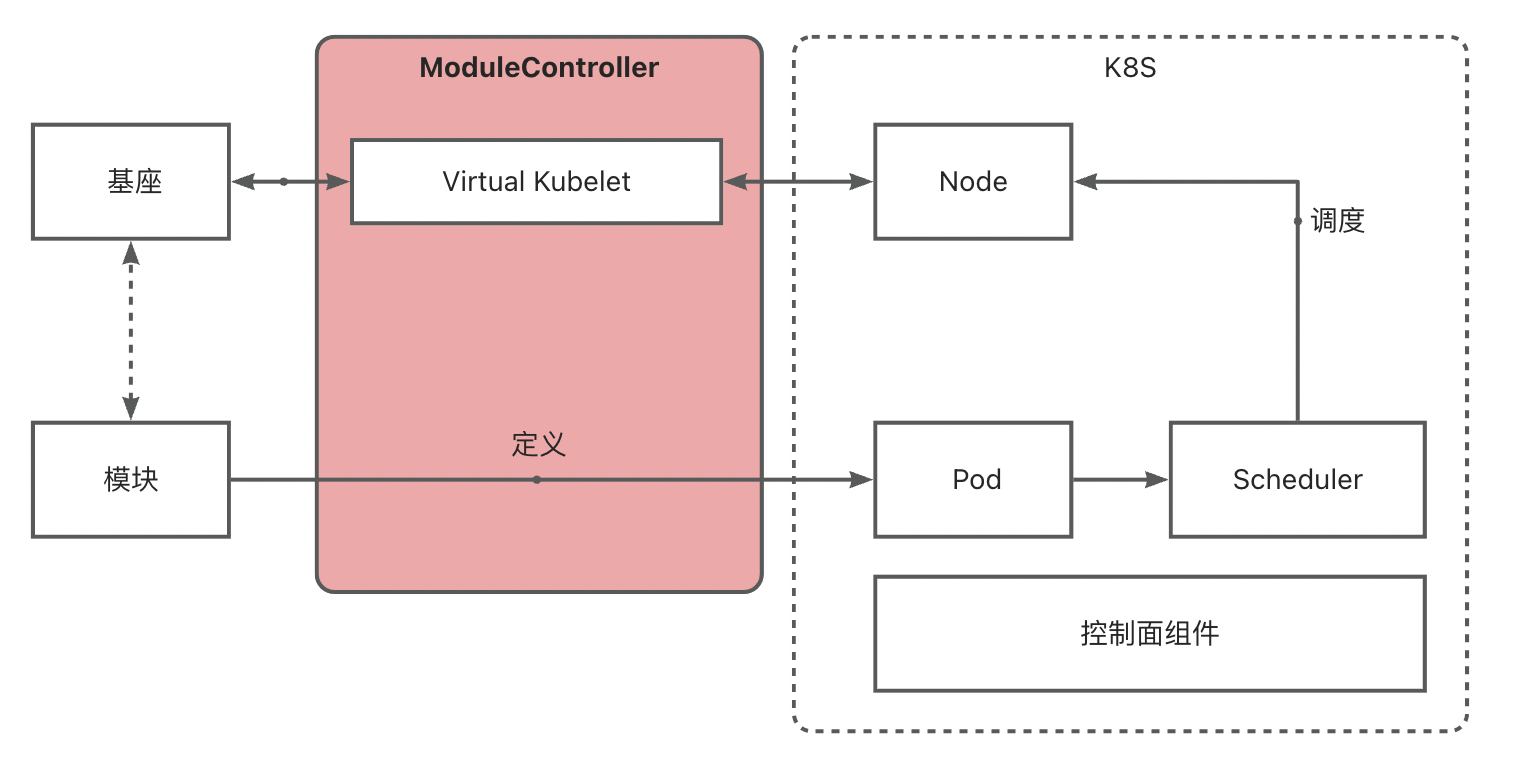
基座 <-> VNode 映射
Module Controller V2 通过 Tunnel 实现基座发现,基座发现后将会通过 Virtual Kubelet 将其伪装成 Node,以下称此类伪装的 Node 为 VNode。
基座发现时将读取基座中所配置的 Metadata 和 Network 信息,其中 Metadata 包含 Name 和 Version,Network 包含 IP 和 Hostname 信息。
Metadata 信息将变成 VNode 上的 Label 信息,用于标识基座信息, Network 信息将成为 VNode 的网络配置,未来调度到基座上的 module pod 将继承 VNode 的 IP, 用于配置 Service 等。
一个 VNode 还将包含以下关键信息:
apiVersion: v1
kind: Node
metadata:
labels:
virtual-kubelet.koupleless.io/component: vnode # vnode标记
virtual-kubelet.koupleless.io/env: dev # vnode环境标记
base.koupleless.io/name: base # 基座 Metadata 中的 Name 配置
vnode.koupleless.io/tunnel: mqtt_tunnel_provider # 基座当前归属 tunnel
base.koupleless.io/version: 1.0.0 # 基座版本号
name: vnode.2ce92dca-032e-4956-bc91-27b43406dad2 # vnode name, 后半部分为基座运维管道所生成的 uuid
spec:
taints:
- effect: NoExecute
key: schedule.koupleless.io/virtual-node # vnode 污点,防止普通 pod 调度
value: "True"
- effect: NoExecute
key: schedule.koupleless.io/node-env # node env 污点,防止非当前环境 pod 调度
value: dev
status:
addresses:
- address: 127.0.0.1
type: InternalIP
- address: local
type: Hostname
模块 <-> vPod 映射
Module Controller V2 将模块定义为 K8S 体系中的一个 Pod(为了区分,后续称为 vPod ),通过配置 Pod Yaml 实现丰富的调度能力。
一个模块 vPod 的 Yaml 配置如下:
apiVersion: v1
kind: Pod
metadata:
name: test-single-module-biz1
labels:
virtual-kubelet.koupleless.io/component: module # 必要,声明pod的类型,用于module controller管理
spec:
containers:
- name: biz1 # 模块名,需与模块 pom 中 artifactId 的配置严格对应
image: https://serverless-opensource.oss-cn-shanghai.aliyuncs.com/module-packages/stable/biz1-web-single-host-0.0.1-SNAPSHOT-ark-biz.jar # jar包地址,支持本地 file,http/https 链接
env:
- name: BIZ_VERSION # 模块版本配置
value: 0.0.1-SNAPSHOT # 需与 pom 中的 version 配置严格对应
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms: # 基座node选择
- matchExpressions:
- key: base.koupleless.io/version # 基座版本筛选
operator: In
values:
- 1.0.0 # 模块可能只能被调度到一些特殊版本的基座上,如有这种限制,则必须有这个字段。
- key: base.koupleless.io/name # 基座名筛选
operator: In
values:
- base # 模块可能只能被调度到一些特定基座上,如有这种限制,则必须有这个字段。
tolerations:
- key: "schedule.koupleless.io/virtual-node" # 确保模块能够调度到基座 vnode 上
operator: "Equal"
value: "True"
effect: "NoExecute"
- key: "schedule.koupleless.io/node-env" # 确保模块能够调度到特定环境的基座node上
operator: "Equal"
value: "test"
effect: "NoExecute"
上面的样例只展示了最基本的配置,另外还可以添加任意配置以实现丰富的调度能力,例如在 Module Deployment 发布场景中,可另外添加 Pod AntiAffinity 以防止模块的重复安装。
运维流程
基于上述结构与映射关系,我们就可以复用 K8S 原生的控制面组件,实现复杂多样的模块运维需求。
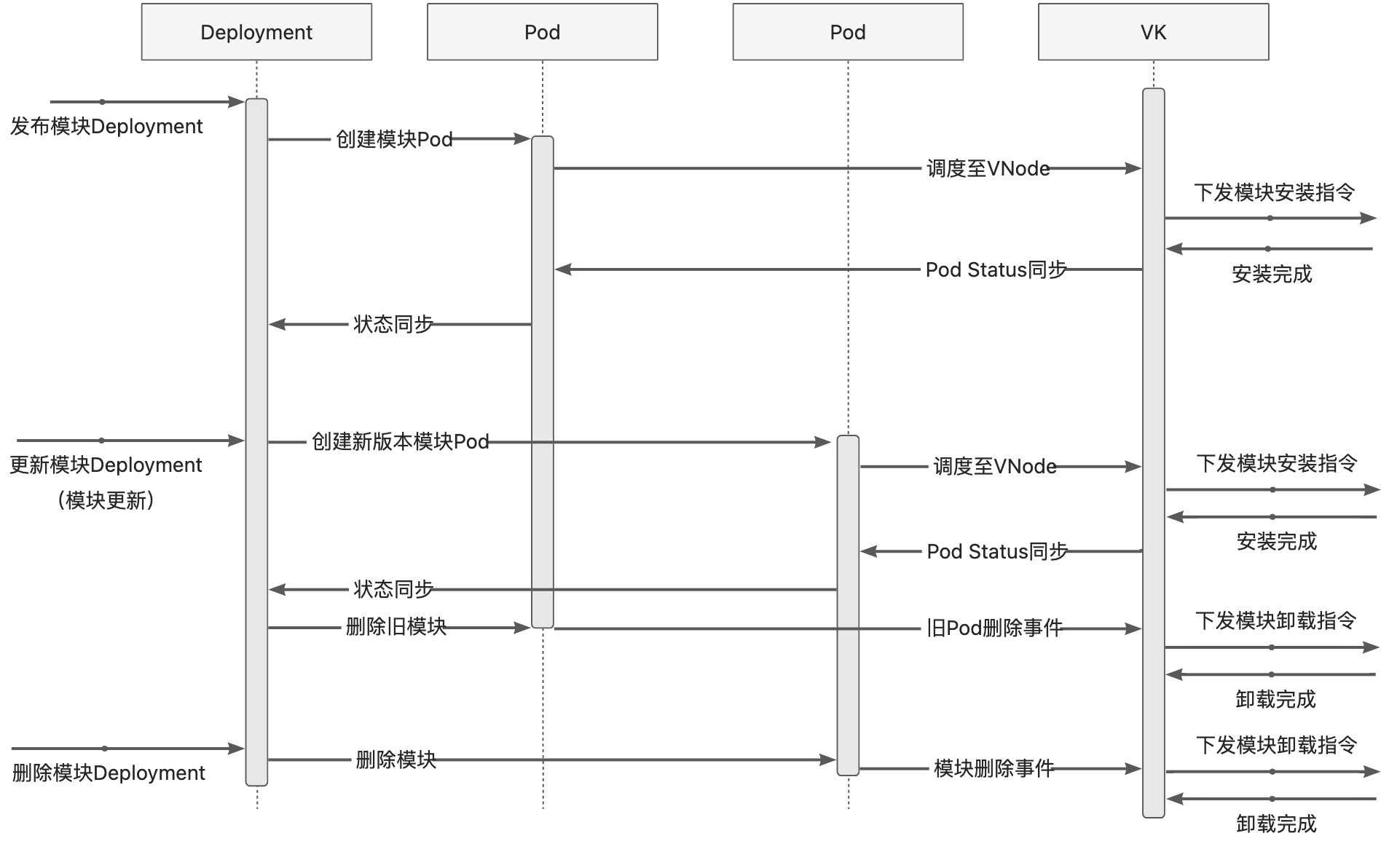
下面以模块 Deployment 为例展示整个模块运维流程,此时基座已完成启动与映射:
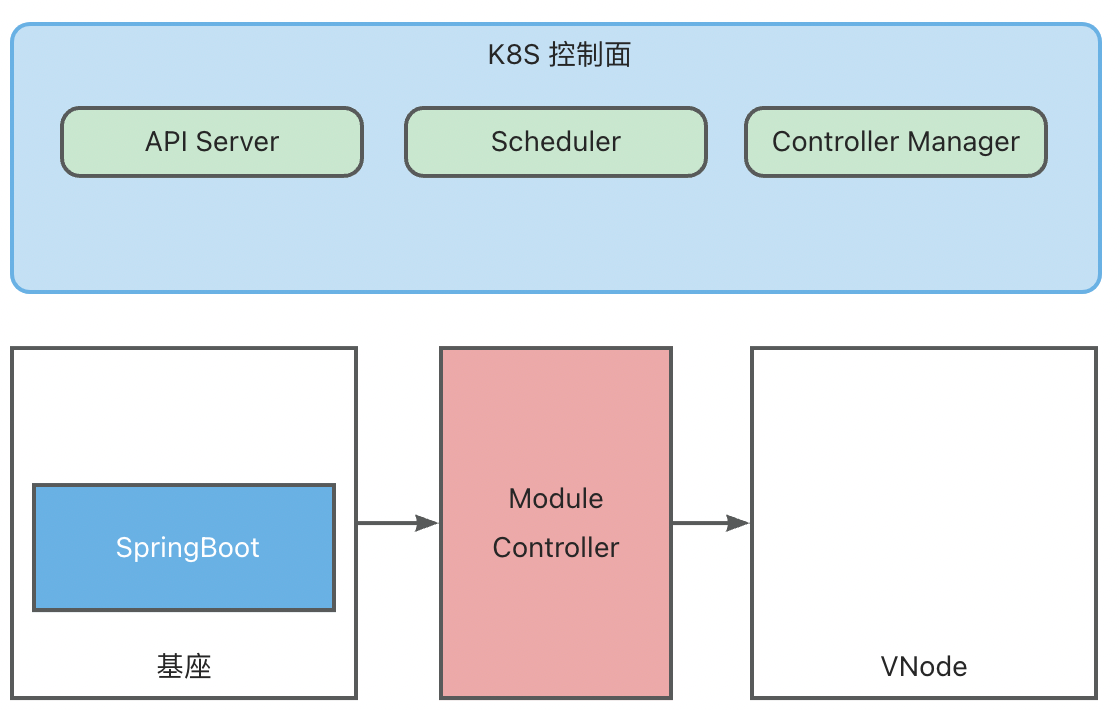
- 创建模块 Deployment (原生 K8S Deployment,其中 Template 中的 PodSpec 对模块信息进行了定义),K8S ControllerManager 中的 Deployment Controller 会根据 Deployment 配置创建模块vPod,此时 vPod 还未调度,状态为 Pending
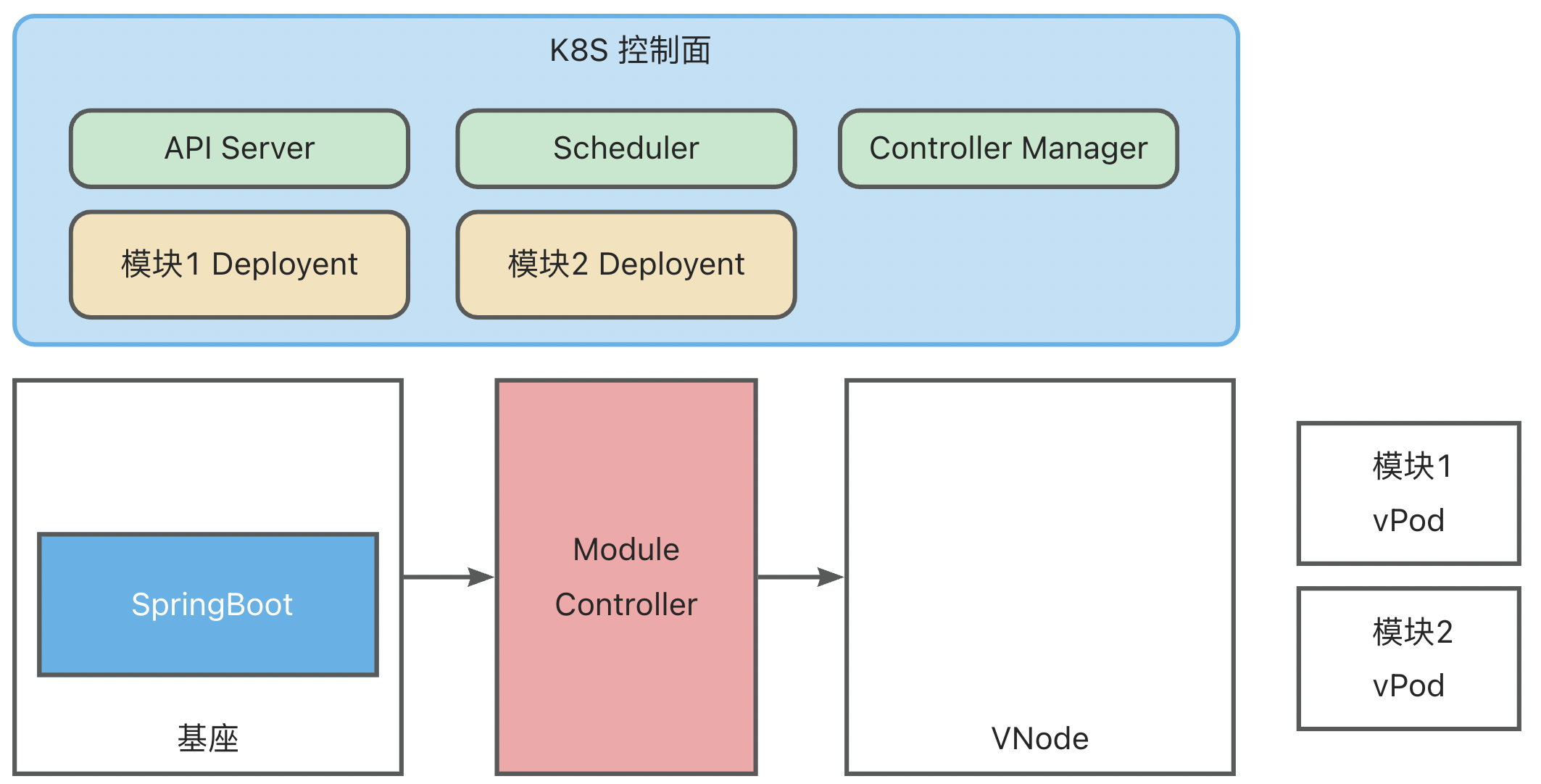
- K8S Scheduler 扫描未调度的 vPod,然后根据 selector、affinity、taint/toleration 配置将其调度到合适的 vNode 上
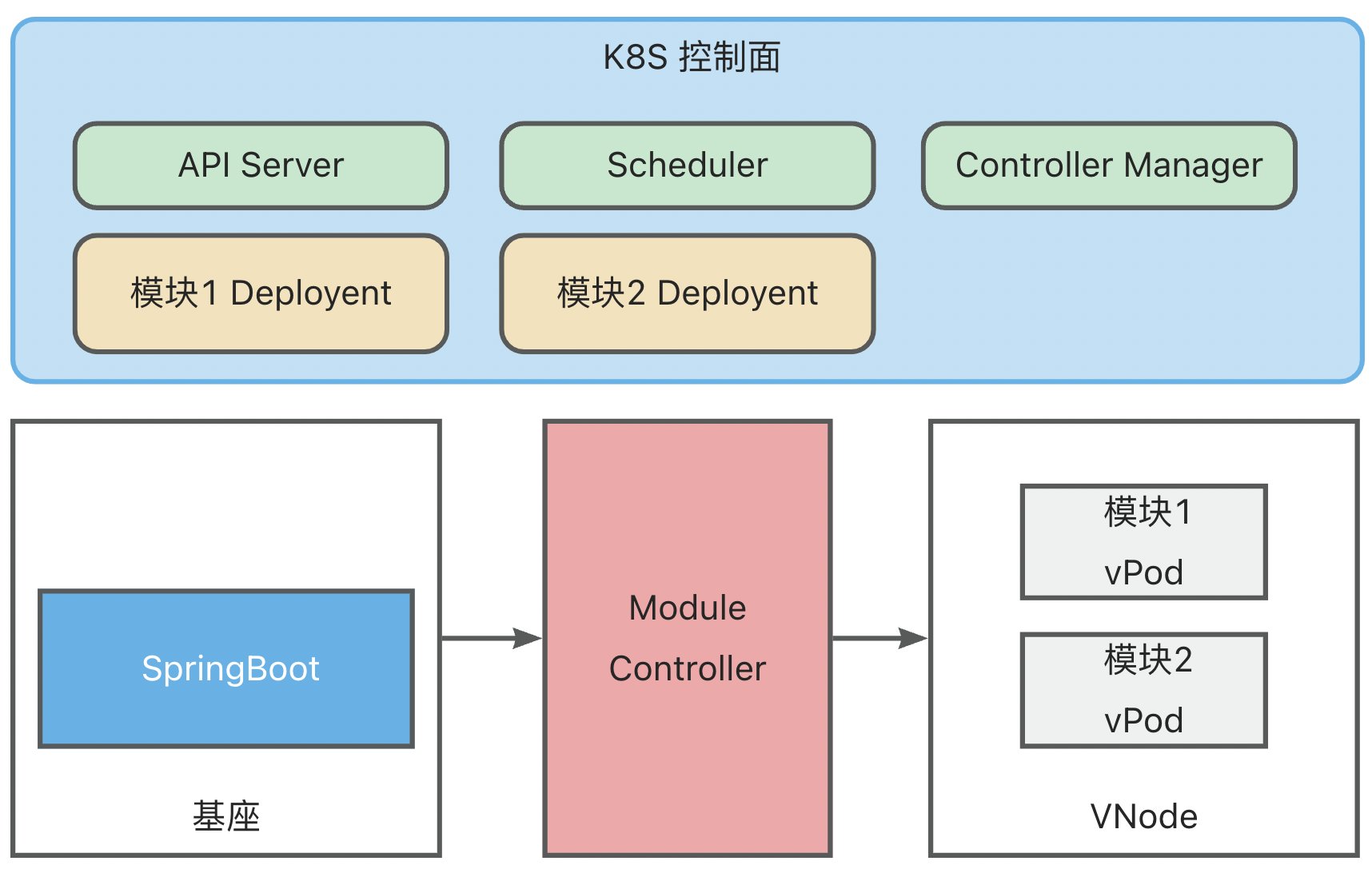
- Module Controller 监听到 vPod 完成调度,获取到 vPod 中定义的模块信息,将模块安装指令发送到基座上
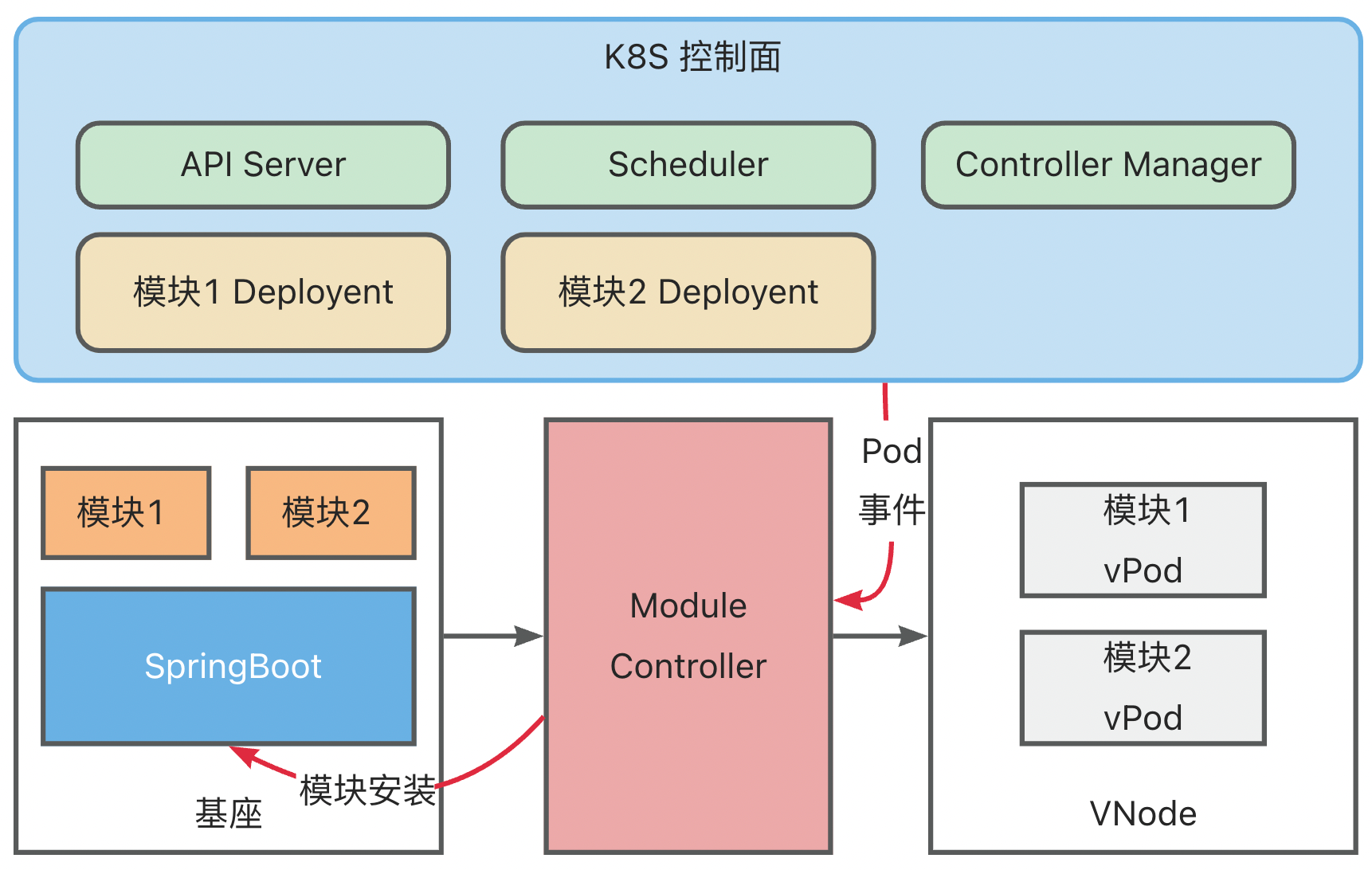
基座完成模块安装后,将模块安装状态与 Module Controller 进行同步,Module Controller 再将模块状态转换为 Container Status 同步到 K8S
同时,基座也会持续上报健康状态,Module Controller 会将 Metaspace 容量以及使用量映射为 Node Memory,更新到 K8S
实现逻辑
实现中涉及的核心逻辑如下:
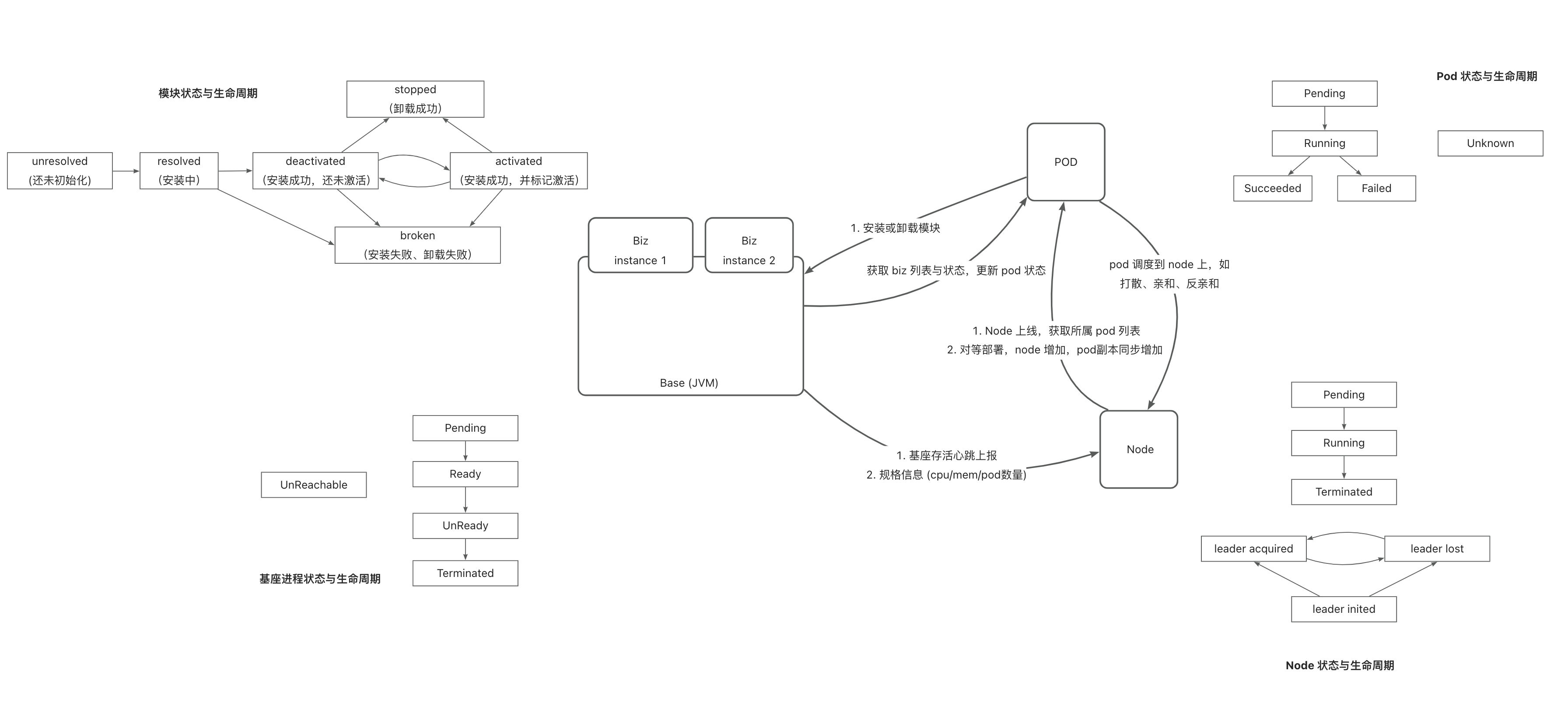
模型定义与逻辑关系:
如何 debug
- minikube 中启动 module-controller test 版本,
serverless-registry.cn-shanghai.cr.aliyuncs.com/opensource/test/module-controller-v2:v2.1.4,该镜像已经配置了 go-delve 远程 debug 环境,debug 端口为 2345
apiVersion: apps/v1
kind: Deployment
metadata:
name: module-controller
spec:
replicas: 1
selector:
matchLabels:
app: module-controller
template:
metadata:
labels:
app: module-controller
spec:
serviceAccountName: virtual-kubelet # 上一步中配置好的 Service Account
containers:
- name: module-controller
image: serverless-registry.cn-shanghai.cr.aliyuncs.com/opensource/test/module-controller-v2 # 已经打包好的镜像,镜像在 Module-controller 根目录的 debug.Dockerfile
imagePullPolicy: Always
resources:
limits:
cpu: "1000m"
memory: "400Mi"
ports:
- name: httptunnel
containerPort: 7777
- name: debug
containerPort: 2345
env:
- name: ENABLE_HTTP_TUNNEL
value: "true"
- 登录到启动后的容器
kubectl exec module-controller-544c965c78-mp758 -it -- /bin/sh
- 进入容器内部,启动 delve
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./module_controller
- 退出容器,打开 2345 端口映射
kubectl port-forward module-controller-76bdbcdd8d-fhvfd 2345:2345
- goland 或 idea 里启动远程调试,Host 为 localhost,Port 为 2345
3 - 6.6.3 核心流程时序
基座生命周期
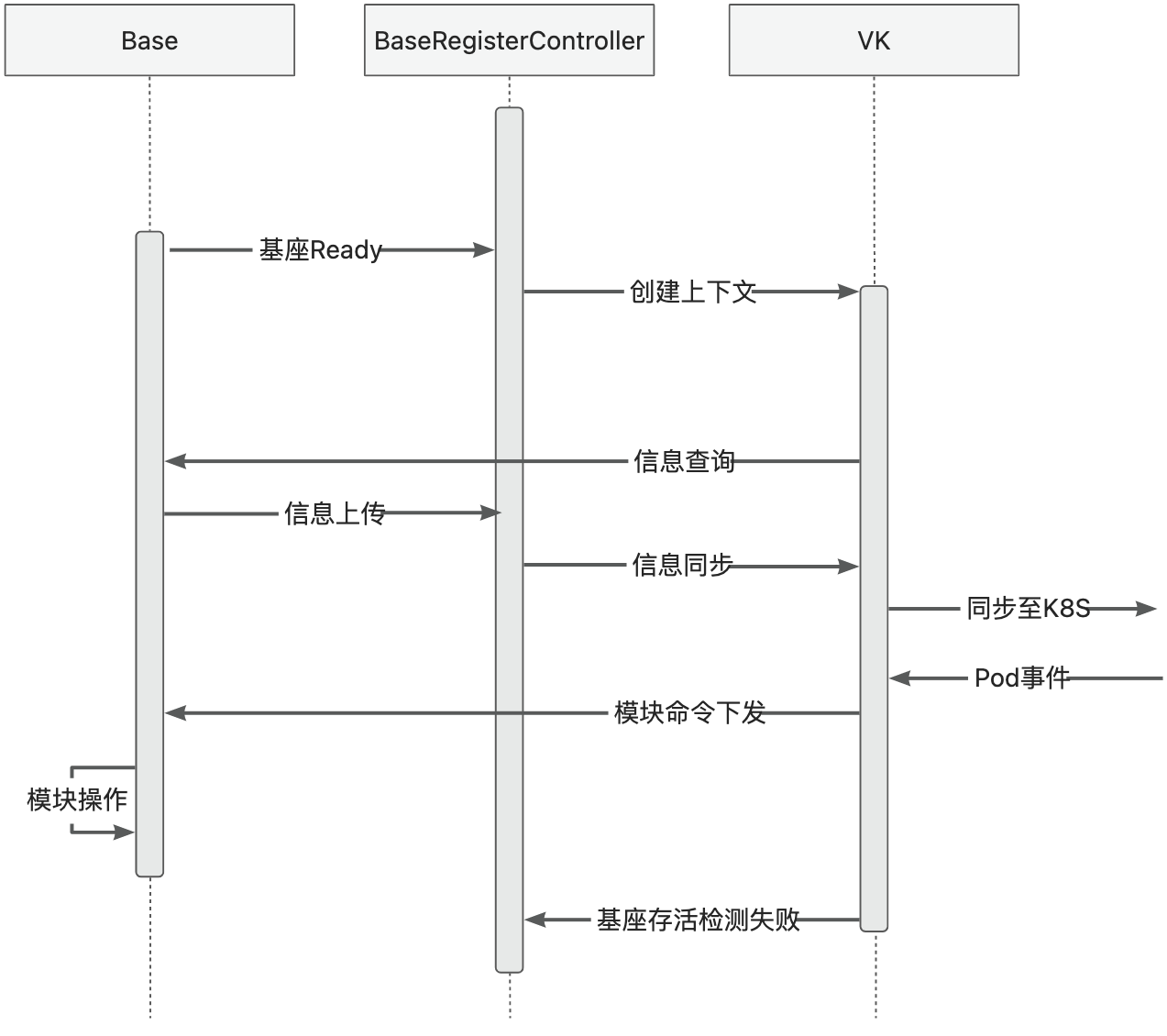
模块发布运维
4 - 6.6.4 Kubelet 代理
Kubelet 代理
Kubelet 代理是 Module Controller V2 在 K8s 侧的增强功能,它允许用户通过 kubectl 工具直接与 Module Controller V2
交互,提供类似于 K8s 原生 Kubelet 的操作体验。

logs 命令示意图
迭代计划
适配分两阶段进行:
- 使用 proxy 代理方案,为部署在 Pod 基座中的模块提供 logs 能力 -> 已完成
- 在保证语义的前提下,通过 tunnel 或 arklet 实现 logs 能力,完成平滑切换 -> 规划中
注意事项
当前仅实现了 logs 能力,且基座必须部署在 K8s 集群中。