6.5.4.2 单体应用协作开发太难?Koupleless 带来拆分插件,帮你抽丝剥茧提高协作开发效率!
背景
你的企业应用协作效率低吗?
明明只改一行,但代码编译加部署要十分钟;
多人开发一套代码库,调试却频频遇到资源抢占和相互覆盖,需求上线也因此相互等待……
当项目代码逐渐膨胀,业务逐渐发展,代码耦合、发布耦合以及资源耦合的问题日益加重,开发效率一降再降。
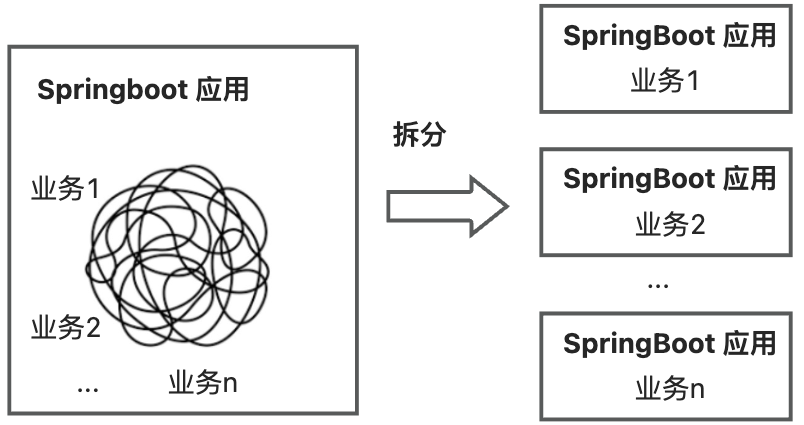
如何解决?来试试把单个 Springboot 应用拆分为多个 Springboot 应用吧!拆出后,多个 Springboot 应用并行开发,互不干扰。在 Koupleless 模式下,业务可以将 Springboot 应用拆分成一个基座和多个 Koupleless 模块(Koupleless 模块也是 Springboot 应用)。
🙌拉到「Koupleless 拆分插件解决方案」部分,可直接查看单体应用拆分的插件演示视频!
关键挑战
从单个 Springboot 应用拆出 多个 Springboot 应用有三大关键挑战:
一是拆子应用前,复杂单体应用中代码耦合高、依赖关系复杂、项目结构复杂,难以分析各文件间的耦合性,更难从中拆出子应用,因此需要解决拆分前复杂单体应用中的文件依赖分析问题。
二是拆子应用时,拆出操作繁琐、耗时长、用户需要一边分析依赖关系一边拆出,对用户要求极高,因此需要降低拆分时用户交互成本。
三是拆子应用后,单体应用演进为多应用共存,其编码模式会发生改变。Bean 调用方式由单应用调用演进为跨应用调用,特殊的多应用编码模式也需根据框架文档调整,比如在 koupleless 中,为了减少模块的数据源连接,模块会按照某种方式使用基座的数据源,其学习成本与调整成本极高,因此需要解决拆分后多应用编码模式演进问题。
Koupleless 拆分插件解决方案
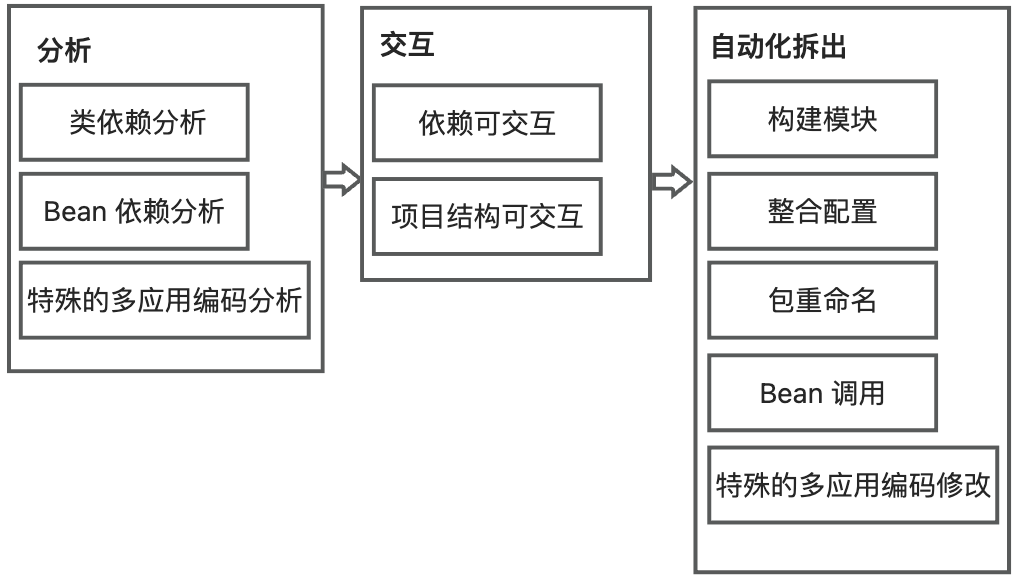
针对以上三大关键挑战,Koupleless IntelliJ IDEA 插件将解决方案分为 3 个部分:分析、交互和自动化拆出,提供依赖分析、友好交互和自动化拆出能力,如下图:
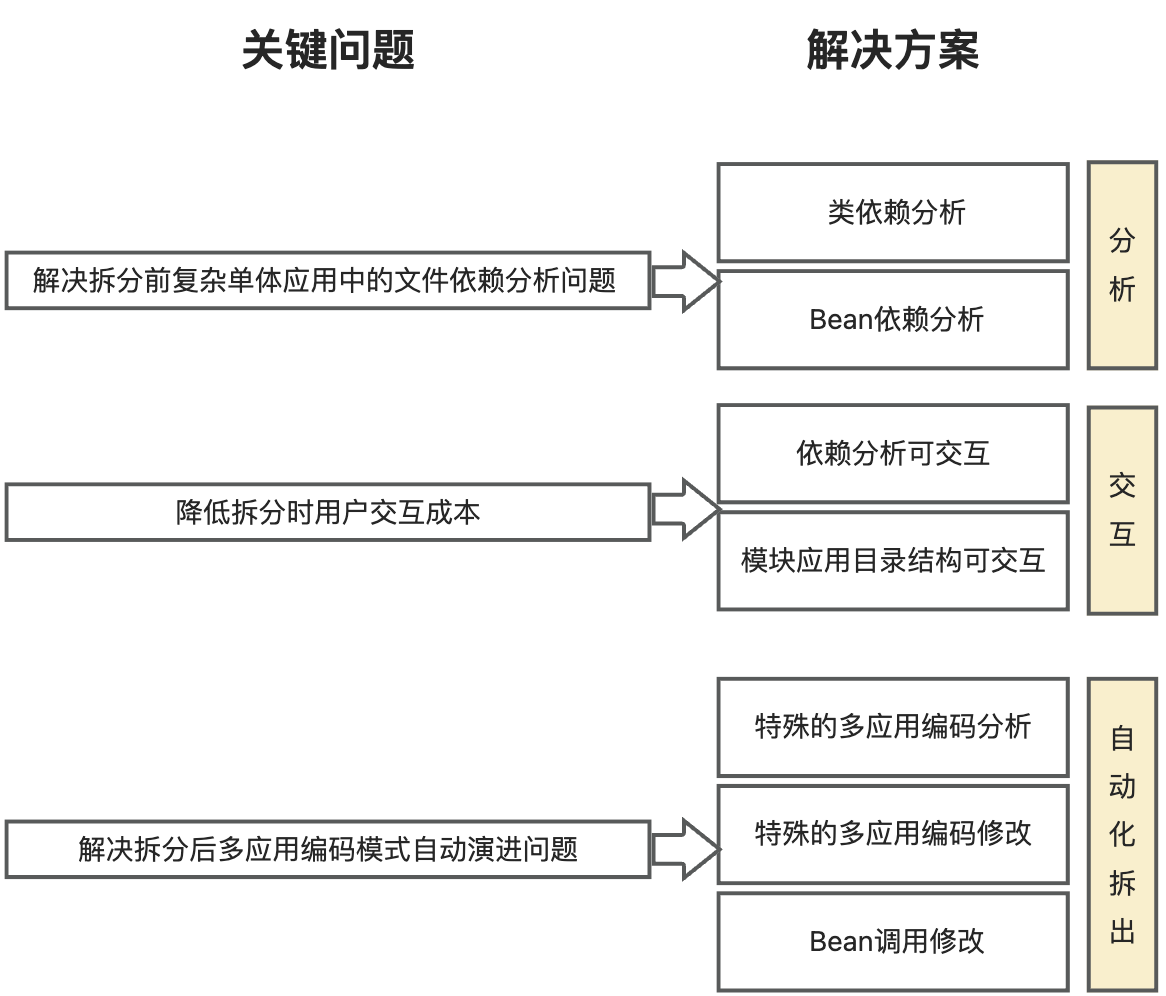
- 在分析中,分析项目中的依赖关系,包括类依赖和Bean依赖分析,解决拆分前复杂单体应用中的文件依赖分析问题;
- 在交互中,可视化类文件之间的依赖关系,帮助用户梳理关系。同时,可视化模块目录结构,让用户以拖拽的方式决定要拆分的模块文件,降低拆分时的用户交互成本;
- 在自动化拆出中,插件将构建模块,并根据特殊的多应用编码修改代码,解决拆分后多应用编码模式演进问题。
🙌 此处有 Koupleless 半自动拆分演示视频,带你更直观了解插件如何在分析、交互、自动化拆出中提供帮助。
一个示例 秒懂 Koupleless 解决方案优势
假设某业务需要将与 system 相关的代码都拆出到模块,让通用能力保留在基座。这里我们以 system 的入口服务 QuartzJobController 为例。
步骤一:分析项目文件依赖关系
首先,我们会分析 QuartzJobController 依赖了哪些类和 Bean。
方式一:使用 Idea 专业版,对 Controller 做 Bean 分析和类分析,得到以下 Bean 依赖图和类依赖关系图
 |  |
|---|
- 优势:借助 IDEA 专业版,分析全面
- 劣势:需要对每个类文件都做一次分析,Bean 依赖图可读性不强。
方式二:凭借脑力分析
当 A 类依赖了B、C、D、…、N类,在拆出时需要分析每一个类有没有被其它类依赖,能不能够拆出到模块应用。
- 优势:直观
- 劣势:当 A 的依赖类众多,需要层层脑力递归。
方式三:使用 Koupleless 辅助工具,轻松分析!
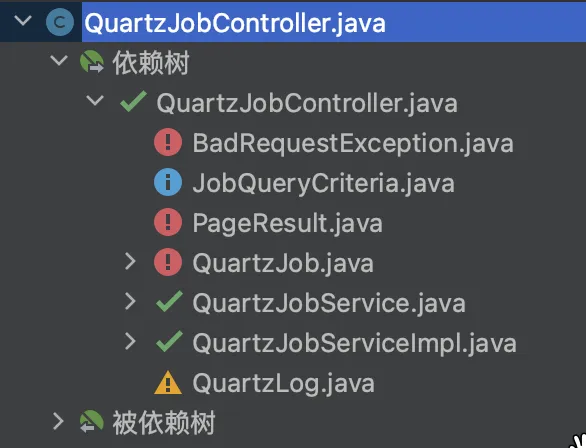
选择你想要分析的任意类文件,点击“分析依赖”,插件帮你分析~ 不仅帮你分析类文件依赖的类和 Bean,还提示你哪些类可以拆出,哪些类不能拆出。 以 QuartzJobController 为例,当选定的模块中有 QuartzJobController, QuartzJobService 和 QuartzJobServiceImpl 时,QuartzJobController 依赖的类和Bean关系如下图所示:
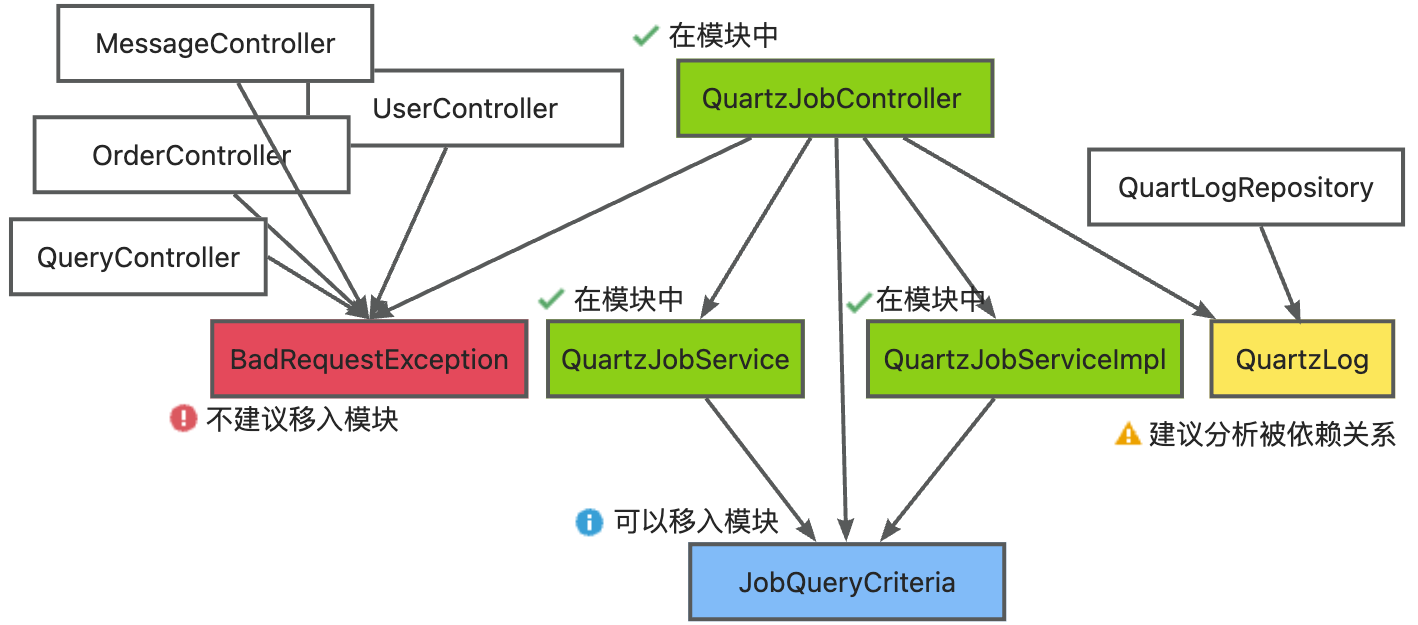
QuartzJobController 的依赖类/Bean 分为四类:已在模块、可移入模块、建议分析被依赖关系和不建议移入模块:
- 如果在模块中,则被标记为绿色“已在模块”,如: QuartzJobService 和 QuartzJobServiceImpl;
- 如果只被模块类依赖,那么被标记为蓝色“可移入模块”,如 JobQueryCriteria;
- 如果只被一个非模块类依赖,那么被标记为黄色“建议分析被依赖关系”,如 QuartLog;
- 如果被大量非模块类依赖,那么被标记为红色“不建议移入模块”,如 BadRequestException。
当使用插件对 QuartzJobController 和 JobQueryCriteria 进行分析时,依赖树和被依赖树如下,与上述分析对应:
 |  |
|---|
- 优势:直观、操作便捷、提示友好
- 劣势:插件只支持分析常见的 Bean 定义和类引用
步骤二:拆出到模块&修改单应用编码为多应用编码模式
选择相关的类文件拆出到模块。
方式一:复制粘贴每个文件、脑力分析所有模块基座之间的Bean调用、根据多应用编码模式修改代码。
在拆出时容易有灵魂发问:刚拆到哪儿了?这文件在没在模块里?我要不要重构这些包名?Bean调用跨应用吗?多应用编码的文档在哪?
- 优势:可以处理插件无法处理的多应用编码模式
- 劣势:用户不仅需要分析跨应用Bean依赖关系,还需要学习多应用编码方式,人工成本较高。
方式二:使用 Koupleless 辅助工具,轻松拆出!
根据你想要的模块目录结构,拖拽需要拆出的文件至面板。点击“拆出”,插件帮你分析,帮你根据 Koupleless 多应用编码模式修改~
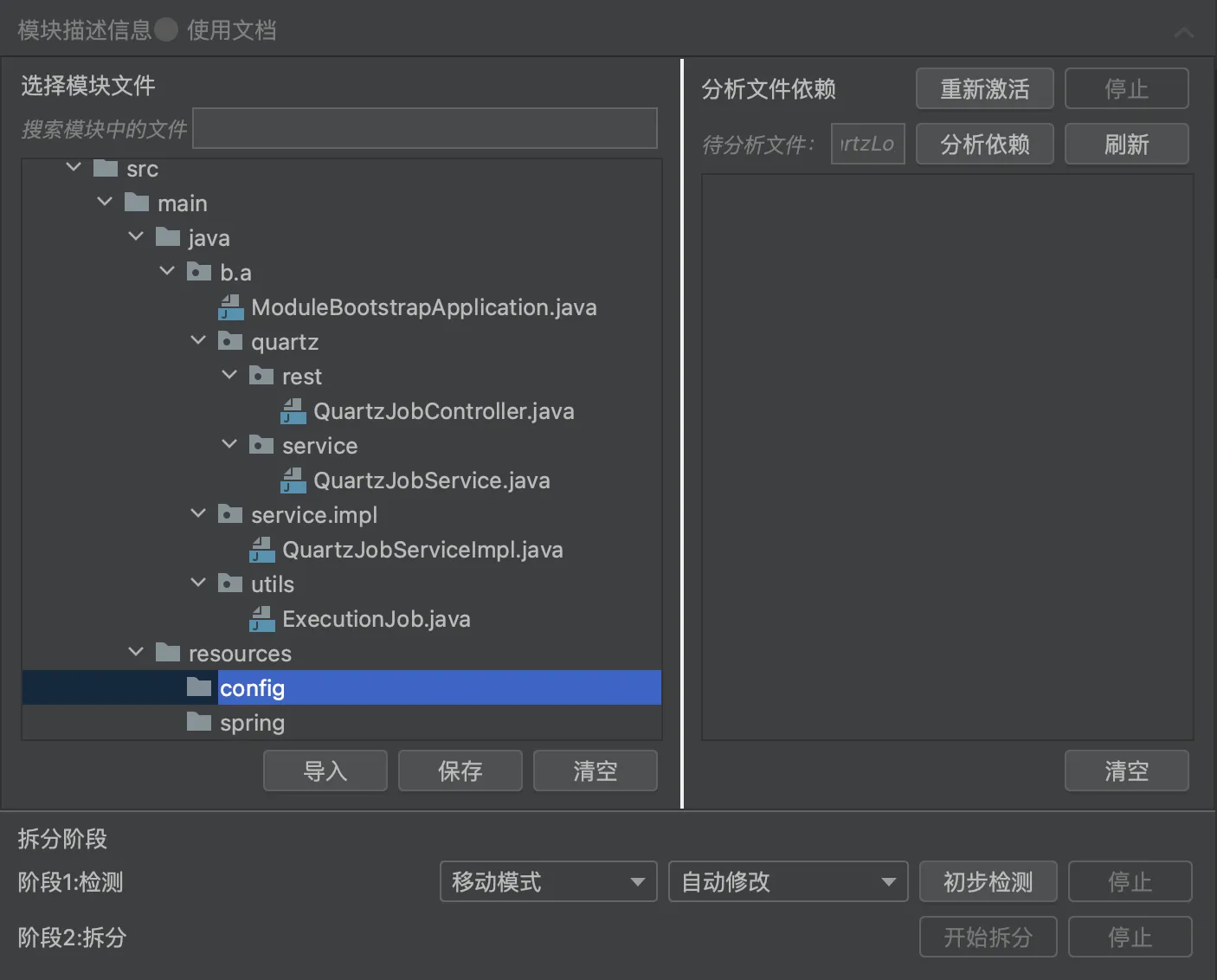
- 优势:直观、交互方便、插件自动修改跨应用 Bean 调用方式和部分特殊的多应用编码模式
- 劣势:插件只能根据部分多应用编码模式修改代码,因此用户需要了解插件能力的范围
技术方案
插件将整体流程分为 3 个阶段:分析阶段、交互阶段和自动化拆出阶段,整体流程如下图所示:
在分析阶段中,分析项目中的依赖关系,包括类依赖、Bean 依赖和特殊的多应用编码分析,如:MyBatis 配置依赖;
在交互阶段,可视化类文件之间的依赖关系和模块目录结构;
在自动化拆出阶段,插件首先将构建模块并整合配置,然后根据用户需要重构包名,接着修改模块基座 Bean 调用方式,并根据特殊的多应用编码修改代码,如:自动复用基座数据源。
接下来,我们将简单介绍分析阶段、交互阶段和自动化拆出阶段的主要技术。
分析阶段
插件分别使用 JavaParser 和 commons-configuration2 扫描项目中的 Java 文件和配置文件。
类依赖分析
为了准确地分析出项目的类依赖关系,插件需要完整分析一个类文件代码中所有使用到的项目类,即:分析代码中每个涉及类型的语句。
插件首先扫描所有类信息,然后用 JavaParser 扫描每一个类的代码代码,分析它依赖的项目类文件所有涉及类型的语句,并解析涉及到的类型,最后记录其关联关系。涉及类型的语句如下:
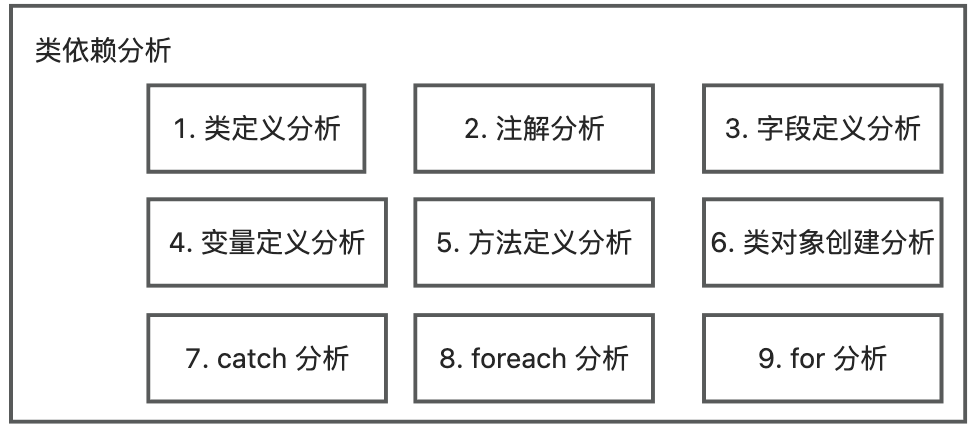
- 类定义分析: 解析父类类型和实现接口类型,作为引用的类型;
- 注解分析:解析注解类型,作为引用的类型;
- 字段定义分析:解析字段类型,作为引用的类型;
- 变量定义分析:解析变量类型,作为引用的类型;
- 方法定义分析:解析方法的返回类型、入参类型、注解以及抛出类型,作为引用的类型;
- 类对象创建分析:解析类对象创建语句的对象类型,作为引用的类型;
- catch分析:解析 catch 的对象类型,作为引用的类型;
- foreach分析:解析 foreach 的对象类型,作为引用的类型;
- for分析:解析 for 的对象类型,作为引用的类型;
为了快速解析对象类型,由于直接使用 JavaParser 解析较慢,因此先通过 imports 解析是否有匹配的类型,如果匹配失败,则使用 JavaParser 解析。
Bean 依赖分析
为了准确地分析出项目的Bean依赖关系,插件需要扫描项目中所有的 Bean 定义和依赖注入方式,然后通过静态代码分析的方式解析类文件依赖的所有项目 Bean。
Bean 定义主要有三种方式:类名注解、方法名注解和 xml。不同方式的 Bean 定义对应着不同的 Bean 依赖注入分析方式,最终依赖的 Bean 又由依赖注入类型决定,整体流程如下:
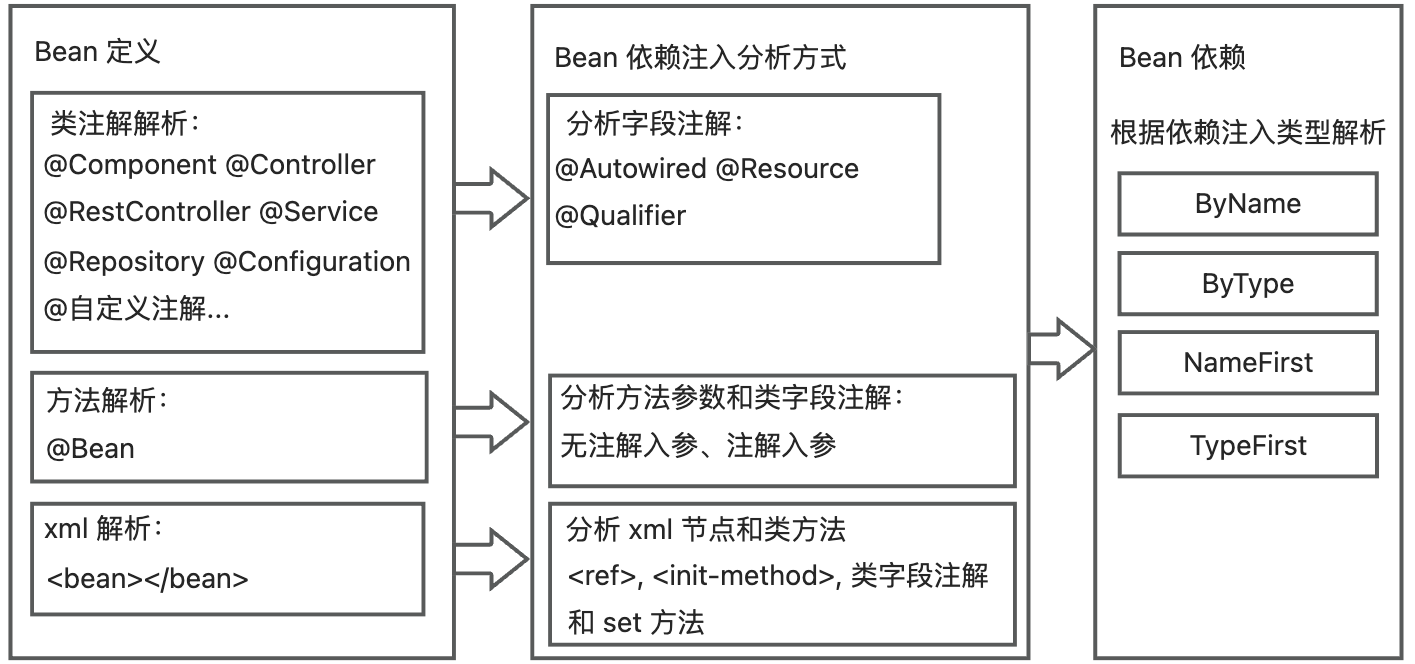
在扫描 Bean 时,解析并记录 bean 信息、依赖注入类型和依赖的Bean信息。
- 对于以类注解定义的类,将以字段注解,解析该字段的依赖注入类型和依赖的Bean信息。
- 对于以方法定义的类,将以入参信息,解析该入参数的依赖注入类型和依赖的Bean信息。
- 对于以 xml 定义的类,将通过解析 xml 和类方法的方式解析依赖注入:
- 以 和
解析 byName类型的依赖Bean信息 - 以字段解析依赖注入类型和依赖Bean信息。
- 如果 xml 的依赖注入方式不为 no,那么解析依赖注入类型和 set方法对应依赖Bean信息。
- 以 和
最后按照依赖注入类型,在项目记录的Bean定义中查找依赖的Bean信息,以实现Bean依赖关系的分析。
特殊的多应用编码分析
这里我们以 MyBatis 配置依赖分析为例。
在拆出 Mapper 至模块时,模块需要复用基座数据源,因此插件需要分析 Mapper 关联的所有 MyBatis 配置类。MyBatis 的各项配置类和 Mapper 文件之间通过 MapperScanner 配置连接,整体关系如下图:
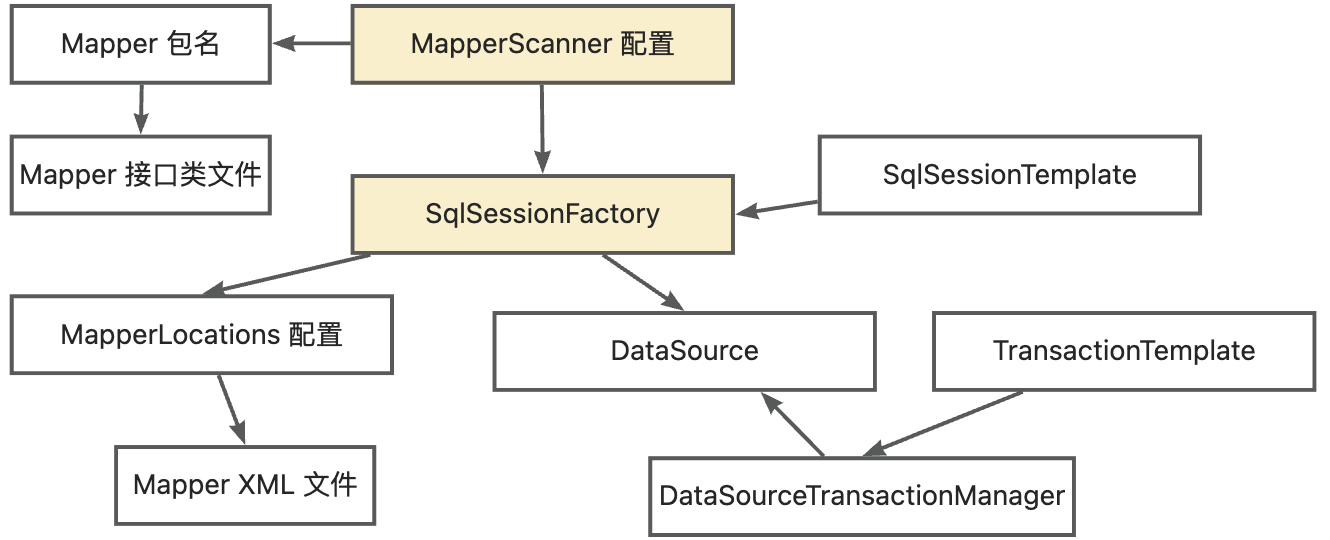
因此,插件记录所有的 Mapper 类文件和 XML 文件,解析与之关联的 MapperScanner,并解析与 MapperScanner 配置关联的所有 Mybatis 配置 Bean 信息。
交互阶段
这里简述依赖关系可视化和跨层级导入的实现。
- 可视化依赖关系:插件通过递归的方式解析所有类文件之间的依赖关系(包括类依赖关系和 Bean 依赖关系)。由于类文件间可能有循环依赖,因此使用缓存记录所有类文件节点。在递归时优先从缓存中取依赖节点,避免导致构建树节点时出现栈溢出问题。
- 跨层级导入:记录所有标记的选中文件,如果需选中了文件夹及文件夹中文件,导入时只导入标记过的文件。
自动化拆出阶段
这里简述包重命名、配置整合、Bean调用和特殊的多应用编码修改(以“复用基座数据源”为例)的实现。
- 包重命名:当用户自定义包名时,插件将修改类包名,并根据类依赖关系,将其 import 字段修改为新包的名称。
- 配置整合:针对子应用的每一个模块,读取所有拆出文件所在的原模块配置,并整合到新模块中;自动抽出子应用相关的 xml 的 bean 节点。
- Bean 调用:由上文分析的 Bean 依赖关系,插件过滤出模块和基座之间的 Bean 调用,并将字段注解(@Autowired @Resource @Qualifier) 修改为 @AutowiredFromBase 或 @AutowiredFromBiz
- 基座数据源复用:根据用户选择的 Mapper 文件及 MyBatis 配置依赖关系,抽取该 Mapper 相关的MyBatis 配置信息。然后把配置信息填充至数据源复用模板文件,保存在模块中。
未来展望
当前在内部已经完成上述功能开发,但还未正式开源,预计 2024年上半年将开源,敬请期待。
此外,在功能上,未来还需解决更多挑战:如何解决单测的拆分,如何验证拆出的多应用能力与单应用能力一致性。
欢迎更多感兴趣的同学关注 Koupleless 社区共同建设 Koupleless 生态。
Feedback
Was this page helpful?
Welcome propose feedback to community!
Welcome propose feedback to community, or improve this document directly.。