This is the multi-page printable view of this section. Click here to print.
6. Participate in the community
- 1: 6.1 The philosophy of openness and inclusivity
- 2: 6.2 Communication channels
- 3: 6.3 Community Contributions
- 3.1: 6.3.1 Local Development Testing
- 3.2: 6.3.2 Completing the First PR Submission
- 3.3: 6.3.3 Document, Issue, and Process Contribution
- 3.4: 6.3.4 Organizing Meetings and Promoting Operations
- 4: 6.4 Community Roles and Promotion
- 5: 6.5 Technical Principles
- 5.1: 6.5.1 SOFAArk Technical Documentation
- 5.2: 6.5.2 Arklet Architecture and Api Design
- 5.3: 6.5.3 Runtime Adaptation or Best Practices for Multi-Module Deployment
- 5.3.1: 6.5.3.1 Koupleless Multi-Application Governance Patch Management
- 5.3.2: 6.5.3.2 Koupleless Third-party Package Patch Guide
- 5.3.3: 6.5.3.2 Introduction to Multi-Module Integration Testing Framework
- 5.3.4: 6.5.3.3 Adapting to Multi-Module with Dubbo 2.7
- 5.3.5: 6.5.3.4 Best Practices for Multi-Module with ehcache
- 5.3.6: 6.5.3.5 Logback's adaptation for multi-module environments
- 5.3.7: 6.5.3.6 log4j2 Multi-Module Adaptation
- 5.3.8: 6.5.3.7 Module Use Bes
- 5.3.9: 6.5.3.8 Module Using Dubbo
- 5.3.10: 6.5.3.10 Introduction to the Principle of Class Delegation Loading between Foundation and Modules
- 5.3.11: 6.3.5.11 What happens if a module independently introduces part of the SpringBoot framework?
- 5.4: 6.5.4 Module Split Tool
- 6: 6.6 ModuleControllerV2 Technical Documentation
1 - 6.1 The philosophy of openness and inclusivity
Core Values
The core values of the Koupleless community are “openness” and “inclusivity”。All users and developers in the community are treated as equals, as reflected in the following aspects:
The community follows the operating model of Apache open-source projects. Anyone who contributes to the community, especially those who contribute non-code contributions (such as documentation, website, issue replies, advocacy, development suggestions, etc.), are considered contributors and have the opportunity to become committers or even PMC (Project Management Committee) members of the community.
All OKRs (Objectives and Key Results), roadmaps, discussions, meetings, technical solutions, etc., are completely open. Everyone can see and participate in them. The community listens and considers all suggestions and opinions, and once adopted, ensures execution and implementation. We encourage everyone to participate in the Koupleless community with an open mind and a spirit of seeking common ground while respecting differences.
The community is not limited by geographical boundaries or nationality. All source code must be commented in English to ensure understanding by everyone, and the official website is bilingual in both Chinese and English. All WeChat groups, DingTalk groups, and GitHub issue discussions can be conducted in both Chinese and English. However, since we currently focus mainly on Chinese users, most of the documentation is only available in Chinese for now, but we plan to provide English versions in the future.
2023 OKRs
O1 Build a healthy and influential Serverless open-source product community
KR1 Add 10 new contributors, increase OpenRank index to > 15 (currently 5), and activity level to > 50 (currently 44)
KR1.1 Conduct 5 advocacy events and 5 article shares, reaching out to 200 enterprises and engaging in-depth with 30+ enterprises.
KR1.2 Establish a complete community collaboration mechanism (including issue management, documentation, problem response, training, and promotion mechanisms), release 2+ training courses and product manuals, and enable developers to onboard within a week with a development throughput of 20+ issues/week.
KR2 Onboard 5 new enterprises to production or complete pilot integration (currently 1), with 3 enterprises participating in the community
KR2.1 Produce initial industry analysis reports to identify key enterprise targets for different scenarios.
KR2.2 Onboard 5 enterprises to production or complete pilot integration, with 3 enterprises participating in the community, covering 3 scenarios and documenting 3+ user cases.
O2 Develop advanced and cost-effective solutions for cost reduction and efficiency improvement
KR1 Implement modular technology to reduce machines by 30%, deployment verification time to 30 seconds, and increase delivery efficiency by 50%
KR1.1 Establish a 1-minute rapid trial platform with comprehensive documentation, website, and support, enabling users to complete module decomposition in 10 minutes.
KR1.2 Complete governance of 20 middleware and third-party packages, and establish multi-application and hot-unloading evaluation and automatic detection standards.
KR1.3 Reduce hot deployment startup time to the 10-second level, reduce resource consumption by 30% for multiple modules, and increase user delivery efficiency by 50%.
KR1.4 Launch the open-source version of Arklet, supporting SOFABoot and SpringBoot, providing operations pipeline, metric collection, module lifecycle management, multi-module runtime environment, and bean and service discovery and invocation capabilities.
KR1.5 Launch the development tool ArkCtl, featuring rapid development verification, flexible deployment (merge and independent deployment), and low-cost module decomposition and transformation capabilities.
KR2 Launch Operations and Scheduling 1.0 version. Achieve a success rate of 99.9% for end-to-end testing of the entire chain and a P90 end-to-end time of < 500ms
KR2.1 Launch open-source Operations and Scheduling capabilities based on K8S Operator, with at least publishing, rollback, offline, scaling in/out, replacement, replica maintenance, 2+ scheduling strategies, module flow control, deployment strategy, peer-to-peer and non-peer-to-peer operations capabilities.
KR2.2 Establish an open-source CI and 25+ high-frequency end-to-end test cases, continuously polish and promote end-to-end P90 time < 500ms, all pre-rehearsal success rate > 99.9%, and single test coverage rate reach line > 80%, branch > 60% (pass rate 100%).
KR3 Preliminary release of open-source auto-scaling. Modules have the ability for manual profiling and time-based scaling.
RoadMap
- Aug 2023 Complete deployment feature verification for SOFABoot, and establish compatibility benchmark baseline.
- Sep 2023 Release ModuleController 0.5 version of basic operations and scheduling system.
- Sep 2023 Release Arkctl and Arklet 0.5 versions of development and operations tools.
- Sep 2023 Launch official website and complete user manual.
- Oct 2023 Onboard 2+ companies for real use.
- Nov 2023 Support full capabilities of SpringBoot and 5+ commonly used middleware in the community.
- Nov 2023 Release Koupleless 0.8 version (ModuleController, Arkctl, Arklet, SpringBoot compatibility).
- Dec 2023 Release Koupleless 0.9 version (including basic auto-scaling, module basic decomposition tool, compatibility with 20+ middleware and third-party packages).
- Dec 2023 Onboard 5+ companies for real use, with 10+ contributors participating.
2 - 6.2 Communication channels
Koupleless provides the following communication channels for collaboration and interaction. Feel free to join us to share, use, and benefit together:
Koupleless Community Communication and Collaboration DingTalk Group: 24970018417
If you are interested in Koupleless, have a preliminary intention to use Koupleless, are already a user of Koupleless / SOFAArk, or are interested in becoming a community contributor, you are welcome to join this DingTalk group to communicate, discuss, and contribute code together at any time.
Koupleless WeChat Group

If you are interested in Koupleless, have preliminary intentions to use Koupleless, or are already a user of Koupleless / SOFAArk, you are welcome to join this WeChat group to discuss and communicate anytime, anywhere.
Community Bi-weekly Meeting
Community Meeting Every Two Weeks on Tuesday Evening from 19:30 to 20:30, The next community bi-weekly meeting will be held on November 28, 2023, from 19:30 to 20:30. Everyone is welcome to actively participate, either by listening or joining the discussion. The meeting will be conducted via DingTalk.Please find the joining details for the DingTalk meeting below:
Meeting Link: https://meeting.dingtalk.com/dialin/?corpId=dingd8e1123006514592
DingTalk Meeting ID: 90957500367
Dial-in Numbers: 057128095818 (Mainland China)、02162681677 (Mainland China)
You can also follow the community DingTalk collaboration group (Group ID: 24970018417) for specific meeting updates.。
The community PMC component members’ iteration planning meeting will be held on the last Monday of each month, discussing and finalizing the requirements planning for the next month.
3 - 6.3 Community Contributions
3.1 - 6.3.1 Local Development Testing
SOFAArk and Arklet
SOFAArk is a regular Java SDK project that uses Maven as its dependency management and build tool. You only need to install Maven 3.6 or higher locally to develop code and run unit tests normally, without any other environment preparation.
For details on code submission, please refer to: Completing the First PR Submission.
ModuleController
ModuleController is a standard K8S Golang Operator component, which includes ModuleDeployment Operator, ModuleReplicaSet Operator, and Module Operator. You can use minikube for local development testing. For details, please refer to Local Quick Start.
To compile and build, execute the following command in the module-controller directory:
go mod download # if compile module-controller first time
go build -a -o manager cmd/main.go
To run unit tests, execute the following command in the module-controller directory:
make test
You can also use an IDE for compiling, building, debugging, and running unit tests.
The development approach for module-controller is exactly the same as the standard K8S Operator development approach. You can refer to the official K8S Operator development documentation。
Arkctl
Arkctl is a regular Golang project, which is a command-line toolset that includes common tools for users to develop and maintain modules locally. You can refer here
3.2 - 6.3.2 Completing the First PR Submission
Claim or Submit an Issue
Regardless of whether you’re fixing a bug, adding a new feature, or improving an existing one, before you submit your code, please claim an issue on Koupleless or SOFAArk GitHub and assign yourself as the Assignee (novices are encouraged to claim tasks tagged with good-first-issue). Alternatively, submit a new issue describing the problem you want to fix or the feature you want to add or improve. Doing so helps avoid duplicate work with others.
Obtaining the Source Code
To modify or add features, after claiming or taking an existing issue, click the fork button in the upper left corner to make a copy of Koupleless or SOFAArk’s mainline code to your code repository.
Creating a Branch
All modifications to Koupleless and SOFAArk are made on individual branches. After forking the source code, you need to:
- Download the code to your local machine, either via git/https:
git clone https://github.com/your-username/koupleless.git
git clone https://github.com/your-username/sofa-ark.git
- Create a branch to prepare for modifying the code:
git branch add_xxx_feature
After executing the above command, your code repository will switch to the respective branch. You can verify your current branch by executing the following command:
git branch -a
If you want to switch back to the mainline, execute the following command:
git checkout -b master
If you want to switch back to a branch, execute the following command:
git checkout -b "branchName"
Modifying and Submitting Code Locally
After creating a branch, you can start modifying the code.
Things to Consider When Modifying Code
- Maintain consistent code style. Koupleless arklet and sofa-ark use Maven plugins to ensure consistent code formatting. Before submitting the code, make sure to execute:
mvn clean compile
The formatting capability for module-controller and arkctl’s Golang code is still under development.
- Include supplementary unit test code.
- Ensure that new modifications pass all unit tests.
- If it’s a bug fix, provide new unit tests to demonstrate that the previous code had bugs and that the new code fixes them. For arklet and sofa-ark, you can run all tests with the following command:
mvn clean test
For module-controller and arkctl, you can run all tests with the following command:
make test
You can also use an IDE to assist.
Other Considerations
- Please keep the code you edit in the original style, especially spaces, line breaks, etc.
- Delete unnecessary comments. Comments must be in English.
- Add comments to logic and functionalities that are not easily understood.
- Ensure to update the relevant documents in the
docs/content/zh-cn/directory, specifically in thedocsandcontribution-guidelinesdirectories.
After modifying the code, commit all changes to your local repository using the following command:
git commit -am 'Add xx feature'
Submitting Code to Remote Repository
After committing the code locally, it’s time to synchronize the code with the remote repository. Submit your local modifications to GitHub with the following command:
git push origin "branchname"
If you used fork earlier, then here “origin” pushes to your code repository, not Koupleless’s repository.
Requesting to Merge Code into Main Branch
After submitting the code to GitHub, you can request to merge your well-improved code into Koupleless’s or SOFAArk’s mainline code. At this point, you need to go to your GitHub repository and click the pull request button in the upper right corner. Select the target branch, usually master, and the Maintainer or PMC of the corresponding component as the Code Reviewer. If the PR pipeline check and Code Review are both successful, your code will be merged into the mainline and become a part of Koupleless.
PR Pipeline Check
The PR pipeline check includes:
- CLA signing. The first time you submit a PR, you must sign the CLA agreement. If you cannot open the CLA signing page, try using a proxy.
- Automatic appending of Apache 2.0 License declaration and author to each file.
- Execution of all unit tests, and all must pass.
- Checking if the coverage rate reaches line coverage >= 80% and branch coverage >= 60%.
- Detecting if the submitted code has security vulnerabilities.
- Checking if the submitted code complies with basic code standards.
All the above checks must pass for the PR pipeline to pass and enter the Code Review stage.
Code Review
If you choose the Maintainer or PMC of the corresponding component as the Code Reviewer, and after several days, there is still no response to your submission, you can leave a message below the PR and mention the relevant people, or directly mention them in the community DingTalk collaboration group (DingTalk group ID: 24970018417) to review the code. The comments on the Code Review will be directly noted in the corresponding PR or Issue. If you find the suggestions reasonable, please update your code accordingly and resubmit the PR.
Merging Code into Main Branch
After the PR pipeline check and Code Review are both successful, Koupleless maintainers will merge the code into the mainline. After the code is merged, you will receive a notification of successful merging.
3.3 - 6.3.3 Document, Issue, and Process Contribution
Documentation Contribution
Maintaining user documentation, technical documentation, and website content is a collective effort of every contributor in the community. Any student who contributes to any document or website content is considered a contributor, and based on their activity, they may have the opportunity to become a Committer or even a PMC member of Koupleless, jointly leading the technical evolution of Koupleless.
Issue Submission and Response Contribution
Any issues, bugs, new features, or improvements encountered during usage should be reported via GitHub Issues. Community members take turns each day to follow up on issues. Anyone who raises or responds to issues is a contributor to Koupleless. Contributors who actively respond to issues may be promoted to Committer status, and exceptionally active contributors may even be promoted to PMC members, jointly leading the technical evolution of Koupleless.
Issue Templates
There are two templates for Koupleless (including SOFAArk) Issues: “Question or Bug Report” and “Feature Request”. 
Question or Bug Report
For any issues encountered during usage or suspected bugs, please select “Question or Bug Report” and provide detailed replication information as follows:
### Describe the question or bug
A clear and concise description of what the question or bug is.
### Expected behavior
A clear and concise description of what you expected to happen.
### Actual behavior
A clear and concise description of what actually happened.
### Steps to reproduce
Steps to reproduce the problem:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
### Screenshots
If applicable, add screenshots to help explain your problem.
### Minimal yet complete reproducer code (or GitHub URL to code)
### Environment
- SOFAArk version:
- JVM version (e.g. `java -version`):
- OS version (e.g. `uname -a`):
- Maven version:
- IDE version:
Feature Request
For new features, improvements to existing features, or other discussions, please select “Feature Request”.
Process Contribution
Currently, Koupleless has established various collaboration standards such as code conventions, PR processes, CI pipelines, iteration management, weekly meetings, and communication channels. You can suggest improvements to our collaboration standards and processes on GitHub to become our contributor.
3.4 - 6.3.4 Organizing Meetings and Promoting Operations
We encourage everyone to promote and advocate for Koupleless, and through operations, become Koupleless contributors, committers, and even PMC members. Each promotion of a contributor will also be rewarded with commemorative prizes. Operation methods include but are not limited to:
- Delivering speeches on the use or technical implementation of Koupleless at online or offline technical conferences and meetups.
- Sharing and exchanging Koupleless usage scenarios with other companies.
- Publishing articles or videos related to the use or technical implementation of Koupleless on various channels.
- Other operational methods.
4 - 6.4 Community Roles and Promotion
Roles and Promotion Mechanism in the Koupleless Community
The roles in the Koupleless community are based on the organization model of Apache open-source projects, with each component (SOFAArk, Arklet, ModuleController, ArkCtl) having its own set of roles. The roles, from lowest to highest, are Contributor, Committer, PMC (Project Management Committee), and Maintainer
| Role | Responsibilities and Permissions | Promotion Mechanism to Higher Roles |
|---|---|---|
| Contributor | All students who provide Issues, answer Issues, operate externally, submit documentation content, or submit any code are Contributors of the corresponding component. Contributors have the permission to submit Issues, reply to Issues, submit content to the official website or documentation, submit code (excluding code review), and publish articles externally. | When a Contributor has merged enough code or documentation content, they can be promoted to Committer by a vote of PMC members of the component. When a Contributor has answered enough Issues or participated in enough operational activities, they can also be voted as a Committer by PMC members. |
| Committer | All students who actively answer Issues, operate externally, submit documentation content, or submit code have the potential to be voted as Committers by PMC members based on their activity level. Committers additionally have responsibilities and permissions for code review, technical proposal review, and Contributor cultivation. | Committers who have shown long-term active involvement or outstanding contributions can be promoted to PMC members of the corresponding component by a vote of PMC members. |
| PMC | Students who make sustained contributions and are particularly active in the corresponding component have the opportunity to be promoted to PMC members. PMC members additionally have responsibilities and permissions for RoadMap formulation, technical proposal and code review, Issue and iteration management, Contributor and Committer cultivation, etc. | |
| Maintainer | Maintainers have additional permissions for key management and repository management. Apart from this, they have equivalent responsibilities and permissions as PMC members in other aspects. |
Community Role Member List
SOFAArk
Maintainer
yuanyuancin
lvjing2
PMC (Project Management Comittee)
glmapper
Committer
zjulbj5
gaosaroma
QilongZhang133
straybirdzls13
caojie0911
Contributor
lylingzhen10
khotyn
FlyAbner (260+ commits, nominated for Comitter?)
alaneuler
sususama
ujjboy
JoeKerouac
Lunarscave
HzjNeverStop
AiWu4Damon
vchangpengfei
HuangDayu
shenchao45
DalianRollingKing
nobodyiam
lanicc
azhsmesos
wuqian0808
KangZhiDong
suntao4019
huangyunbin
jiangyunpeng
michalyao
rootsongjc
Zwl0113
tofdragon
lishiguang4
hionwi
343585776
g-stream
zkitcast
davidzj
zyclove
WindSearcher
lovejin52022
smalljunHw
vchangpengfei
sq1015
xwh1108
yuanChina
blysin
yuwenkai666
hadoop835
gitYupan
thirdparty-core
Estom
jijuanwang
DCLe-DA
linkoog
springcoco
zhaowwwjian
xingcici
ixufeng
jnan806
lizhi12q
kongqq
wangxiaotao00
Due to space limitations, Contributors who submitted issues before 23 are not listed here. We also thank everyone for their use and consultation of SOFAArk.
Arklet
Maintainer
yuanyuancin
lvjing2
PMC (Project Management Committee)
TomorJM
Committer
None
Contributor
glmapper
Lunarscave
lylingzhen
ModuleController
Maintainer
CodeNoobKing
PMC (Project Management Committee)
None
Committer
None
Contributor
liu-657667
Charlie17Li
lylingzhen
Arkctl
Maintainer
yuanyuancin
lvjing2
PMC (Project Management Committee)
None
Committer
None
Contributor
None
5 - 6.5 Technical Principles
5.1 - 6.5.1 SOFAArk Technical Documentation
SOFAArk 2.0 Introduction
Ark Container Startup Process
Ark Container Plugin Mechanism
Ark Container Class Loading Mechanism
Packaging Plugin Source Code Analysis
Startup Process Source Code Analysis
Dynamic Hot Deployment Source Code Analysis
Class Delegation Loading Source Code Analysis
Multi-Web Application Merge Deployment Source Code Analysis
5.2 - 6.5.2 Arklet Architecture and Api Design
English | 简体中文
Overview
Arklet provides an operational interface for delivery of SofaArk bases and modules. With Arklet, the release and operation of Ark Biz can be easily and flexibly operated.
Arklet is internally constructed by ArkletComponent
- ApiClient: The core components responsible for interacting with the outside world
- CommandService: Arklet exposes capability instruction definition and extension
- OperationService: Ark Biz interacts with SofaArk to add, delete, modify, and encapsulate basic capabilities
- HealthService: Based on health and stability, base, Biz, system and other indicators are calculated
The collaboration between them is shown in the figure

Of course, you can also extend Arklet’s component capabilities by implementing the ArkletComponent interface
Command Extension
The Arklet exposes the instruction API externally and handles the instruction internally through a CommandHandler mapped from each API.
CommandHandler related extensions belong to the unified management of the CommandService component
You can customize extension commands by inheriting AbstractCommandHandler
Build-in Command API
All of the following instruction apis access the arklet using the POST(application/json) request format
The http protocol is enabled and the default port is 1238
You can set
koupleless.arklet.http.portJVM startup parameters override the default port
Query the supported commands
- URL: 127.0.0.1:1238/help
- input sample:
{}
- output sample:
{
"code":"SUCCESS",
"data":[
{
"desc":"query all ark biz(including master biz)",
"id":"queryAllBiz"
},
{
"desc":"list all supported commands",
"id":"help"
},
{
"desc":"uninstall one ark biz",
"id":"uninstallBiz"
},
{
"desc":"switch one ark biz",
"id":"switchBiz"
},
{
"desc":"install one ark biz",
"id":"installBiz"
}
]
}
Install a biz
- URL: 127.0.0.1:1238/installBiz
- input sample:
{
"bizName": "test",
"bizVersion": "1.0.0",
// local path should start with file://, alse support remote url which can be downloaded
"bizUrl": "file:///Users/jaimezhang/workspace/github/sofa-ark-dynamic-guides/dynamic-provider/target/dynamic-provider-1.0.0-ark-biz.jar"
}
- output sample(success):
{
"code":"SUCCESS",
"data":{
"bizInfos":[
{
"bizName":"dynamic-provider",
"bizState":"ACTIVATED",
"bizVersion":"1.0.0",
"declaredMode":true,
"identity":"dynamic-provider:1.0.0",
"mainClass":"io.sofastack.dynamic.provider.ProviderApplication",
"priority":100,
"webContextPath":"provider"
}
],
"code":"SUCCESS",
"message":"Install Biz: dynamic-provider:1.0.0 success, cost: 1092 ms, started at: 16:07:47,769"
}
}
- output sample(failed):
{
"code":"FAILED",
"data":{
"code":"REPEAT_BIZ",
"message":"Biz: dynamic-provider:1.0.0 has been installed or registered."
}
}
Uninstall a biz
- URL: 127.0.0.1:1238/uninstallBiz
- input sample:
{
"bizName":"dynamic-provider",
"bizVersion":"1.0.0"
}
- output sample(success):
{
"code":"SUCCESS"
}
- output sample(failed):
{
"code":"FAILED",
"data":{
"code":"NOT_FOUND_BIZ",
"message":"Uninstall biz: test:1.0.0 not found."
}
}
Switch a biz
- URL: 127.0.0.1:1238/switchBiz
- input sample:
{
"bizName":"dynamic-provider",
"bizVersion":"1.0.0"
}
- output sample:
{
"code":"SUCCESS"
}
Query all Biz
- URL: 127.0.0.1:1238/queryAllBiz
- input sample:
{}
- output sample:
{
"code":"SUCCESS",
"data":[
{
"bizName":"dynamic-provider",
"bizState":"ACTIVATED",
"bizVersion":"1.0.0",
"mainClass":"io.sofastack.dynamic.provider.ProviderApplication",
"webContextPath":"provider"
},
{
"bizName":"stock-mng",
"bizState":"ACTIVATED",
"bizVersion":"1.0.0",
"mainClass":"embed main",
"webContextPath":"/"
}
]
}
Query Health
- URL: 127.0.0.1:1238/health
Query All Health Info
- input sample:
{}
- output sample:
{
"code": "SUCCESS",
"data": {
"healthData": {
"jvm": {
"max non heap memory(M)": -9.5367431640625E-7,
"java version": "1.8.0_331",
"max memory(M)": 885.5,
"max heap memory(M)": 885.5,
"used heap memory(M)": 137.14127349853516,
"used non heap memory(M)": 62.54662322998047,
"loaded class count": 10063,
"init non heap memory(M)": 2.4375,
"total memory(M)": 174.5,
"free memory(M)": 37.358726501464844,
"unload class count": 0,
"total class count": 10063,
"committed heap memory(M)": 174.5,
"java home": "****\\jre",
"init heap memory(M)": 64.0,
"committed non heap memory(M)": 66.203125,
"run time(s)": 34.432
},
"cpu": {
"count": 4,
"total used (%)": 131749.0,
"type": "****",
"user used (%)": 9.926451054656962,
"free (%)": 81.46475495070172,
"system used (%)": 6.249762806548817
},
"masterBizInfo": {
"webContextPath": "/",
"bizName": "bookstore-manager",
"bizState": "ACTIVATED",
"bizVersion": "1.0.0"
},
"pluginListInfo": [
{
"artifactId": "web-ark-plugin",
"groupId": "com.alipay.sofa",
"pluginActivator": "com.alipay.sofa.ark.web.embed.WebPluginActivator",
"pluginName": "web-ark-plugin",
"pluginUrl": "file:/****/2.2.3-SNAPSHOT/web-ark-plugin-2.2.3-20230901.090402-2.jar!/",
"pluginVersion": "2.2.3-SNAPSHOT"
},
{
"artifactId": "runtime-sofa-boot-plugin",
"groupId": "com.alipay.sofa",
"pluginActivator": "com.alipay.sofa.runtime.ark.plugin.SofaRuntimeActivator",
"pluginName": "runtime-sofa-boot-plugin",
"pluginUrl": "file:/****/runtime-sofa-boot-plugin-3.11.0.jar!/",
"pluginVersion": "3.11.0"
}
],
"masterBizHealth": {
"readinessState": "ACCEPTING_TRAFFIC"
},
"bizListInfo": [
{
"bizName": "bookstore-manager",
"bizState": "ACTIVATED",
"bizVersion": "1.0.0",
"webContextPath": "/"
}
]
}
}
}
Query System Health Info
- input sample:
{
"type": "system",
// [OPTIONAL] if metrics is null -> query all system health info
"metrics": ["cpu", "jvm"]
}
- output sample:
{
"code": "SUCCESS",
"data": {
"healthData": {
"jvm": {...},
"cpu": {...},
// "masterBizHealth": {...}
}
}
}
Query Biz Health Info
- input sample:
{
"type": "biz",
// [OPTIONAL] if moduleName is null and moduleVersion is null -> query all biz
"moduleName": "bookstore-manager",
// [OPTIONAL] if moduleVersion is null -> query all biz named moduleName
"moduleVersion": "1.0.0"
}
- output sample:
{
"code": "SUCCESS",
"data": {
"healthData": {
"bizInfo": {
"bizName": "bookstore-manager",
"bizState": "ACTIVATED",
"bizVersion": "1.0.0",
"webContextPath": "/"
}
// "bizListInfo": [
// {
// "bizName": "bookstore-manager",
// "bizState": "ACTIVATED",
// "bizVersion": "1.0.0",
// "webContextPath": "/"
// }
// ]
}
}
}
Query Plugin Health Info
- input sample:
{
"type": "plugin",
// [OPTIONAL] if moduleName is null -> query all biz
"moduleName": "web-ark-plugin"
}
- output sample:
{
"code": "SUCCESS",
"data": {
"healthData": {
"pluginListInfo": [
{
"artifactId": "web-ark-plugin",
"groupId": "com.alipay.sofa",
"pluginActivator": "com.alipay.sofa.ark.web.embed.WebPluginActivator",
"pluginName": "web-ark-plugin",
"pluginUrl": "file:/****/web-ark-plugin-2.2.3-20230901.090402-2.jar!/",
"pluginVersion": "2.2.3-SNAPSHOT"
}
]
}
}
}
Query Health Using Endpoint
use endpoint for k8s module to get helath info
default config
- endpoints exposure include:
* - endpoints base path:
/ - endpoints sever port:
8080
http code result
HEALTHY(200): get health if all health indicator is healthyUNHEALTHY(400): get health once a health indicator is unhealthyENDPOINT_NOT_FOUND(404): endpoint path or params not foundENDPOINT_PROCESS_INTERNAL_ERROR(500): get health process throw an error
query all health info
- url: 127.0.0.1:8080/arkletHealth
- method: GET
- output sample
{
"healthy": true,
"code": 200,
"codeType": "HEALTHY",
"data": {
"jvm": {...},
"masterBizHealth": {...},
"cpu": {...},
"masterBizInfo": {...},
"bizListInfo": [...],
"pluginListInfo": [...]
}
}
query all biz/plugin health info
- url: 127.0.0.1:8080/arkletHealth/{moduleType} (moduleType must in [‘biz’, ‘plugin’])
- method: GET
- output sample
{
"healthy": true,
"code": 200,
"codeType": "HEALTHY",
"data": {
"bizListInfo": [...],
// "pluginListInfo": [...]
}
}
query single biz/plugin health info
- url: 127.0.0.1:8080/arkletHealth/{moduleType}/moduleName/moduleVersion (moduleType must in [‘biz’, ‘plugin’])
- method: GET
- output sample
{
"healthy": true,
"code": 200,
"codeType": "HEALTHY",
"data": {
"bizInfo": {...},
// "pluginInfo": {...}
}
}
5.3 - 6.5.3 Runtime Adaptation or Best Practices for Multi-Module Deployment
5.3.1 - 6.5.3.1 Koupleless Multi-Application Governance Patch Management
Why Koupleless Needs Multi-Application Governance Patching?
Koupleless is a multi-application architecture, and traditional middleware may only consider scenarios for a single application. Therefore, in some cases, it is incompatible with multi-application coexistence, leading to problems such as shared variable contamination, classloader loading exceptions, and unexpected class judgments. Thus, when using Koupleless middleware, we need to patch some potential issues, covering the original middleware implementation, allowing open-source middleware to be compatible with the multi-application mode.
Research on Multi-Application Governance Patching Solutions for Koupleless
In multi-application compatibility governance, we not only consider production deployment but also need to consider compatibility with local user development (IDEA click Debug), compatibility with unit testing (e.g., @SpringbootTest), and more.
Below is a comparison table of different solutions.
Solution Comparison
| Solution Name | Access Cost | Maintainability | Deployment Compatibility | IDE Compatibility | Unit Testing Compatibility |
|---|---|---|---|---|---|
| A: Place the patch package dependency at the beginning of maven dependency to ensure that the patch class is loaded first by the classLoader. | Low. Users only need to control the order of Maven dependencies. | Low Users need to ensure that the relevant dependencies are at the front, and the classpath is not manually passed during startup. | Compatible✅ | Compatible✅ | Compatible✅ |
| B: Modify the indexing file order of spring boot build artifacts using maven plugins. | Low. Just need to add a package cycle maven plugin, user perception is low. | Medium Users need to ensure that the classpath is not manually passed during startup. | Compatible✅ | Not compatible❌ JetBrains cannot be compatible, JetBrains will build the CLI command line by itself to pass the classpath according to the order of Maven dependencies, which may lead to suboptimal loading order of the adapter. | Not compatible❌ Unit tests do not go through the repackage cycle and do not depend on the classpath.idx file. |
| C: Add a custom spring boot jarlaunch starter to control the classLoader loading behavior through the starter. | High. Users need to modify their own base startup logic to use Koupleless’ custom jarlaunch. | High Custom jarlaunch can control the code loading order through hooks. | Compatible✅ | Compatible✅ But IDE needs to be configured to use custom jarlaunch. | Not compatible❌ Because unit tests do not go through the jarlaunch logic. |
| D: Enhance the base classloader to ensure priority searching and loading of patch classes. | High. Users need to initialize enhanced code, and this mode also has an impact on the sofa-ark recognition logic of the master biz, and needs to be refactored to support. | High The base classloader can programmatically control the loading order of dependencies. | Compatible✅ | Compatible✅ | Compatible✅ |
| E: Configure the maven plugin to copy patch class code to the current project, and the files in the current project will be loaded first. | High. Maven’s current copy plugin cannot use wildcards, so adding an adapter requires additional configuration. | High As long as users configure it, they can ensure that dependencies are loaded first (because the classes of the local project are loaded first). | Compatible✅ | Compatible✅ | Not compatible❌ Because unit tests do not go through the package cycle, and the maven copy plugin takes effect during the package cycle. |
Conclusion
Overall, it is not possible to achieve user 0 perception access completely, and each method requires minor business refactoring. Among many solutions, A and D can achieve full compatibility. However, the A solution does not require business code changes, nor does it intrude into runtime logic. It only requires users to add the following dependency at the beginning of the maven dependency:
<dependency>
<groupId>com.alipay.koupleless</groupId>
<artifactId>koupleless-base-starter</artifactId>
<version>${koupleless.runtime.version}</version>
<type>pom</type>
</dependency>
Therefore, we will adopt solution A.
If you have more ideas or input, welcome to discuss them with the open-source community!
5.3.2 - 6.5.3.2 Koupleless Third-party Package Patch Guide
Principle of Koupleless Third-party Package Patches
Koupleless is an architecture designed for multiple applications, whereas traditional middleware might only consider a single application scenario. Therefore, in some behaviors, it cannot accommodate the coexistence of multiple applications, leading to issues such as shared variable pollution, classLoader loading anomalies, and unexpected class judgments.
Therefore, when using Koupleless middleware, we need to apply patches to some potential issues, overriding the original middleware implementation, so that open-source middleware can also be compatible with a multi-application model.
‼️ Version Requirements: koupleless-base-build-plugin
- jdk8: >= 1.3.3
- jdk17: >= 2.2.8
Currently, the principle of Koupleless third-party package patches taking effect is:
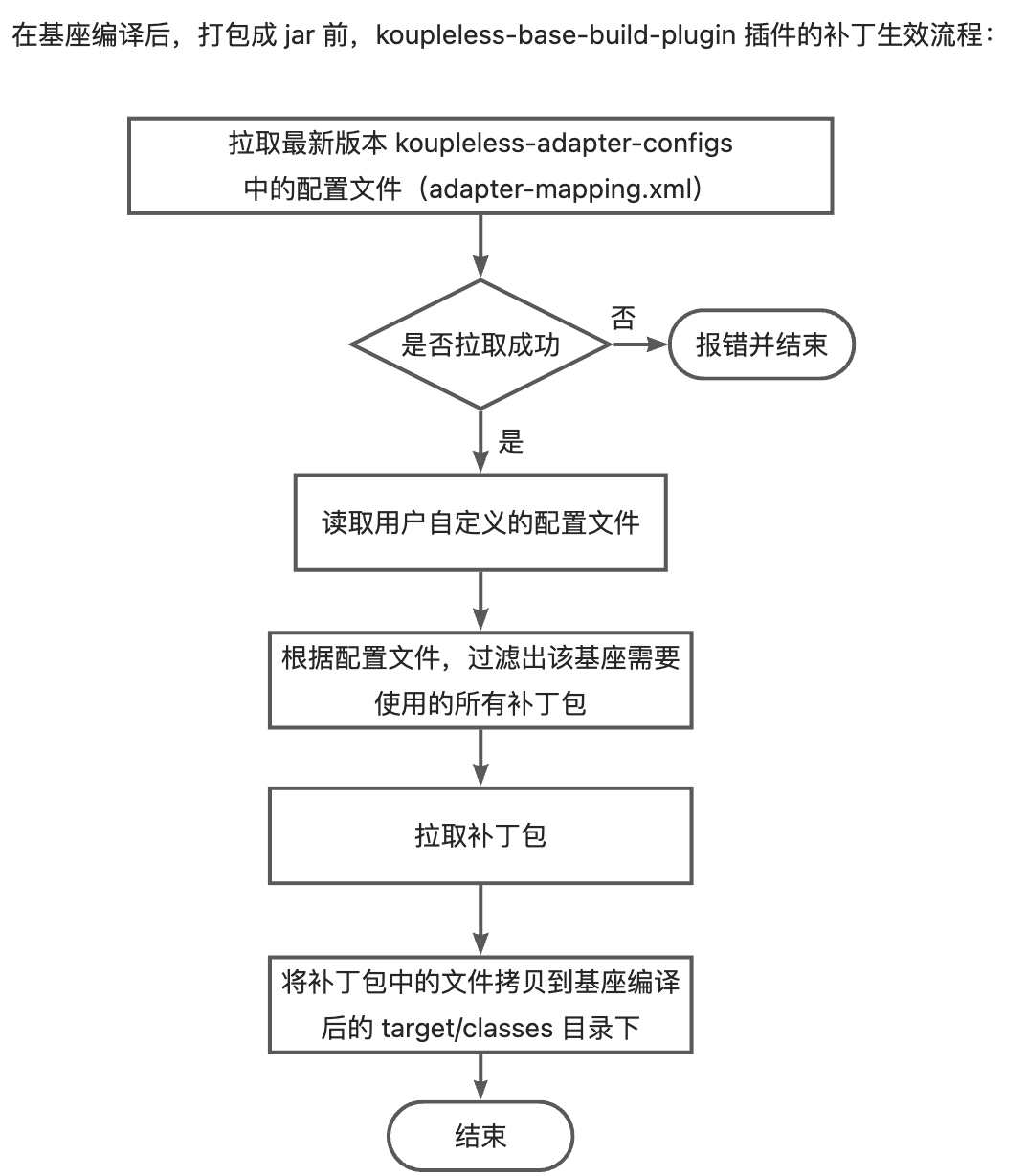
- After the base compilation and before packaging, the koupleless-base-build-plugin plugin will obtain the adapter configuration file, which describes the
middleware dependencies within the version rangethat use the patch packages, for example:
version: 1.2.3
adapterMappings:
- matcher:
groupId: org.springframework.boot
artifactId: spring-boot
versionRange: "[2.5.1,2.7.14]"
adapter:
artifactId: koupleless-adapter-spring-boot-logback-2.7.14
groupId: com.alipay.sofa.koupleless
The meaning of this configuration file is: When the base depends on org.springframework.boot:spring-boot versions within the range [2.5.1, 2.7.14], then use the koupleless-adapter-spring-boot-logback-2.7.14 patch package version 1.2.3.
- Obtain all dependencies used by the base, filter out all the patch packages required by the base according to the adapter configuration file;
- Pull the patch packages and copy the files from the patch packages to the target/classes directory after the base compilation.
There are two types of adapter configuration files:
- Configuration files managed by Koupleless: During packaging, the koupleless-base-build-plugin plugin will attempt to pull the latest version of the adapter configuration file; if the pull fails, it will throw error and terminate. Currently, the open-source third-party package patches managed by Koupleless are in the koupleless-adapter repository, with over 20 patch packages available.
- User-defined configuration files: Users can add their own adapter configuration files to the base, and these configuration files will take effect alongside the general configuration files managed by Koupleless.
How to Develop Open-source Third-party Package Patches
👏 Welcome everyone to contribute to the development of open-source third-party package patches:
- Develop patch code files: Copy the files that need to be patched, modify the code to make it suitable for a multi-application scenario.
- Confirm the version range of the dependency package where the patch takes effect (i.e., within this version range, the code files of the open-source package are completely identical), for example, for org.springframework.boot:spring-boot versions within the range [2.5.1, 2.7.14], the
org.springframework.boot.logging.logback.LogbackLoggingSystemfile is the same. - In the koupleless-adapter repository, create a patch package module, such as
koupleless-adapter-spring-boot-logback-2.7.14, and overwrite the files that need to be patched in this module, for example,org.springframework.boot.logging.logback.LogbackLoggingSystem. - In the root directory of
koupleless-adapter-spring-boot-logback-2.7.14, create aconf/adapter-mappings.yamlfile to describe the matching rules for the patch to take effect, and complete unit tests. - Submit a PR
For example, the code for the koupleless-adapter-spring-boot-logback-2.7.14 patch package can be found at koupleless-adapter-spring-boot-logback-2.7.14.
How to Develop Internal Second-party Package Patches
- Develop patch code files: Copy the files that need to be patched, modify the code to make it suitable for a multi-application scenario.
- Confirm the version range of the dependency package where the patch takes effect (i.e., within this version range, the code files of the second-party package are completely identical), for example, for yyy:xxx versions within the range [2.5.1, 2.7.14], the
yyy.xxx.CustomSystemfile is the same. - Develop a patch package, such as
koupleless-adapter-xxx-2.1.0, and overwrite the files that need to be patched in this package, for example,com.xxx.YYY, and package and release it as a jar file. - Add the dependency configuration for the patch package in the base’s
conf/ark/adapter-mapping.yaml. For example:
adapterMappings:
- matcher:
groupId: yyy
artifactId: xxx
versionRange: "[2.5.1,2.7.14]"
adapter:
artifactId: koupleless-adapter-xxx-2.1.0
groupId: yyy
version: 1.0.0
5.3.3 - 6.5.3.2 Introduction to Multi-Module Integration Testing Framework
This article focuses on the design concepts, implementation details, and usage of the multi-module integration testing framework.
Why Do We Need a Multi-Module Integration Testing Framework?
Assuming there is no integration testing framework, when developers want to verify whether the deployment process of multiple modules behaves correctly, they need to follow these steps:
- Build the base and JAR packages for all modules.
- Start the base process.
- Install the module JAR packages into the base.
- Invoke HTTP/RPC interfaces.
- Verify whether the returned results are correct.
Although the above workflow appears simple, developers face several challenges:
- Constantly switching back and forth between the command line and the code.
- If the validation results are incorrect, they need to repeatedly modify the code and rebuild + remote debug.
- If the app only provides internal methods, they must modify the code to expose interfaces via HTTP/RPC to validate the behavior of the multi-module deployment.
These challenges lead to low efficiency and an unfriendly experience for developers. Therefore, we need an integration testing framework to provide a one-stop validation experience.
What Problems Should the Integration Testing Framework Solve?
The integration testing framework needs to simulate the behavior of multi-module deployment in the same process with a single start. It should also allow developers to directly call code from the modules/base to verify module behavior.
The framework needs to solve the following technical problems:
- Simulate the startup of the base Spring Boot application.
- Simulate the startup of module Spring Boot applications, supporting loading modules directly from dependencies instead of JAR packages.
- Simulate the loading of Ark plugins.
- Ensure compatibility with Maven’s testing commands.
By default, Sofa-ark loads modules through executable JAR packages and Ark plugins. Therefore, developers would need to rebuild JAR packages or publish to repositories during each validation, reducing validation efficiency. The framework needs to intercept the corresponding loading behavior and load modules directly from Maven dependencies to simulate multi-module deployment.
The code that accomplishes these tasks includes:
- TestBizClassLoader: Simulates loading the biz module and is a derived class of the original BizClassLoader, solving the problem of loading classes on demand to different ClassLoaders within the same JAR package.
- TestBiz: Simulates starting the biz module and is a derived class of the original Biz, encapsulating the logic for initializing TestBizClassLoader.
- TestBootstrap: Initializes ArkContainer and loads Ark plugins.
- TestClassLoaderHook: Controls the loading order of resources via a hook mechanism. For instance, application.properties in the biz JAR package will be loaded first.
- BaseClassLoader: Simulates normal base ClassLoader behavior and is compatible with testing frameworks like Surefire.
- TestMultiSpringApplication: Simulates the startup behavior of multi-module Spring Boot applications.
How to Use the Integration Testing Framework?
Start Both Base and Module Spring Boot Applications in the Same Process
Sample code is as follows:
public void demo() {
new TestMultiSpringApplication(MultiSpringTestConfig
.builder()
.baseConfig(BaseSpringTestConfig
.builder()
.mainClass(BaseApplication.class) // Base startup class
.build())
.bizConfigs(Lists.newArrayList(
BizSpringTestConfig
.builder()
.bizName("biz1") // Name of module 1
.mainClass(Biz1Application.class) // Startup class of module 1
.build(),
BizSpringTestConfig
.builder()
.bizName("biz2") // Name of module 2
.mainClass(Biz2Application.class) // Startup class of module 2
.build()
))
.build()
).run();
}
Write Assert Logic
You can retrieve module services using the following method:
public void getService() {
StrategyService strategyService = SpringServiceFinder.
getModuleService(
"biz1-web-single-host",
"0.0.1-SNAPSHOT",
"strategyServiceImpl",
StrategyService.class
);
}
After obtaining the service, you can write assert logic.
Reference Use Cases
For more comprehensive use cases, you can refer to Tomcat Multi-Module Integration Testing Cases.
5.3.4 - 6.5.3.3 Adapting to Multi-Module with Dubbo 2.7
Why Adaptation is Needed
The native Dubbo 2.7 cannot support module publishing its own Dubbo services in multi-module scenarios, leading to a series of issues such as serialization and class loading exceptions during invocation.
Multi-Module Adaptation Solutions
Dubbo 2.7 Multi-Module Adaptation SDK will be included when building by koupleless-base-build-plugin, the adapter mainly from aspects such as class loading, service publishing, service unloading, service isolation, module-level service management, configuration management, serialization, etc.
1. AnnotatedBeanDefinitionRegistryUtils Unable to Load Module Classes Using the Base Classloader
com.alibaba.spring.util.AnnotatedBeanDefinitionRegistryUtils#isPresentBean
public static boolean isPresentBean(BeanDefinitionRegistry registry, Class<?> annotatedClass) {
...
// ClassLoader classLoader = annotatedClass.getClassLoader(); // Original logic
ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); // Changed to use tccl to load classes
for (String beanName : beanNames) {
BeanDefinition beanDefinition = registry.getBeanDefinition(beanName);
if (beanDefinition instanceof AnnotatedBeanDefinition) {
...
String className = annotationMetadata.getClassName();
Class<?> targetClass = resolveClassName(className, classLoader);
...
}
}
return present;
}
2. Module-Level Service and Configuration Resource Management
- com.alipay.sofa.koupleless.support.dubbo.ServerlessServiceRepository Replaces the Native org.apache.dubbo.rpc.model.ServiceRepository
The native service uses the interfaceName as the cache key. When both the base and the module publish services with the same interface but different groups, it cannot distinguish between them. Replacing the native service caching model, using the Interface Class type as the key, and using the path containing the group as the key to support scenarios where the base and the module publish services with the same interface but different groups.
private static ConcurrentMap<Class<?>, ServiceDescriptor> globalClassServices = new ConcurrentHashMap<>();
private static ConcurrentMap<String, ServiceDescriptor> globalPathServices = new ConcurrentHashMap<>();
com.alipay.sofa.koupleless.support.dubbo.ServerlessConfigManager Replaces the Native org.apache.dubbo.config.context.ConfigManager
Adds a classloader dimension key to the original config to isolate different configurations according to classloader in different modules.
final Map<ClassLoader, Map<String, Map<String, AbstractConfig>>> globalConfigsCache = new HashMap<>();
public void addConfig(AbstractConfig config, boolean unique) {
...
write(() -> {
Map<String, AbstractConfig> configsMap = getCurrentConfigsCache().computeIfAbsent(getTagName(config.getClass()), type -> newMap());
addIfAbsent(config, configsMap, unique);
});
}
private Map<String, Map<String, AbstractConfig>> getCurrentConfigsCache() {
ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader(); // Based on the current thread classloader to isolate different configuration caches
globalConfigsCache.computeIfAbsent(contextClassLoader, k -> new HashMap<>());
return globalConfigsCache.get(contextClassLoader);
}
ServerlessServiceRepository and ServerlessConfigManager both depend on the dubbo ExtensionLoader’s extension mechanism to replace the original logic. For specific principles, please refer to org.apache.dubbo.common.extension.ExtensionLoader.createExtension.
3. Module-Level Service Install and Uninstall
override DubboBootstrapApplicationListener to prevent the original Dubbo module from starting or uninstalling when publishing or uninstalling services
- com.alipay.sofa.koupleless.support.dubbo.BizDubboBootstrapListener
The native Dubbo 2.7 only publishes Dubbo services after the base module is started. In the case of multi-modules, it cannot support module-level service publishing. Ark listens for module startup events using a listener and manually calls Dubbo to publish module-level services.
private void onContextRefreshedEvent(ContextRefreshedEvent event) {
try {
ReflectionUtils.getMethod(DubboBootstrap.class, "exportServices")
.invoke(dubboBootstrap);
ReflectionUtils.getMethod(DubboBootstrap.class, "referServices").invoke(dubboBootstrap);
} catch (Exception e) {
}
}
The original Dubbo 2.7 unexports all services in the JVM when a module is uninstalled, leading to the unexporting of services from the base and other modules after the module is uninstalled. Ark listens for the spring context closing event of the module and manually unexports Dubbo services of the current module, retaining Dubbo services of the base and other modules.
private void onContextClosedEvent(ContextClosedEvent event) {
// DubboBootstrap.unexportServices unexports all services, only need to unexport services of the current biz
Map<String, ServiceConfigBase<?>> exportedServices = ReflectionUtils.getField(dubboBootstrap, DubboBootstrap.class, "exportedServices");
Set<String> bizUnexportServices = new HashSet<>();
for (Map.Entry<String, ServiceConfigBase<?>> entry : exportedServices.entrySet()) {
String serviceKey = entry.getKey();
ServiceConfigBase<?> sc = entry.getValue();
if (sc.getRef().getClass().getClassLoader() == Thread.currentThread().getContextClassLoader()) { // Distinguish module services based on the classloader of ref service implementation
bizUnexportServices.add(serviceKey);
configManager.removeConfig(sc); // Remove service configuration from configManager
sc.unexport(); // Unexport service
serviceRepository.unregisterService(sc.getUniqueServiceName()); // Remove from serviceRepository
}
}
for (String service : bizUnexportServices) {
exportedServices.remove(service); // Remove service from DubboBootstrap
}
}
4. Service Routing
- com.alipay.sofa.koupleless.support.dubbo.ConsumerRedefinePathFilter
When invoking Dubbo services, the service model (including interface, param, return types, etc.) is obtained from the ServiceRepository based on the path to perform service invocation, parameter, and return value serialization. The original Dubbo 2.7 uses interfaceName as the path to find the service model, which cannot support the scenario where the base module and other modules publish services with the same interface. Ark adds group information to the path on the consumer side through a custom filter to facilitate correct service routing on the provider side.
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
if (invocation instanceof RpcInvocation) {
RpcInvocation rpcInvocation = (RpcInvocation) invocation;
// Original path is interfaceName, such as com.alipay.sofa.rpc.dubbo27.model.DemoService
// Modified path is serviceUniqueName, such as masterBiz/com.alipay.sofa.rpc.dubbo27.model.DemoService
rpcInvocation.setAttachment("interface", rpcInvocation.getTargetServiceUniqueName()); // Original path is interfaceName, such as
}
return invoker.invoke(invocation);
}
5. Serialization
- org.apache.dubbo.common.serialize.java.JavaSerialization
- org.apache.dubbo.common.serialize.java.ClassLoaderJavaObjectInput
- org.apache.dubbo.common.serialize.java.ClassLoaderObjectInputStream
When obtaining the serialization tool JavaSerialization, use ClassLoaderJavaObjectInput instead of the original JavaObjectInput and pass provider-side service classloader information.
// org.apache.dubbo.common.serialize.java.JavaSerialization
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new ClassLoaderJavaObjectInput(new ClassLoaderObjectInputStream(null, is)); // Use ClassLoaderJavaObjectInput instead of the original JavaObjectInput, pass provider-side service classloader information
}
// org.apache.dubbo.common.serialize.java.ClassLoaderObjectInputStream
private ClassLoader classLoader;
public ClassLoaderObjectInputStream(final ClassLoader classLoader, final InputStream inputStream) {
super(inputStream);
this.classLoader = classLoader;
}
- org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcResult Client-side deserialization of return values
// patch begin
if (in instanceof ClassLoaderJavaObjectInput) {
InputStream is = ((ClassLoaderJavaObjectInput) in).getInputStream();
if (is instanceof ClassLoaderObjectInputStream) {
ClassLoader cl = serviceDescriptor.getServiceInterfaceClass().getClassLoader(); // Set provider-side service classloader information to ClassLoaderObjectInputStream
((ClassLoaderObjectInputStream) is).setClassLoader(cl);
}
}
// patch end
- org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcResult Client-side deserialization of return values
// patch begin
if (in instanceof ClassLoaderJavaObjectInput) {
InputStream is = ((ClassLoaderJavaObjectInput) in).getInputStream();
if (is instanceof ClassLoaderObjectInputStream) {
ClassLoader cl = invocation.getInvoker().getInterface().getClassLoader(); // Set consumer-side service classloader information to ClassLoaderObjectInputStream
((ClassLoaderObjectInputStream) is).setClassLoader(cl);
}
}
// patch end
Example of Using Dubbo 2.7 in a Multi-Module Environment
5.3.5 - 6.5.3.4 Best Practices for Multi-Module with ehcache
Why Best Practices are Needed
During CacheManager initialization, there are shared static variables causing issues when multiple applications use the same Ehcache name, resulting in cache overlap.
Requirements for Best Practices
- Base module must include Ehcache, and modules should reuse the base.
In Spring Boot, Ehcache initialization requires creating it through the EhCacheCacheConfiguration defined in Spring, which belongs to Spring and is usually placed in the base module.

During bean initialization, the condition check will lead to class verification,
 if net.sf.ehcache.CacheManager is found, it will use a Java native method to search for the net.sf.ehcache.CacheManager class in the ClassLoader where the class belongs. Therefore, the base module must include this dependency; otherwise, it will result in ClassNotFound errors.
if net.sf.ehcache.CacheManager is found, it will use a Java native method to search for the net.sf.ehcache.CacheManager class in the ClassLoader where the class belongs. Therefore, the base module must include this dependency; otherwise, it will result in ClassNotFound errors.

- Modules should exclude the included Ehcache (set scope to provided or utilize automatic slimming capabilities).
When a module uses its own imported Ehcache, theoretically, it should avoid sharing static variables in the base CacheManager class, thus preventing potential errors. However, in our actual testing, during the module installation process, when initializing the EhCacheCacheManager, we encountered an issue where, during the creation of a new object, it required obtaining the CacheManager belonging to the class of the object, which in turn should be the base CacheManager. Importantly, we cannot include the CacheManager dependency in the module’s compilation, as it would lead to conflicts caused by a single class being imported by multiple different ClassLoaders.
When a module uses its own imported Ehcache, theoretically, it should avoid sharing static variables in the base CacheManager class, thus preventing potential errors. However, in our actual testing, during the module installation process, when initializing the EhCacheCacheManager, we encountered an issue where,

 during the creation of a new object, it required obtaining the CacheManager belonging to the class of the object, which in turn should be the base CacheManager. Importantly, we cannot include the CacheManager dependency in the module’s compilation, as it would lead to conflicts caused by a single class being imported by multiple different ClassLoaders.
during the creation of a new object, it required obtaining the CacheManager belonging to the class of the object, which in turn should be the base CacheManager. Importantly, we cannot include the CacheManager dependency in the module’s compilation, as it would lead to conflicts caused by a single class being imported by multiple different ClassLoaders.

Therefore, all loading should be delegated to the base module.
Best Practice Approach
- Delegate module Ehcache slimming to the base.
- If multiple modules have the same cacheName, modify cacheName to be different.
- If you don’t want to change the code to modify cache name, you can dynamically replace cacheName through packaging plugins.
<plugin>
<groupId>com.google.code.maven-replacer-plugin</groupId>
<artifactId>replacer</artifactId>
<version>1.5.3</version>
<executions>
<!-- Perform replacement before packaging -->
<execution>
<phase>prepare-package</phase>
<goals>
<goal>replace</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- Automatically recognize the project's target folder -->
<basedir>${build.directory}</basedir>
<!-- Directory rules for replacement files -->
<includes>
<include>classes/j2cache/*.properties</include>
</includes>
<replacements>
<replacement>
<token>ehcache.ehcache.name=f6-cache</token>
<value>ehcache.ehcache.name=f6-${parent.artifactId}-cache</value>
</replacement>
</replacements>
</configuration>
</plugin>
- Set the shared property of the FactoryBean to false.
@Bean
public EhCacheManagerFactoryBean ehCacheManagerFactoryBean() {
EhCacheManagerFactoryBean factoryBean = new EhCacheManagerFactoryBean();
// Set the factoryBean's shared property to false
factoryBean.setShared(true);
// factoryBean.setShared(false);
factoryBean.setCacheManagerName("biz1EhcacheCacheManager");
factoryBean.setConfigLocation(new ClassPathResource("ehcache.xml"));
return factoryBean;
}
Otherwise, it will enter this logic, initializing the static variable instance of CacheManager. If this variable has a value, and if shared is true in the module, it will reuse the CacheManager’s instance, leading to errors.


Example of Best Practices
For an example project, pleaserefer to here
5.3.6 - 6.5.3.5 Logback's adaptation for multi-module environments
Why Adaptation is Needed
The native logback framework only provides a default logging context, making it impossible to isolate log configurations between different modules. Consequently, in scenarios involving deploying multiple modules together, modules can only utilize the logging configuration of the base application, causing inconvenience when logging from individual modules.
Multi-Module Adaptation Solution
Logback supports native extension ch.qos.logback.classic.selector.ContextSelector, which allows for a custom context selector. Ark provides a default implementation of ContextSelector to isolate LoggerContext for multiple modules (refer to com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector). Each module uses its independent LoggerContext, ensuring log configuration isolation.
During startup, the log configuration and context initialization are handled by Spring’s log system LogbackLoggingSystem.
Specify the context selector as com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector and add the JVM startup parameter:
-Dlogback.ContextSelector=com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector
When using SLF4J as the logging facade with logback as the logging implementation framework, during the base application startup, when the SLF4J static binding is first performed, the specific ContextSelector is initialized. If no custom context selector is specified, the DefaultContextSelector will be used. However, when we specify a context selector, the ArkLogbackContextSelector will be initialized as the context selector.
ch.qos.logback.classic.util.ContextSelectorStaticBinder.init
public void init(LoggerContext defaultLoggerContext, Object key) {
...
String contextSelectorStr = OptionHelper.getSystemProperty(ClassicConstants.LOGBACK_CONTEXT_SELECTOR);
if (contextSelectorStr == null) {
contextSelector = new DefaultContextSelector(defaultLoggerContext);
} else if (contextSelectorStr.equals("JNDI")) {
// if jndi is specified, let's use the appropriate class
contextSelector = new ContextJNDISelector(defaultLoggerContext);
} else {
contextSelector = dynamicalContextSelector(defaultLoggerContext, contextSelectorStr);
}
}
static ContextSelector dynamicalContextSelector(LoggerContext defaultLoggerContext, String contextSelectorStr) {
Class<?> contextSelectorClass = Loader.loadClass(contextSelectorStr);
Constructor cons = contextSelectorClass.getConstructor(new Class[] { LoggerContext.class });
return (ContextSelector) cons.newInstance(defaultLoggerContext);
}
In the ArkLogbackContextSelector, we utilize ClassLoader to differentiate between different modules and cache the LoggerContext of each module based on its ClassLoader
When obtaining the LoggerContext based on the ClassLoader, during the startup of the Spring environment, the logging context is initialized via the Spring logging system. This is achieved by calling org.springframework.boot.logging.logback.LogbackLoggingSystem.getLoggerContext, which returns the LoggerContext specific to each module using the custom context selector implemented by Ark, com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector.getLoggerContext().
public LoggerContext getLoggerContext() {
ClassLoader classLoader = this.findClassLoader();
if (classLoader == null) {
return defaultLoggerContext;
}
return getContext(classLoader);
}
When obtaining the classloader, first, the thread’s context classloader is retrieved. If it is identified as the classloader of the module, it is returned directly. If the TCCL (thread context classloader) is not the classloader of the module, the call stack of the Class objects is traversed through the ClassContext. When encountering the classloader of the module in the call stack, it is returned directly. This approach is taken to accommodate scenarios where the TCCL is not guaranteed to be the classloader of the module. For example, when logging is performed in module code, and the current class is loaded by the module’s classloader itself, traversing the ClassContext allows us to eventually obtain the classloader of the module, ensuring the use of the module-specific LoggerContext.
private ClassLoader findClassLoader() {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
if (classLoader != null && CONTAINER_CLASS_LOADER.equals(classLoader.getClass().getName())) {
return null;
}
if (classLoader != null && BIZ_CLASS_LOADER.equals(classLoader.getClass().getName())) {
return classLoader;
}
Class<?>[] context = new SecurityManager() {
@Override
public Class<?>[] getClassContext() {
return super.getClassContext();
}
}.getClassContext();
if (context == null || context.length == 0) {
return null;
}
for (Class<?> cls : context) {
if (cls.getClassLoader() != null
&& BIZ_CLASS_LOADER.equals(cls.getClassLoader().getClass().getName())) {
return cls.getClassLoader();
}
}
return null;
}
Once the appropriate ClassLoader is obtained, different LoggerContext instances are selected. All module contexts are cached in com.alipay.sofa.ark.common.adapter.ArkLogbackContextSelector.CLASS_LOADER_LOGGER_CONTEXT with the ClassLoader as the key.
private LoggerContext getContext(ClassLoader cls) {
LoggerContext loggerContext = CLASS_LOADER_LOGGER_CONTEXT.get(cls);
if (null == loggerContext) {
synchronized (ArkLogbackContextSelector.class) {
loggerContext = CLASS_LOADER_LOGGER_CONTEXT.get(cls);
if (null == loggerContext) {
loggerContext = new LoggerContext();
loggerContext.setName(Integer.toHexString(System.identityHashCode(cls)));
CLASS_LOADER_LOGGER_CONTEXT.put(cls, loggerContext);
}
}
}
return loggerContext;
}
Sample Usage of Multi-Module Logback
5.3.7 - 6.5.3.6 log4j2 Multi-Module Adaptation
Why Adaptation is Needed
In its native state, log4j2 does not provide individual log directories for modules in a multi-module environment. Instead, it logs uniformly to the base directory, which makes it challenging to isolate logs and corresponding monitoring for each module. The purpose of this adaptation is to enable each module to have its own independent log directory.
Initialization of log4j2 in Regular Applications
Before Spring starts, log4j2 initializes various logContexts and configurations using default values. During the Spring startup process, it listens for Spring events to finalize initialization. This process involves invoking the Log4j2LoggingSystem.initialize method via org.springframework.boot.context.logging.LoggingApplicationListener.

The method determines whether it has already been initialized based on the loggerContext.
Here, a problem arises in a multi-module environment.
The
getLoggerContextmethod retrieves theLoggerContextbased on the classLoader oforg.apache.logging.log4j.LogManager. Relying on the classLoader of a specific class to extract theLoggerContextcan be unstable in a multi-module setup. This instability arises because some classes in modules can be configured to delegate loading to the base, so when a module starts, it might obtain theLoggerContextfrom the base. Consequently, ifisAlreadyInitializedreturns true, the log4j2 logging for the module cannot be further configured based on user configuration files.
If it hasn’t been initialized yet, it enters super.initialize, which involves two tasks:
- Retrieving the log configuration file.
- Parsing the variable values in the log configuration file. Both of these tasks may encounter issues in a multi-module setup. Let’s first examine how these two steps are completed in a regular application.
Retrieving the Log Configuration File

You can see that the location corresponding to the log configuration file’s URL is obtained through ResourceUtils.getURL. Here, the URL is obtained by retrieving the current thread’s context ClassLoader, which works fine in a multi-module environment (since each module’s startup thread context is already its own ClassLoader).

Parsing Log Configuration Values
The configuration file contains various variables, such as these:

These variables are parsed in the specific implementation of org.apache.logging.log4j.core.lookup.AbstractLookup, including:
| Variable Syntax | Implementation Class | |
|---|---|---|
| ${bundle:application:logging.file.path} | org.apache.logging.log4j.core.lookup.ResourceBundleLookup | Locates application.properties based on the ClassLoader of ResourceBundleLookup and reads the values inside. |
| ${ctx:logging.file.path} | org.apache.logging.log4j.core.lookup.ContextMapLookup | Retrieves values stored in the LoggerContext ThreadContext. It’s necessary to set the values from application.properties into the ThreadContext. |
Based on the above analysis, configuring via bundle method might not be feasible in a multi-module setup because ResourceBundleLookup might only exist in the base module, leading to always obtaining application.properties from the base module. Consequently, the logging configuration path of the modules would be the same as that of the base module, causing all module logs to be logged into the base module. Therefore, it needs to be modified to use ContextMapLookup.
Expected Logging in a Multi-Module Consolidation Scenario
Both the base module and individual modules should be able to use independent logging configurations and values, completely isolated from each other. However, due to the potential issues identified in the analysis above, which could prevent module initialization, additional adaptation of log4j2 is required.
Multi-Module Adaptation Points
Ensure
getLoggerContext()can retrieve the LoggerContext of the module itself.
It’s necessary to adjust to use ContextMapLookup so that module logs can retrieve the module application name and be logged into the module directory.
a. Set the values of application.properties to ThreadContext when the module starts. b. During logging configuration, only use the ctx:xxx:xxx configuration format.
Module Refactoring Approach
5.3.8 - 6.5.3.7 Module Use Bes
koupleless-adapter-bes
koupleless-adapter-bes is used to adapt to the BaoLande (BES) container, the warehouse address is koupleless-adapter-bes (thanks to the community student Chen Jian for his contribution).
The project is currently only verified in BES 9.5.5.004 version, and other versions need to be verified by themselves, and necessary adjustments need to be made according to the same logic.
If multiple BIZ modules do not need to use the same port to publish services, only need to pay attention to the precautions mentioned in the installation dependency section below, and do not need to introduce the dependencies related to this project.
Quick Start
1. Install Dependencies
First, make sure that BES-related dependencies have been imported into the maven repository. (There is a key point here. Due to the conflicting package structure of BES’s dependency package with the recognition mechanism of the koupleless 2.2.9 project, users need to add the prefix sofa-ark- to the BES’s dependency package by themselves, and the specific recognition mechanism can refer to koupleless’ com.alipay.sofa.ark.container.model. BizModel class)
The reference import script is as follows:
mv XXX/BES-EMBED/bes-lite-spring-boot-2.x-starter-9.5.5.004.jar XXX/BES-EMBED/sofa-ark-bes-lite-spring-boot-2.x-starter-9.5.5.004.jar
mvn install:install-file -Dfile=XXX/BES-EMBED/sofa-ark-bes-lite-spring-boot-2.x-starter-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=sofa-ark-bes-lite-spring-boot-2.x-starter -Dversion=9.5.5.004 -Dpackaging=jar
mvn install:install-file -Dfile=XXX/BES-EMBED/bes-gmssl-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-gmssl -Dversion=9.5.5.004 -Dpackaging=jar
mvn install:install-file -Dfile=XXX/BES-EMBED/bes-jdbcra-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-jdbcra -Dversion=9.5.5.004 -Dpackaging=jar
mvn install:install-file -Dfile=XXX/BES-EMBED/bes-websocket-9.5.5.004.jar -DgroupId=com.bes.besstarter -DartifactId=bes-websocket -Dversion=9.5.5.004 -Dpackaging=jar
2. Compile and Install the Project Plugin
Enter the bes9-web-adapter directory of the project and execute the mvn install command.
The project will install the “bes-web-ark-plugin” and “bes-sofa-ark-springboot-starter” two modules.
3. Use the Project Components
First, according to the koupleless documentation, upgrade the project to Koupleless Base
Then, replace the coordinates mentioned in the dependencies
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>web-ark-plugin</artifactId>
<version>${sofa.ark.version}</version>
</dependency>
with the coordinates of this project
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>bes-web-ark-plugin</artifactId>
<version>2.2.9</version>
</dependency>
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>bes-sofa-ark-springboot-starter</artifactId>
<version>2.2.9</version>
</dependency>
Introduce BES-related dependencies (also need to exclude the dependency of tomcat). The reference dependence is as follows:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>sofa-ark-bes-lite-spring-boot-starter</artifactId>
<version>9.5.5.004</version>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>bes-gmssl</artifactId>
<version>9.5.5.004</version>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>bes-jdbcra</artifactId>
<version>9.5.5.004</version>
</dependency>
<dependency>
<groupId>com.bes.besstarter</groupId>
<artifactId>bes-websocket</artifactId>
<version>9.5.5.004</version>
</dependency>
4. Finished
After completing the above steps, you can start the project in Koupleless using BES.
5.3.9 - 6.5.3.8 Module Using Dubbo
Module Interceptor (Filter)
A module can use interceptors defined within itself or those defined on the base.
⚠️Note: Avoid naming module interceptors the same as those on the base. If the names are identical, the interceptors from the base will be used.
5.3.10 - 6.5.3.10 Introduction to the Principle of Class Delegation Loading between Foundation and Modules
Class Delegation Loading between Multiple Modules
The SOFAArk framework is based on a multi-ClassLoader universal class isolation solution, providing class isolation and application merge deployment capabilities. This document does not intend to introduce the principles and mechanismsof SOFAArk class isolation. Instead, it mainly introduces the current best practices of multi-ClassLoader.
The ClassLoader model between the foundation and modules deployed on the JVM at present is as shown in the figure below:
Current Class Delegation Loading Mechanism
The classes searched by a module during startup and runtime currently come from two sources: the module itself and the foundation. The ideal priority order of these two sources is to search from the module first, and if not found, then from the foundation. However, there are some exceptions currently:
- A whitelist is defined, and dependencies within the whitelist are forced to use dependencies in the foundation.
- The module can scan all classes in the foundation:
- Advantage: The module can introduce fewer dependencies.
- Disadvantage: The module will scan classes that do not exist in the module code, such as some AutoConfigurations. During initialization, errors may occur due to the inability to scan corresponding resources.
- The module cannot scan any resources in the foundation:
- Advantage: It will not initialize the same beans as the foundation repeatedly.
- Disadvantage: If the module needs resources from the foundation to start, errors will occur due to the inability to find resources unless the module is explicitly introduced (Maven dependency scope is not set to provided).
- When the module calls the foundation, some internal processes pass the class names from the module to the foundation. If the foundation directly searches for the classes passed by the module from the foundation ClassLoader, it will not find them. This is because delegation only allows the module to delegate to the foundation, and classes initiated from the foundation will not search the module again.
Points to Note When Using
When a module needs to upgrade the dependencies delegated to the foundation, the foundation needs to be upgraded first, and then the module can be upgraded.
Best Practices for Class Delegation
The principle of class delegation loading is that middleware-related dependencies need to be loaded and executed in the same ClassLoader. There are two best practices to achieve this:
Mandatory Delegation Loading
Since middleware-related dependencies generally need to be loaded and executed in the same ClassLoader, we will specify a whitelist of middleware dependency, forcing these dependencies to be delegated to the foundation for loading.
Usage
Add the configuration sofa.ark.plugin.export.class.enable=true to application.properties.
Advantages
Module developers do not need to be aware of which dependencies belong to the middleware that needs to be loaded by the same ClassLoader.
Disadvantages
The list of dependencies to be forcibly loaded in the whitelist needs to be maintained. If the list is missing, the foundation needs to be updated. Important upgrades require pushing all foundation upgrades.
Custom Delegation Loading
In the module’s pom, set the scope of the dependency to provided to actively specify which dependencies to delegate to the foundation for loading. By slimming down the module, duplicate dependencies with the foundation are delegated to the foundation for loading, and middleware dependencies are pre-deployed in the foundation (optional, although the module may not use them temporarily, they can be introduced in advance in case they are needed by subsequent modules without the need to redeploy the foundation). Here:
- The foundation tries to precipitate common logic and dependencies, especially those related to middleware named
xxx-alipay-sofa-boot-starter. - Pre-deploy some common dependencies in the foundation (optional).
- If the dependencies in the module are already defined in the foundation, the dependencies in the module should be delegated to the foundation as much as possible. This will make the module lighter (providing tools for automatic module slimming). There are two ways for the module to delegate to the foundation:
- Set the scope of the dependency to provided, and check whether there are other dependencies set to compile through
mvn dependency:tree, and all places where dependencies are referenced need to be set to provided. - Set
excludeGroupIdsorexcludeArtifactIdsin thesofa-ark-maven-pluginbiz packaging plugin.
- Set the scope of the dependency to provided, and check whether there are other dependencies set to compile through
<plugin>
<groupId>com.alipay.sofa</groupId>
<artifactId>sofa-ark-maven-plugin</artifactId>
<configuration>
<excludeGroupIds>io.netty,org.apache.commons,......</excludeGroupIds>
<excludeArtifactIds>validation-api,fastjson,hessian,slf4j-api,junit,velocity,......</excludeArtifactIds>
<declaredMode>true</declaredMode>
</configuration>
</plugin>
Using Method 2.b To ensure that all declarations are set to provided scope, it is recommended to use Method 2.b, where you only need to specify once.
- Only dependencies declared by the module can be delegated to the foundation for loading.
During module startup, the Spring framework has some scanning logic. If these scans are not restricted, they will search for all resources of both the module and the foundation, causing some modules to attempt to initialize functions they clearly do not need, resulting in errors. Since SOFAArk 2.0.3, the declaredMode of modules has been added to limit only dependencies declared within the module can be delegated to the foundation for loading. Simply add <declaredMode>true</declaredMode> to the module’s packaging plugin configurations.
Advantages
- No need to maintain a forced loading list for plugins. When some dependencies that need to be loaded by the same ClassLoader are not set for uniform loading, you can fix them by modifying the module without redeploying the foundation (unless the foundation does require it).
Disadvantages
- Strong dependency on slimming down modules.
Comparison and Summary
| Dependency Missing Investigation Cost | Repair Cost | Module Refactoring Cost | Maintenance Cost | |
|---|---|---|---|---|
| Forced Loading | Moderate | Update plugin, deploy foundation, high | Low | High |
| Custom Delegation | Moderate | Update module dependencies, update foundation if dependencies are insufficient and deploy, moderate | High | Low |
| Custom Delegation + Foundation Preloaded Dependencies + Module Slimming | Moderate | Update module dependencies, set to provided, low | Low | Low |
Conclusion: Recommend Custom Delegation Loading Method
- Module custom delegation loading + module slimming.
- Module enabling declaredMode.
- Preload dependencies in the base.
declaredMode Activation Procedure
Activation Conditions
The purpose of declaredMode is to enable modules to be deployed to the foundation. Therefore, before activation, ensure that the module can start locally successfully.
If it is a SOFABoot application and involves module calls to foundation services, local startup can be skipped by adding these two parameters to the module’s application.properties (SpringBoot applications do not need to care):
# If it is SOFABoot, then:
# Configure health check to skip JVM service check
com.alipay.sofa.boot.skip-jvm-reference-health-check=true
# Ignore unresolved placeholders
com.alipay.sofa.ignore.unresolvable.placeholders=true
Activation Method
Add the following configuration to the module’s packaging plugin:
Side Effects After Activation
If the dependencies delegated to the foundation by the module include published services, then the foundation and the module will publish two copies simultaneously.
5.3.11 - 6.3.5.11 What happens if a module independently introduces part of the SpringBoot framework?
Since the logic of multi-module runtime is introduced and loaded in the base, such as some Spring Listeners. If the module starts using its own SpringBoot entirely, there may be some class conversion or assignment judgment failures, for example:
CreateSpringFactoriesInstances

name = ‘com.alipay.sofa.ark.springboot.listener.ArkApplicationStartListener’, ClassUtils.forName gets the class from the base ClassLoader.
However, the type is loaded when the module starts, which means it is loaded using the module’s BizClassLoader.
At this point, performing an isAssignable check here will cause an error.
com.alipay.sofa.koupleless.plugin.spring.ServerlessApplicationListener is not assignable to interface org.springframework.context.ApplicationListener
So the module framework part needs to be delegated to the base to load.
5.4 - 6.5.4 Module Split Tool
5.4.1 - 6.5.4.1 Semi-Automated Split Tool User Guide
Background
When extracting the Koupleless module from a large monolithic SpringBoot application, users face high learning and trial-and-error costs. Users need to analyze from the service entrance which classes to split into the module, then modify the module according to the Koupleless module coding method.
To reduce learning and trial-and-error costs, KouplelessIDE plugin provides semi-automated splitting capabilities: analyzing dependencies and automating modifications.
Quick Start
1. Install Plugin
Install the KouplelessIDE plugin from the IDEA plugin marketplace:
2. Configure IDEA
Ensure that IDEA -> Preferences -> Builder -> Compiler’s “User-local build process heap size” is at least 4096
3. Select Module
Step one: Open the SpringBoot application that needs splitting with IDEA, on the right panel open ServerlessSplit
Step two: Select the splitting method as needed, click “Confirm and Collapse”
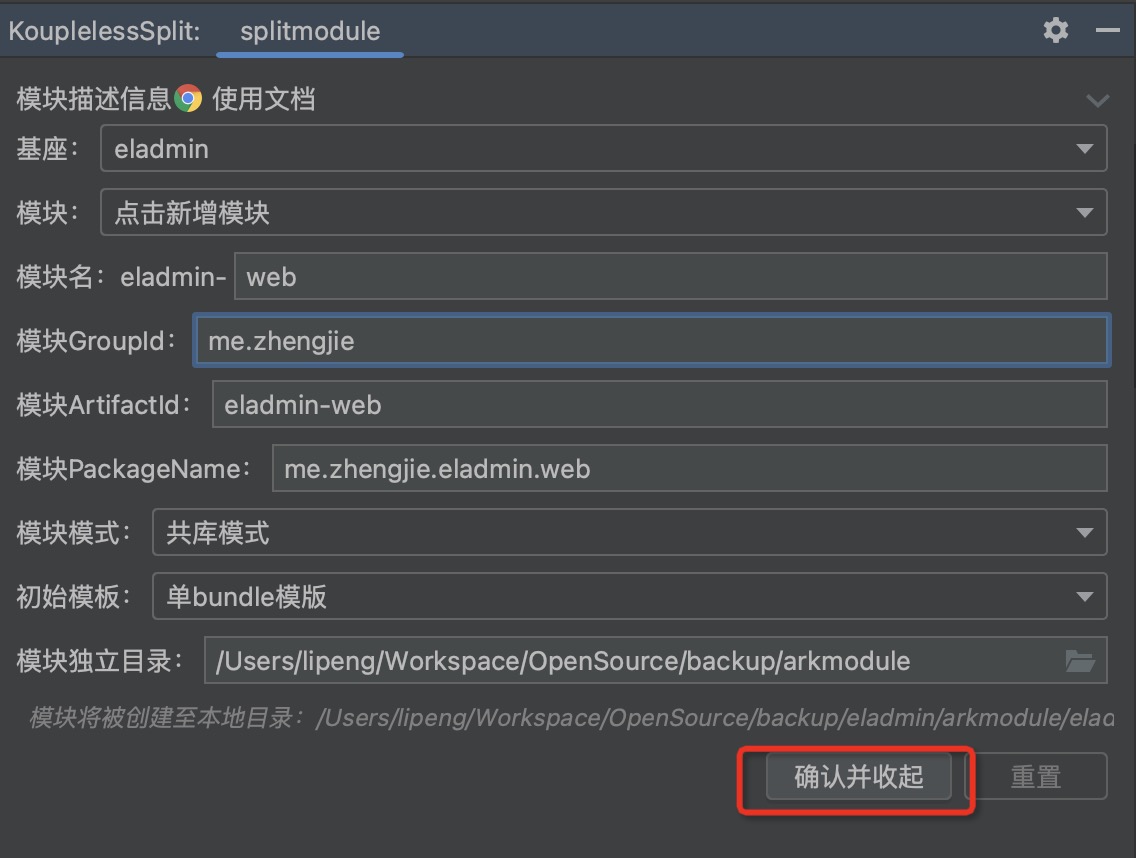
4. Dependency Analysis
During splitting, it is necessary to analyze the dependencies between classes and Beans. The plugin allows for the visualization of dependency relationships, and it is up to the business side to decide whether a class should be split into a module.
Step one: Click to activate
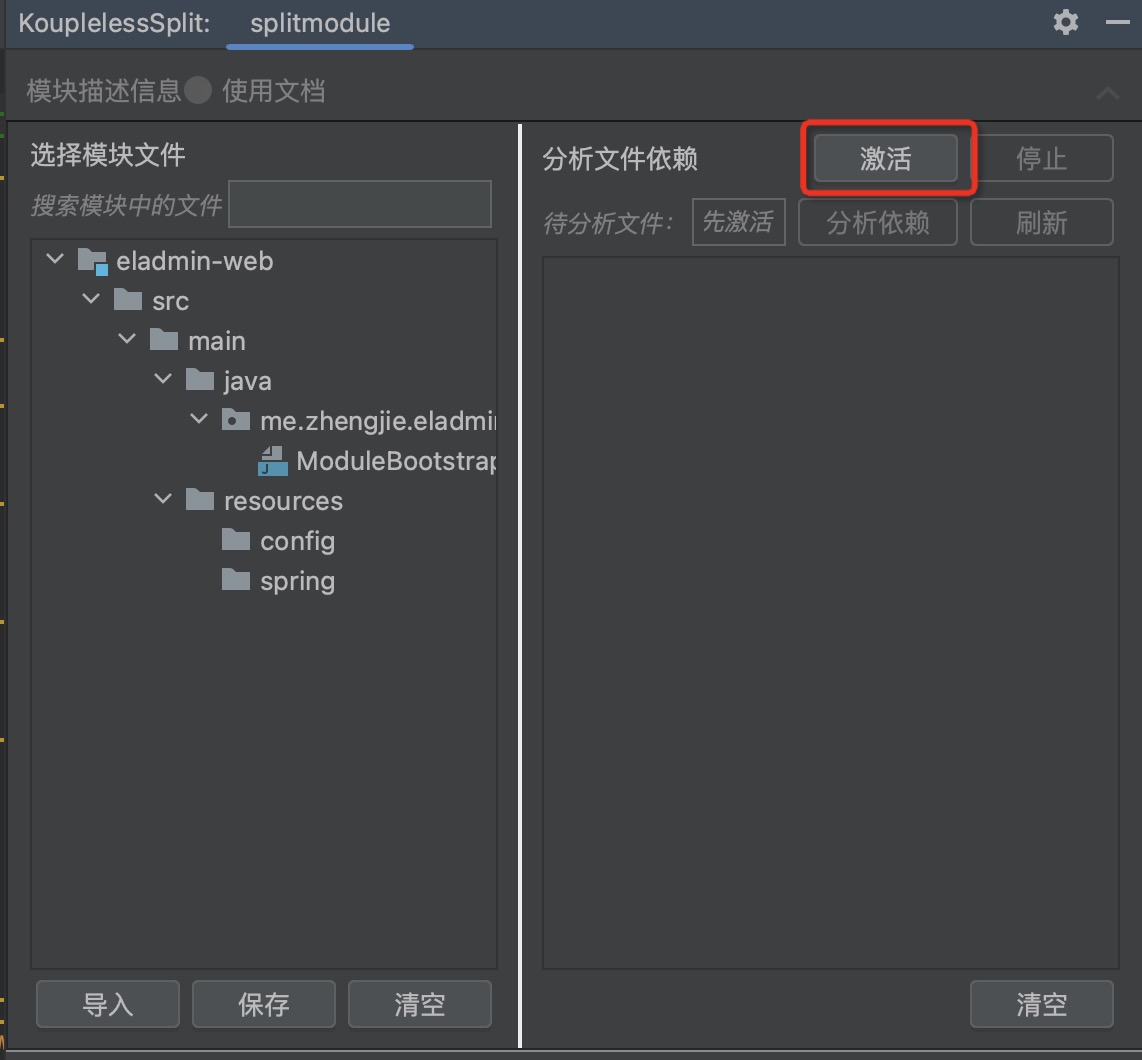
Step two: Drag the service entry to the module, supporting cross-level dragging
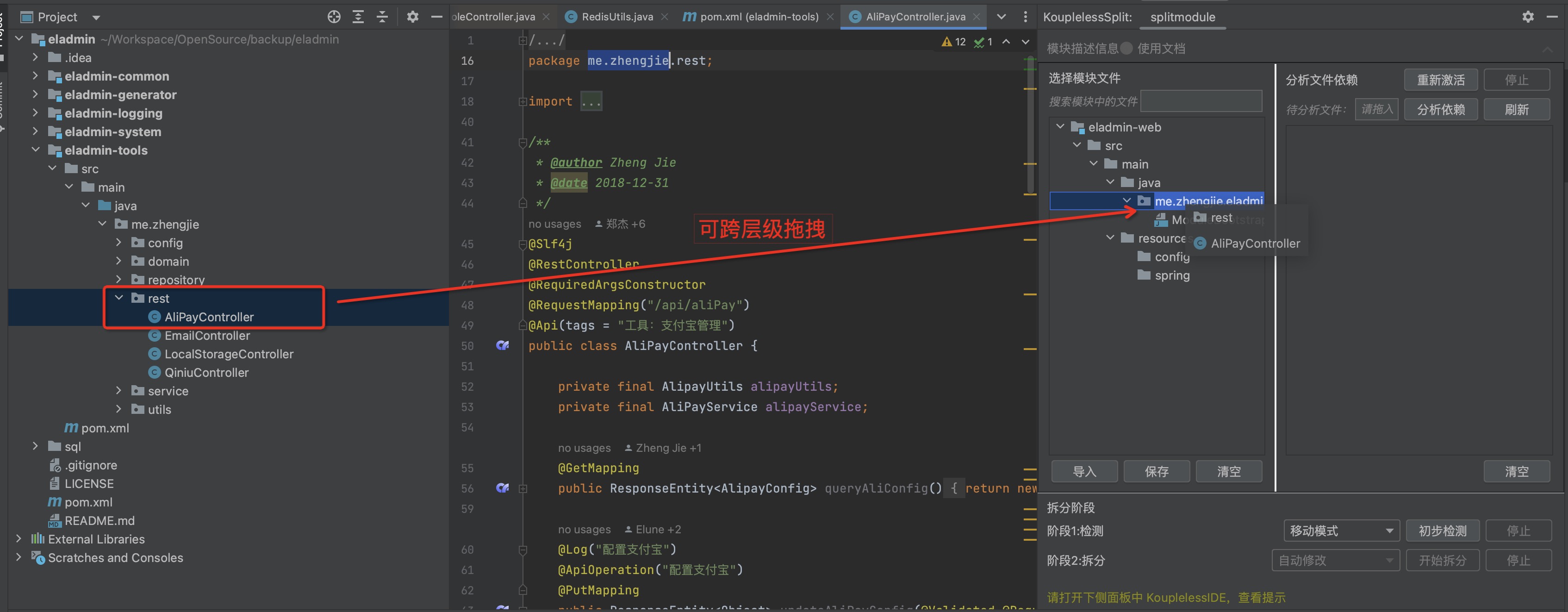
Dragging result:
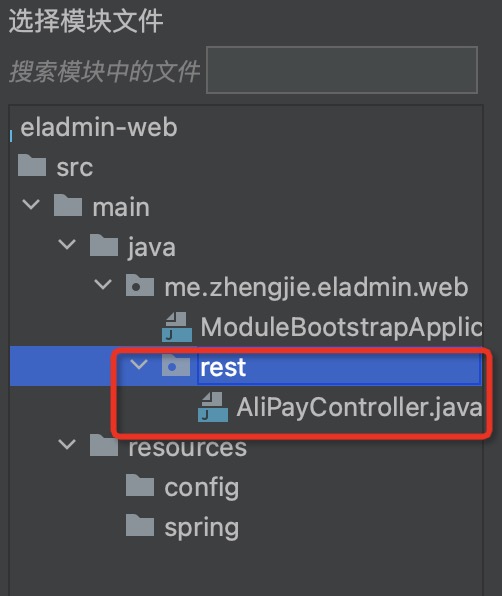
Step three: Drag the “Files for Analysis”, click to analyse dependencies, view Class/Bean dependencies as shown below:
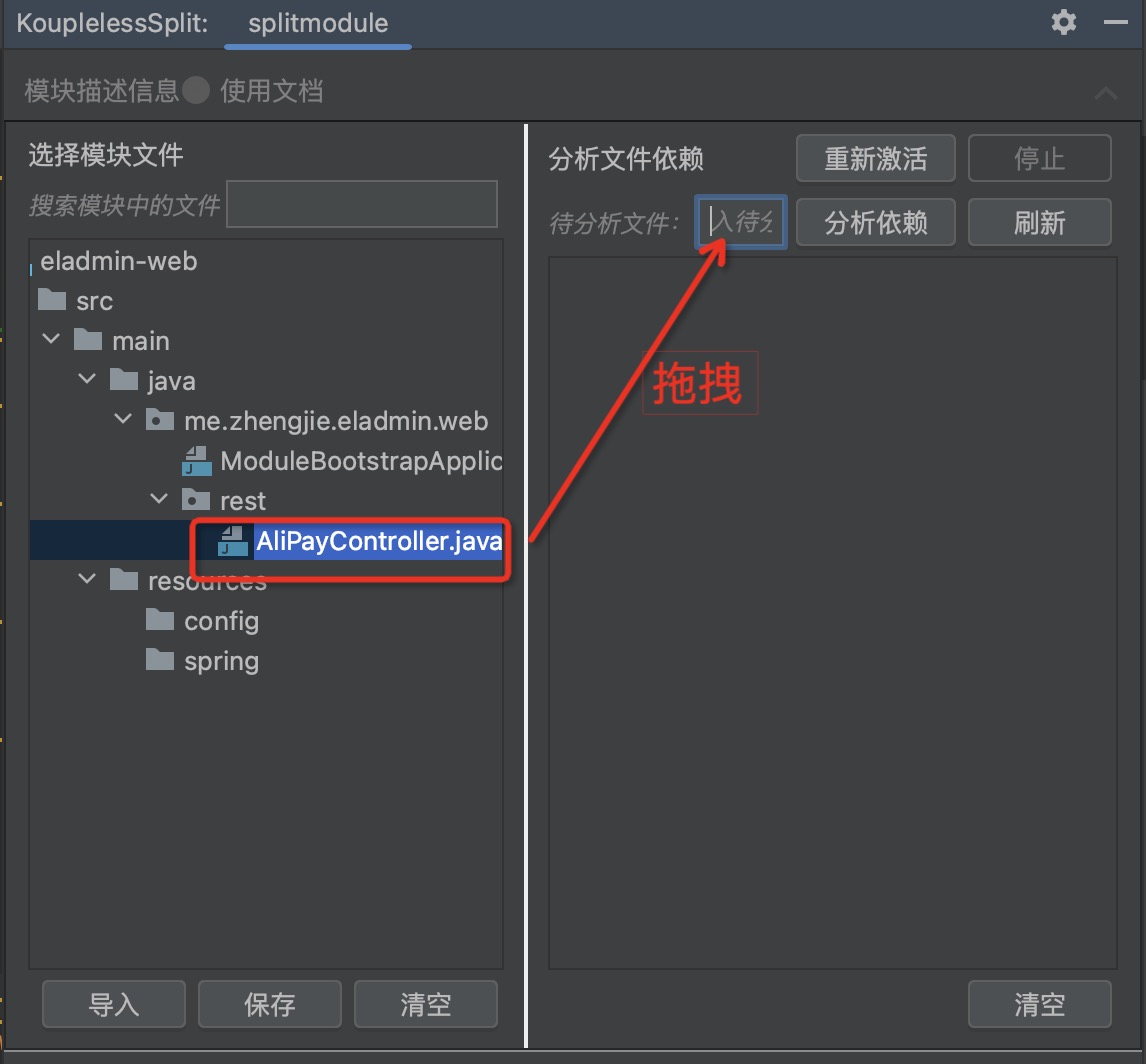
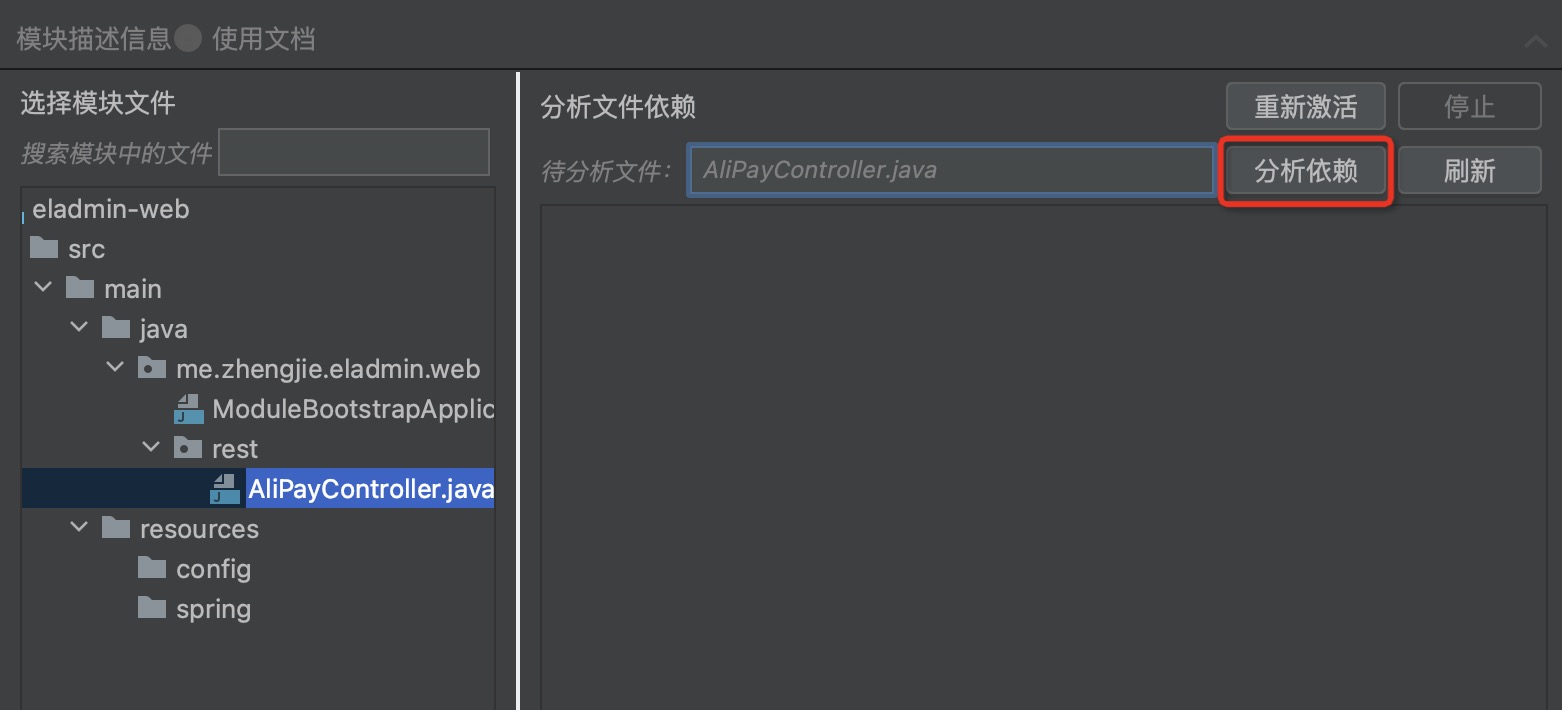
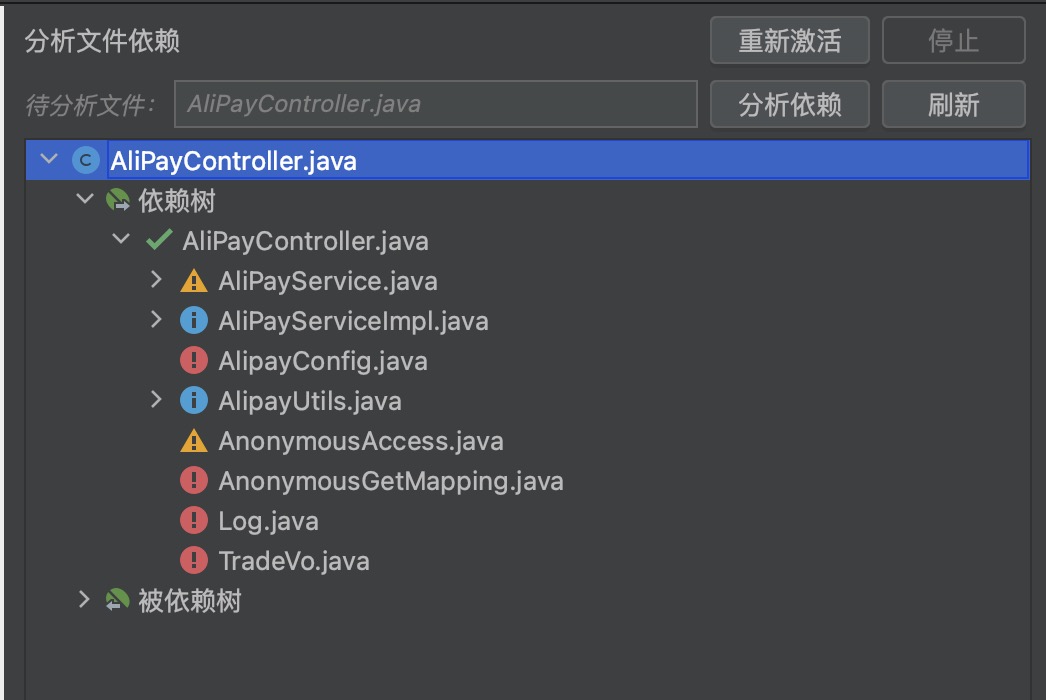
Where the icons represent:
| Icon | Meaning | Required Action |
|---|---|---|
| Already in module | No action required | |
 | Can be moved to module | Drag to module 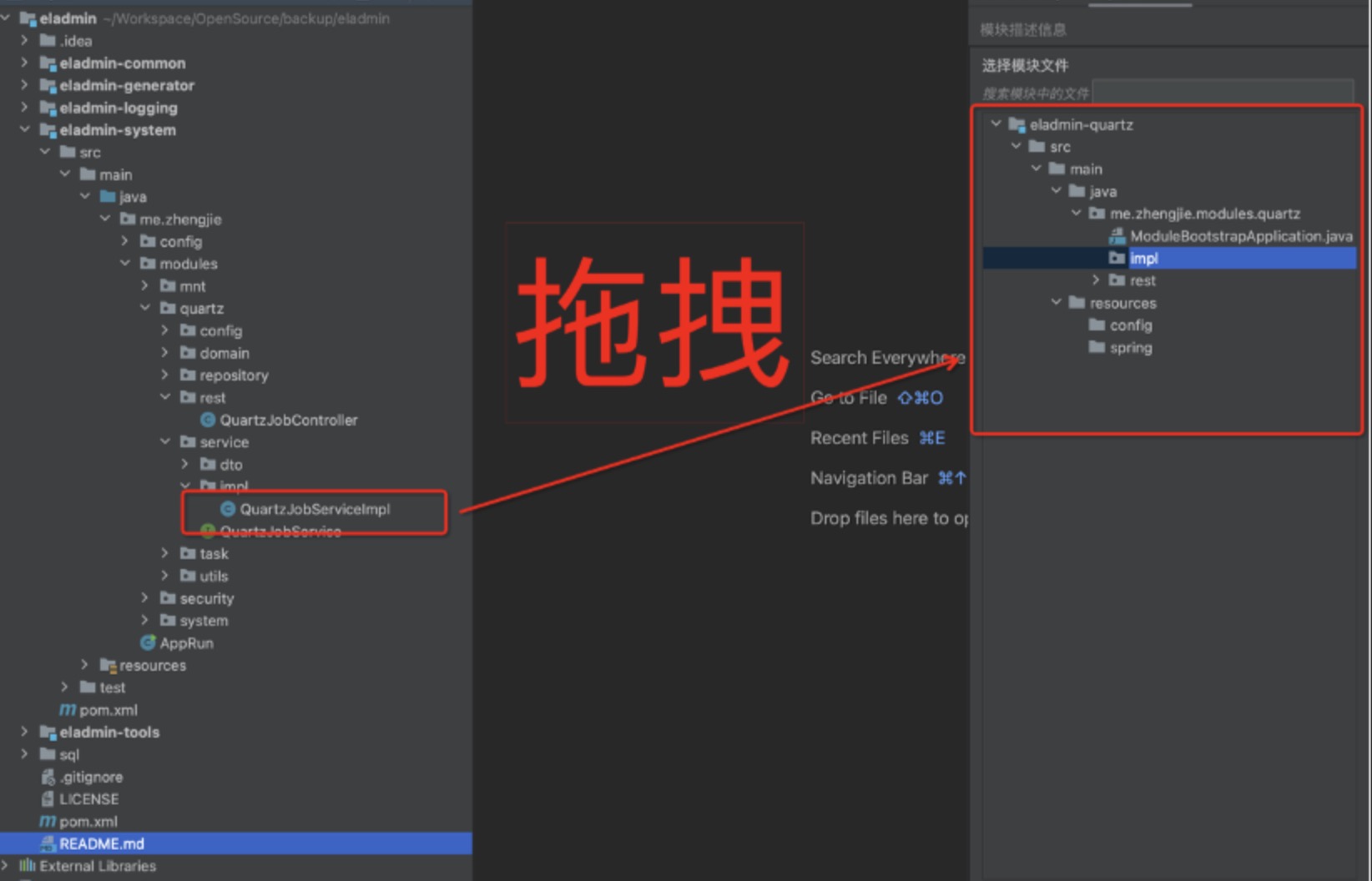 |
| Recommended to analyze dependency | Drag to analyze 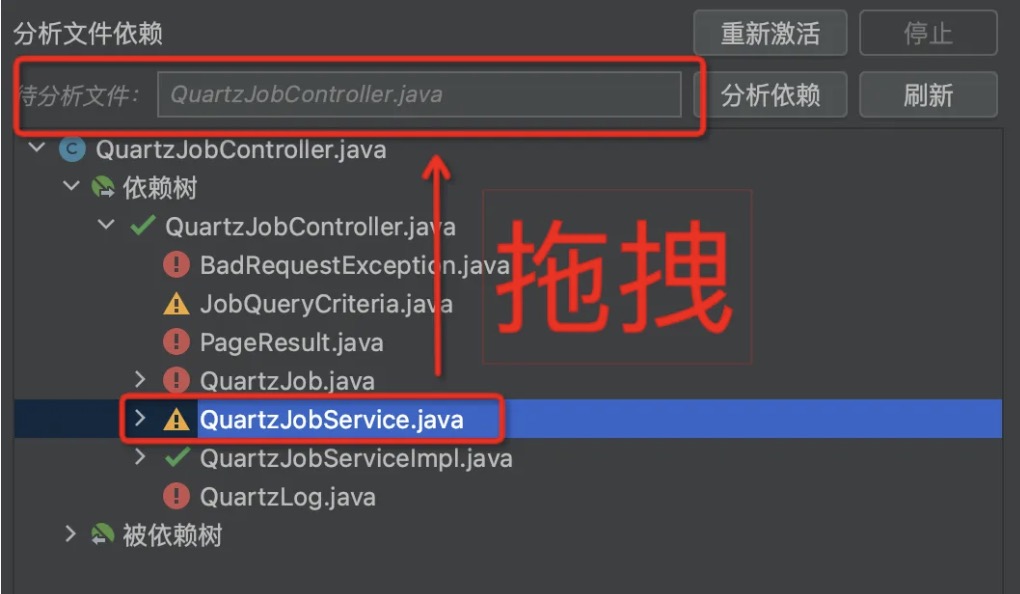 | |
| Should not be moved to module | Hover to view dependency details |
Step four: Follow the prompts, through dragging, stepwise analyze, import the necessary module files
5. Detection
Click on “Preliminary Detection”, which will prompt the user about possible issues with this split, and which middleware might require manual intervention.
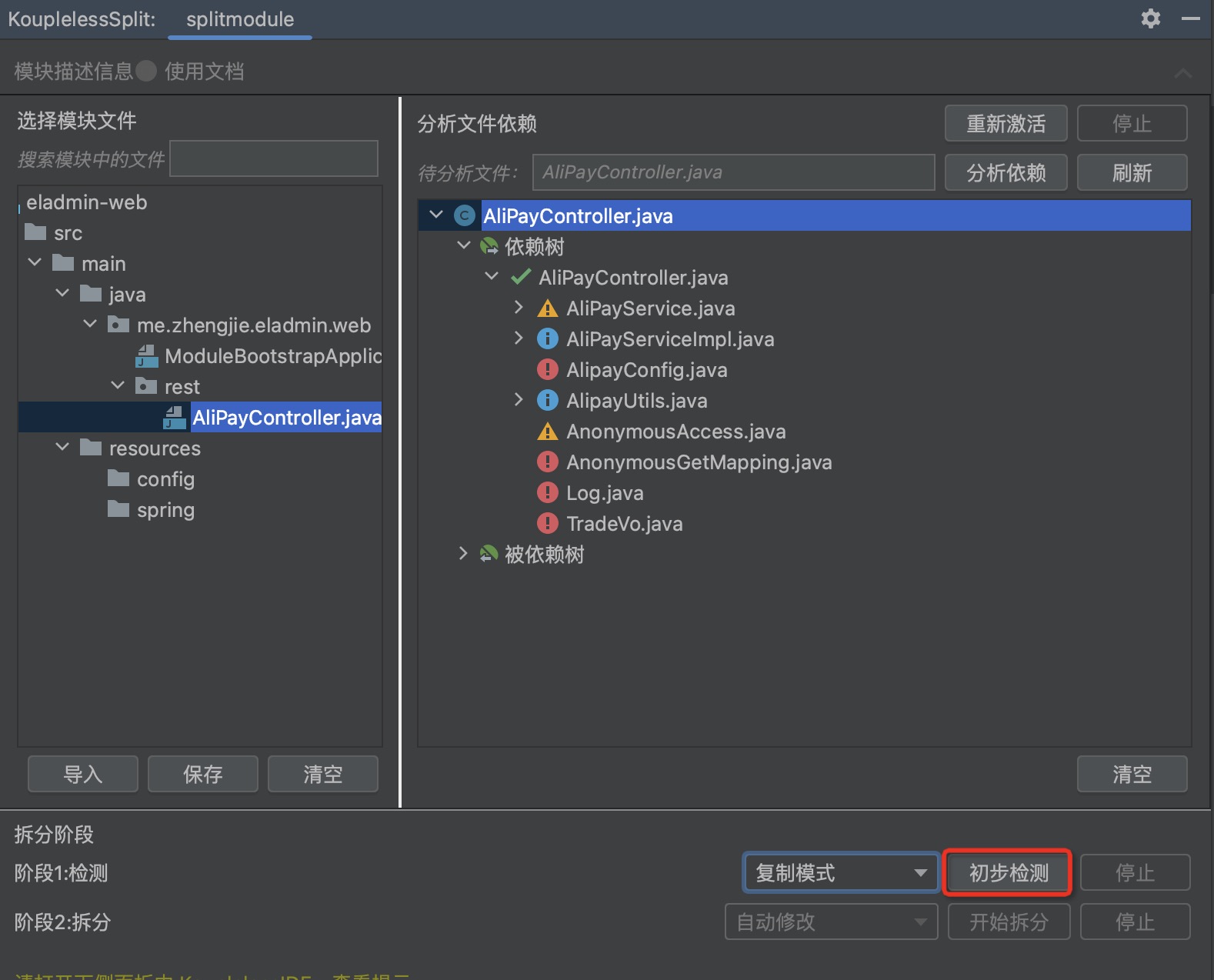
Open the lower sidebar in KouplelessIDE to view the prompts.
6. Splitting
Click to start the splitting.
Open the lower sidebar in KouplelessIDE to view the prompts.

5.4.2 - 6.5.4.2 Is it too difficult to collaborate on developing a monolithic application? Koupleless brings Split Plugin to help you streamline and improve the efficiency of collaborative development!
Background
Is the collaboration efficiency of your enterprise application low?
It takes ten minutes to compile and deploy the code even though only one line is changed;
When multiple developers work on a codebase, they frequently encounter resource contention and mutual coverage during debugging, resulting in mutual waiting for deployment…
As the project code gradually expands and the business develops, the problems of code coupling, release coupling, and resource coupling are increasingly serious, and the development efficiency keeps decreasing.
How to solve it? Try splitting a single Springboot application into multiple Springboot applications! After splitting, multiple Springboot applications can be developed in parallel without interfering with each other. In the Koupleless mode, the business can split the Springboot application into a base and multiple Koupleless modules (Koupleless modules are also Springboot applications).
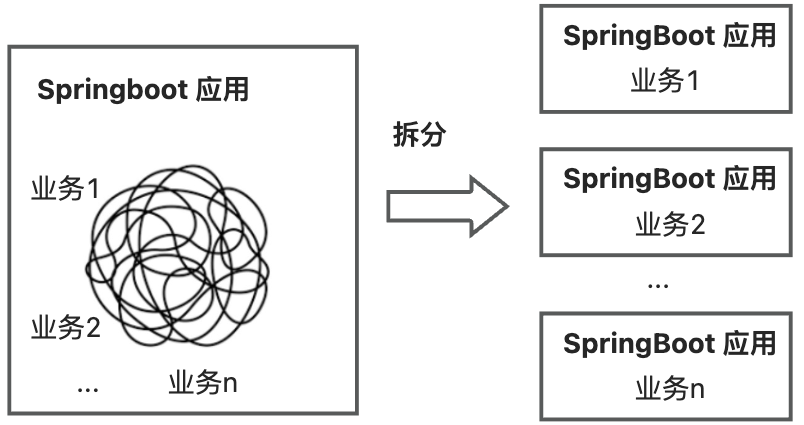
🙌 Scroll down to the “Koupleless Split Plugin Solution” section to watch the demonstration video of splitting a monolithic application!
Key Challenges
There are three key challenges in splitting multiple Springboot applications from a single one:
First, before splitting the sub-application, the complex monolithic application has high code coupling, complex dependency relationships, and a complex project structure, making it difficult to analyze the coupling between files and even more difficult to split out sub-applications, hence the need to solve the problem of analyzing file dependencies in the complex monolithic application before splitting.
Second, when splitting the sub-application, the operation of splitting is cumbersome, time-consuming, and requires users to analyze dependency relationships while splitting, thus imposing high demands on users, therefore there is a need to reduce the user interaction cost during the splitting.
Third, after splitting the sub-application, the monolithic application evolves into a multi-application coexistence, and its coding mode will change. The way Bean is called transitions from a single application call to a cross-application call, and special multi-application coding modes need to be adjusted according to the framework documentation. For example, in Koupleless, in order to reduce the data source connection of modules, modules will use the data source of the base in a certain way, resulting in a very high learning and adjustment cost, hence the need to solve the problem of the evolution of coding modes in multiple applications after splitting.
Koupleless Split Plugin Solution
In response to the above three key challenges, the Koupleless IntelliJ IDEA Plugin divides the solution into 3 parts: analysis, interaction, and automated splitting, providing dependency analysis, user-friendly interaction, and automated splitting capabilities, as shown in the following figure:
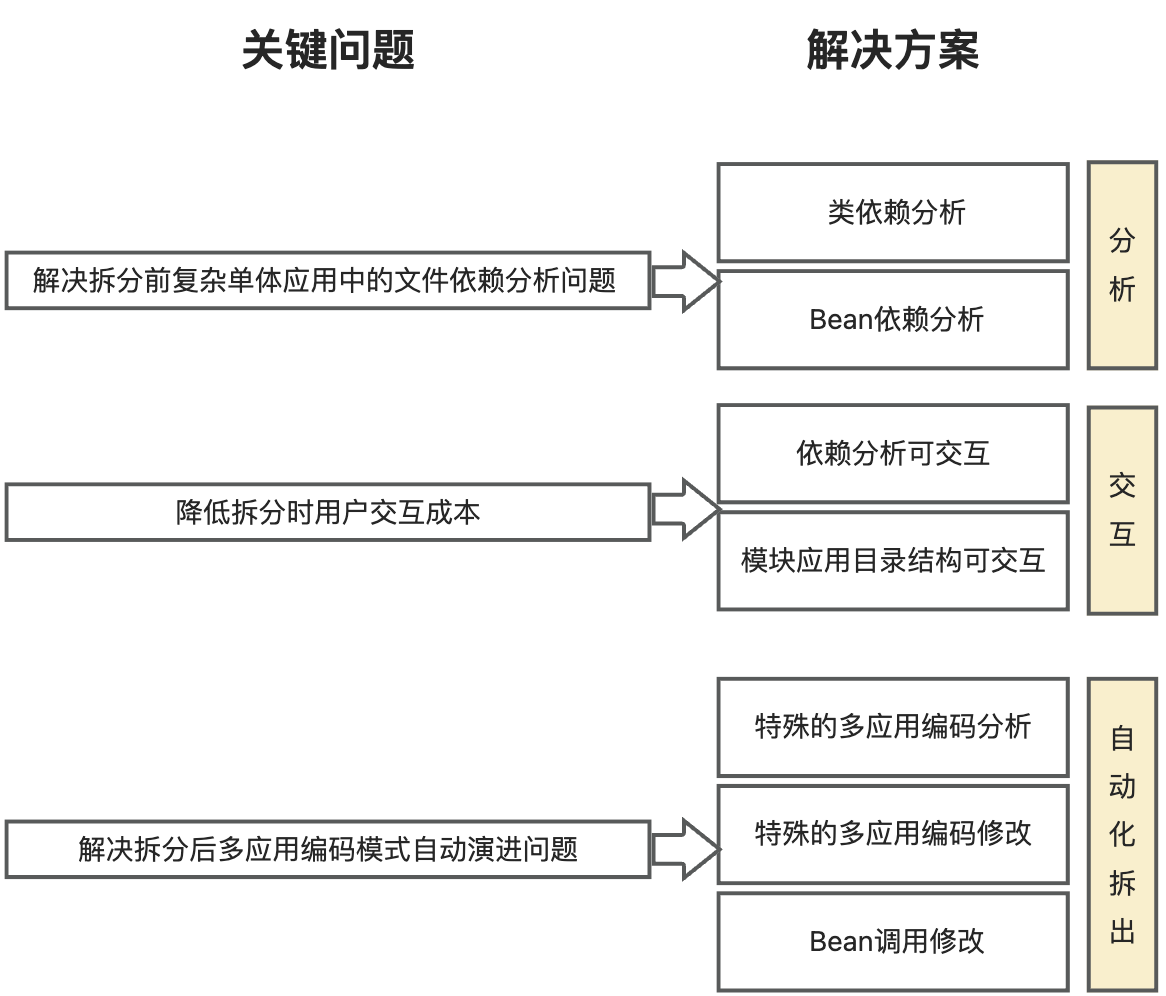
- In the analysis, analyze the dependency relationships in the project, including class dependencies and Bean dependencies, to solve the problem of analyzing file dependencies in the complex monolithic application before splitting;
- In the interaction, visualize the dependency relationships between class files to help users sort out the relationships. At the same time, visualize the module directory structure, allowing users to decide which module files to split by dragging and dropping, thus reducing the user interaction cost during splitting;
- In the automated splitting, the plugin will build the modules and modify the code according to the special multi-application coding, solving the problem of the evolution of coding modes in multiple applications after splitting.
🙌 Here is a demonstration video of the semi-automatic splitting with Koupleless, which will help you better understand how the plugin provides assistance in analysis, interaction, and automated splitting.
Example of Understanding the Advantages of Koupleless Solution
Suppose a business needs to separate the code related to the system into modules, while keeping the common capabilities in the base. Here we take the entry service of the system, QuartzJobController, as an example.
Step 1: Analyze Project File Dependencies
First, we will analyze which classes and beans QuartzJobController depends on.
Method 1: Using IntelliJ IDEA Ultimate, perform bean and class analysis on the controller to obtain the following bean dependency diagram and class dependency diagram.
 |  |
|---|
- Advantage: Comprehensive analysis with the help of IntelliJ IDEA Ultimate
- Disadvantage: Requires analysis of each class file, and the bean dependency diagram may not be very readable.
Method 2: Use mental analysis
When class A depends on classes B, C, D, … N, when separating them, it is necessary to analyze whether each class is being depended on by other classes and whether it can be separated into modules.
- Advantage: Intuitive
- Disadvantage: When class A has many dependencies, it requires recursive mental analysis.
Method 3: Use the Koupleless assistant tool for easy analysis! Select any class file you want to analyze, click “Analyze Dependencies,” and the plugin will help you analyze. It not only analyzes the classes and beans that the class file depends on, but also suggests which classes can be separated out and which cannot.
For example, when the selected module includes QuartzJobController, QuartzJobService, and QuartzJobServiceImpl, the dependency of QuartzJobController on classes and beans is as shown in the following diagram:
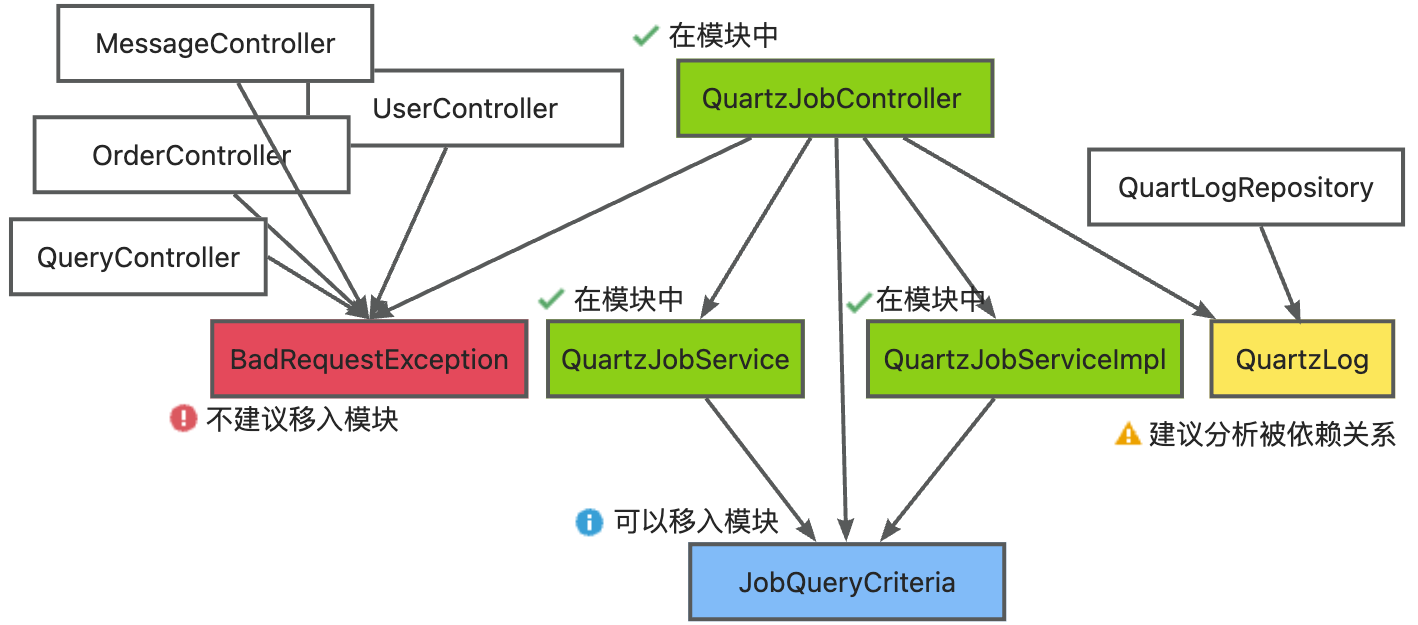
The dependent classes/beans of QuartzJobController are divided into four categories: already in the module, can be moved into the module, suggested to analyze the dependency relationship, and not recommended to be moved into the module.
- If it is in the module, it is marked as green “already in the module,” such as QuartzJobService and QuartzJobServiceImpl.
- If it is only depended on by module classes, then it is marked as blue “can be moved into the module,” such as JobQueryCriteria.
- If it is only depended on by one non-module class, then it is marked as yellow “suggested to analyze the dependency relationship,” such as QuartLog.
- If it is depended on by many non-module classes, then it is marked as red “not recommended to be moved into the module,” such as BadRequestException.
When using the plugin to analyze QuartzJobController and JobQueryCriteria, the dependency tree and the dependency by tree are as follows, corresponding to the analysis above:
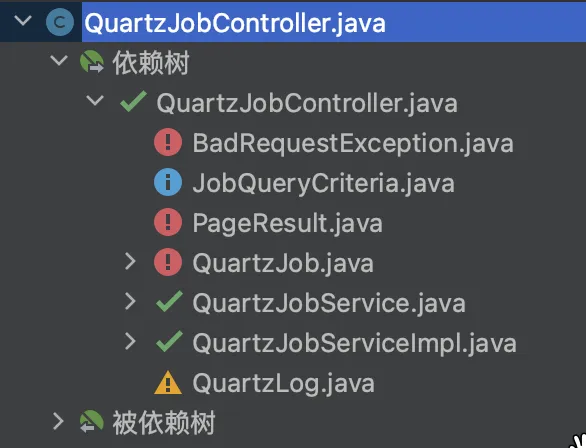 |  |
|---|
- Advantage: Intuitive, easy to use, and friendly prompts
- Disadvantage: The plugin only supports the analysis of common bean definitions and class references
Step 2: Separate into Modules & Modify Single Application Coding to Multi-Application Coding Mode
Separate the relevant class files into modules.
Method 1: Copy and paste each file, mentally analyze the bean calls between all module and bases, and modify the code according to the multi-application coding mode.
When separating, questions may arise: Where did I just separate to? Is this file in the module? Do I need to refactor these package names? Are the bean calls cross-application? Where is the documentation for multi-application coding?
- Advantage: Can handle multi-application coding modes that the plugin cannot handle
- Disadvantage: Users not only need to analyze cross-application bean dependencies, but also need to learn the multi-application coding mode, resulting in high manual costs.
Method 2: Use the Koupleless assistant tool for easy separation!
Drag the files you want to separate into the panel according to the module directory structure. Click “Separate,” and the plugin will help you analyze and modify according to the Koupleless multi-application coding mode.
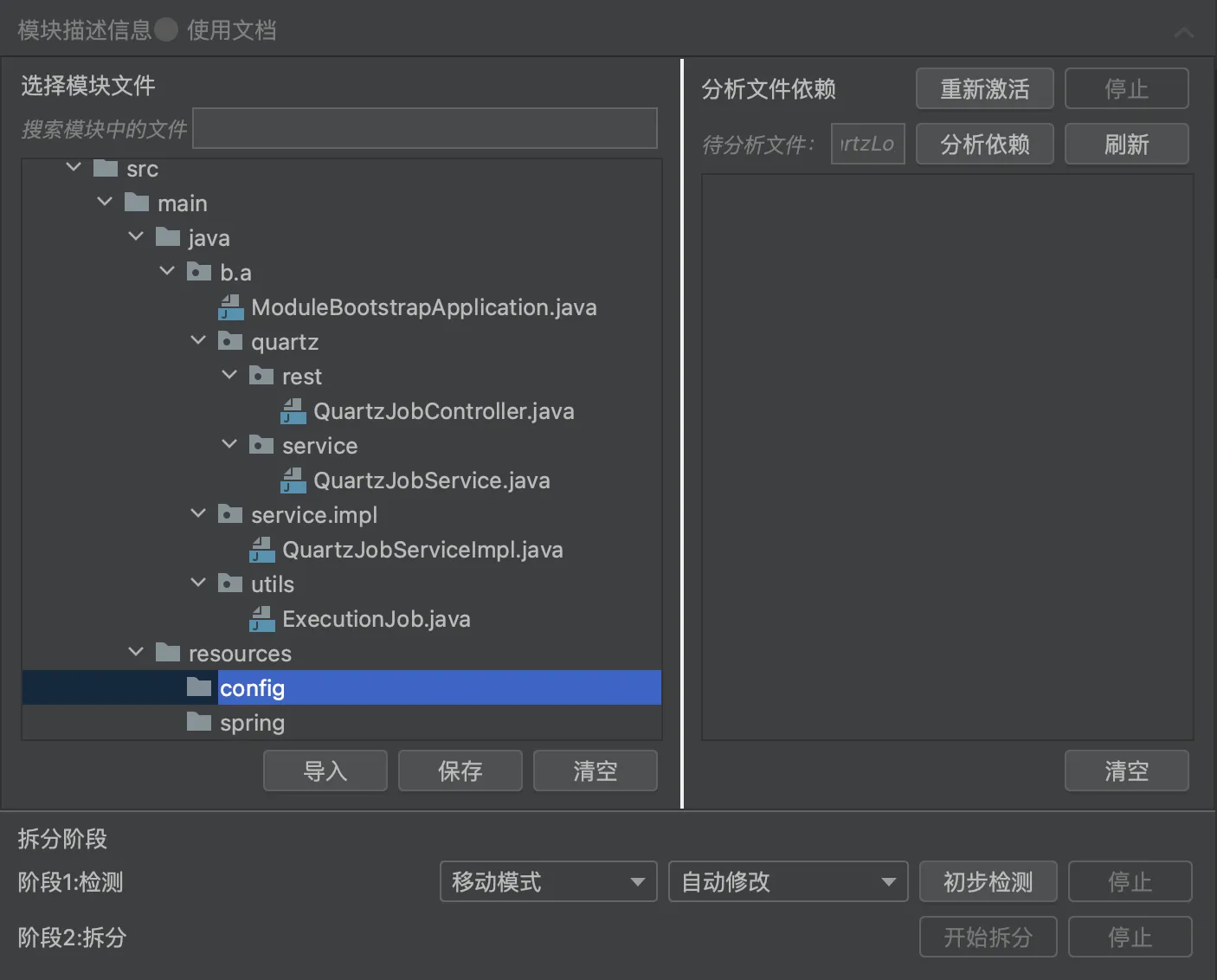
- Advantage: Intuitive, convenient interaction, and the plugin automatically modifies the way cross-application bean calls are made and some special multi-application coding modes
- Disadvantage: The plugin can only modify the code based on some multi-application coding modes, so users need to understand the capabilities of the plugin.
Technical Solution
The plugin divides the overall process into 3 stages: analysis stage, interaction stage, and automated separation stage, as shown in the following diagram:
- In the analysis stage, it analyzes the dependencies in the project, including class dependencies, bean dependencies, and special multi-application coding analysis, such as MyBatis configuration dependencies.
- In the interaction stage, it visualizes the dependencies between class files and the module directory structure.
- In the automated separation stage, the plugin first builds the module and integrates the configuration, then refactors the package names according to the user’s needs, modifies the way module base bean calls are made, and modifies the code according to special multi-application coding modes, such as automatically reusing the base data source.
Next, we will briefly introduce the main technologies used in the analysis stage, interaction stage, and automated separation stage.
Analysis Phase
Plugins use JavaParser and commons-configuration2 to scan Java files and configuration files in the project.
Class Dependency Analysis
To accurately analyze the class dependency of the project, the plugin needs to fully analyze all the project classes used in a class file, that is: analyze each statement involving types in the code.
The plugin first scans all class information, then uses JavaParser to scan the code of each class, analyzes the types of project class files involved in the code, and finally records their relationships. The types of statements involved are as follows:
- Class definition analysis: Parsing the parent class type and implementing interface type as referenced types;
- Annotation analysis: Parsing the annotation type as referenced types;
- Field definition analysis: Parsing the field type as referenced types;
- Variable definition analysis: Parsing the variable type as referenced types;
- Method definition analysis: Parsing the return type of the method, parameter types, annotations, and thrown types as referenced types;
- Class object creation analysis: Parsing the object type of the class object creation statement as referenced types;
- Catch analysis: Parsing the object type of catch as referenced types;
- Foreach analysis: Parsing the object type of foreach as referenced types;
- For analysis: Parsing the object type of for as referenced types; To quickly parse object types, since directly using JavaParser for parsing is slow, first check if there are matching types through imports. If the match fails, then use JavaParser for parsing.
Bean Dependency Analysis
To accurately analyze the project’s bean dependency, the plugin needs to scan all the bean definitions and dependency injection methods in the project, and then analyze all the project beans that the class file depends on through static code analysis.
There are three main ways to define beans: class name annotation, method name annotation, and xml. Different ways of bean definition correspond to different bean dependency injection analysis methods, and the ultimately dependent beans are determined by the dependency injection type. The overall process is as follows:
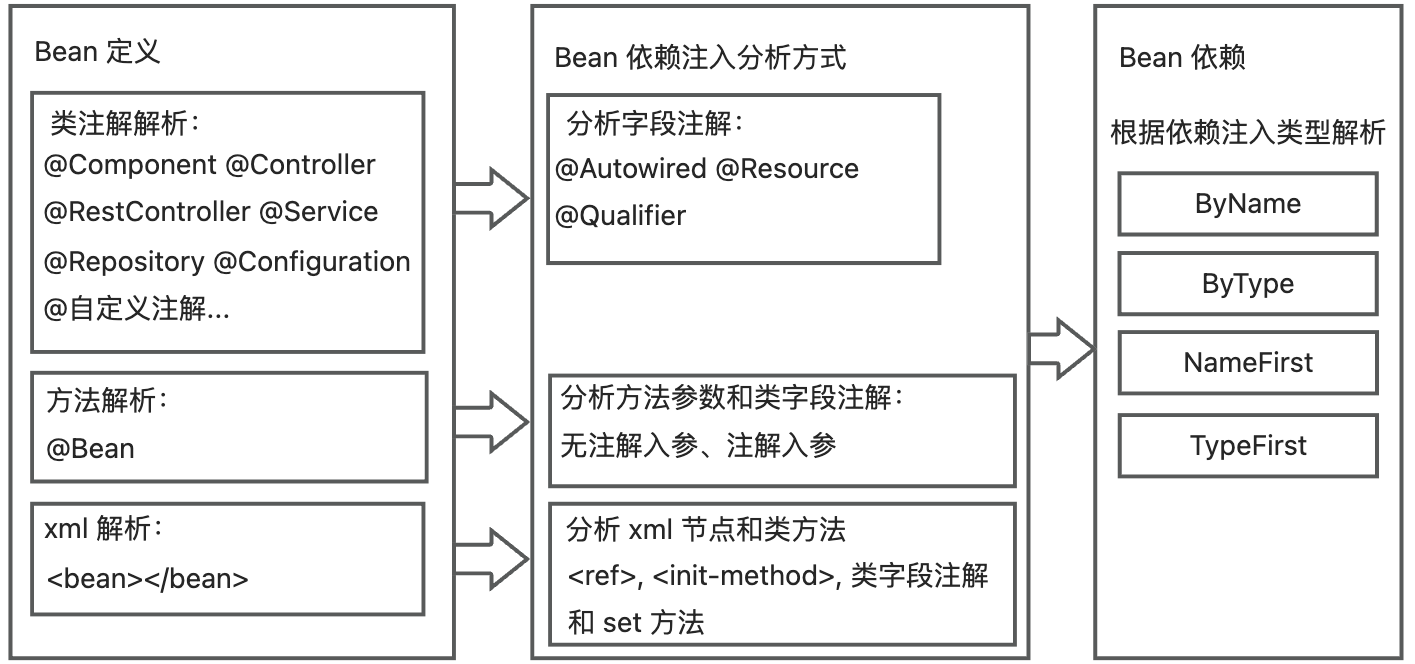
When scanning beans, the plugin parses and records bean information, dependency injection type, and dependent bean information.
- For classes defined with class annotations, it will parse the field annotations and analyze the dependency injection type and dependent bean information of the field.
- For classes defined with methods, it will parse the parameter information and analyze the dependency injection type and dependent bean information of the parameter.
- For classes defined with xml, it will analyze the dependency injection by parsing the xml and class methods:
- Parse dependencies of type byName using and
- Parse the dependency injection type and dependent bean information by parsing the fields.
- If the dependency injection type of the xml is not ’no’, then parse the dependency injection type and the corresponding dependent bean information of the set method.
- Parse dependencies of type byName using and
Finally, according to the dependency injection type, find the dependent bean information in the project’s recorded bean definitions to analyze the bean dependency relationship.
Special Multi-Application Code Analysis
Here we take the MyBatis configuration dependency analysis as an example.
When splitting out the Mapper to a module, the module needs to reuse the base data source, so the plugin needs to analyze all MyBatis configuration classes associated with the Mapper. The overall relationship between the various MyBatis configuration classes and Mapper files is connected through the MapperScanner configuration, as shown in the figure below:
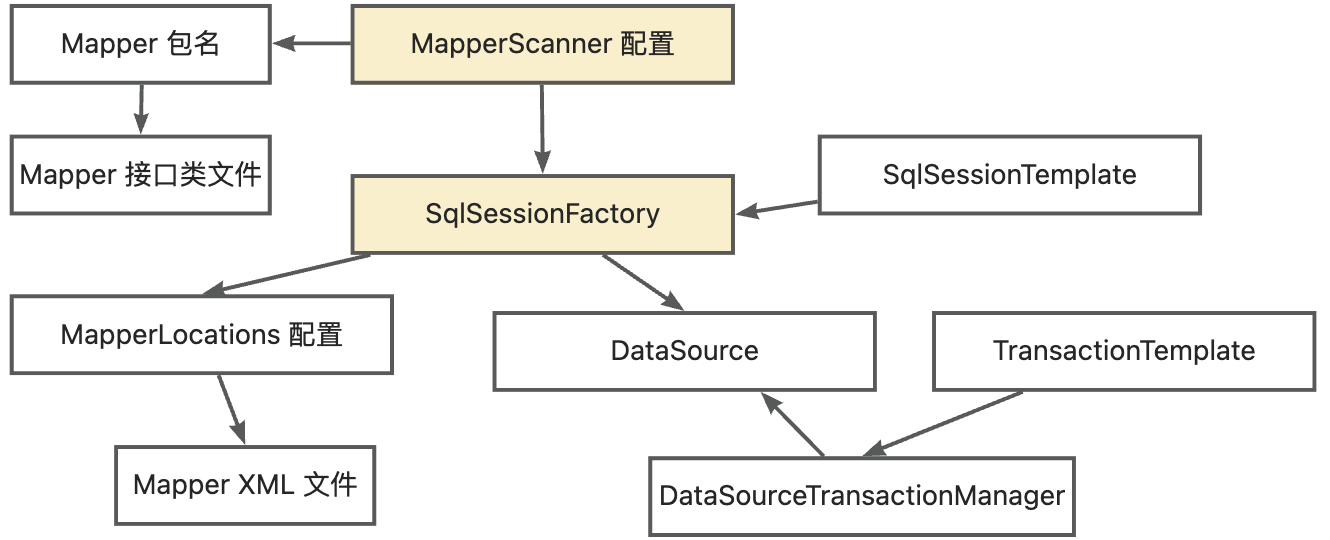
Therefore, the plugin records all Mapper class files and XML files, analyzes the associated MapperScanner, and parses all Mybatis configuration bean information associated with the MapperScanner configuration.
Interaction Phase
Here is a brief description of the implementation of dependency visualization and cross-level import.
- Visualization of dependency relationships: The plugin recursively analyzes the dependency relationships between all class files (including class dependency relationships and bean dependency relationships). Since there may be cyclic dependencies between class files, a cache is used to record all class file nodes. When recursing, the plugin prioritizes taking the dependency nodes from the cache to avoid stack overflow problems when constructing tree nodes.
- Cross-level import: Record all selected files. If folders and files within folders are selected, only import the marked files during import.
Automation Phase of Splitting
Here is a brief description of the implementation of package renaming, configuration integration, bean invocation, and special multi-application code modification (using “reusing the base data source” as an example).
- Package renaming: When the user customizes the package name, the plugin will modify the class package name and, according to the class dependency relationship, modify its import field to the new package name.
- Configuration integration: For each module of the sub-application, read all the original module configurations where the split files are located and integrate them into the new module; automatically extract bean nodes related to the sub-application from XML.
- Bean invocation: Based on the bean dependency relationship analyzed earlier, the plugin filters out the bean calls between the module and the base, and modifies the field annotations (@Autowired @Resource @Qualifier) to @AutowiredFromBase or @AutowiredFromBiz.
- Reuse of the base data source: Based on the user’s selection of Mapper files and MyBatis configuration dependency relationships, extract the MyBatis configuration information related to the Mapper. Then fill in the configuration information to the data source reuse template file and save it in the module.
Future Outlook
The above-mentioned features have been completed internally but have not been officially open-sourced. It is expected to be open-sourced in the first half of 2024. Stay tuned.
In addition, in terms of functionality, there are still more challenges to be addressed in the future: how to split the unit tests and how to verify the consistency of the split multi-application ability and single-application ability.
We welcome more interested students to pay attention to the construction of the Koupleless community together to build the Koupleless ecosystem.
6 - 6.6 ModuleControllerV2 Technical Documentation
6.1 - 6.6.1 ModuleControllerV2 Architecture
Brief Introduction
ModuleControllerV2 is a K8S control plane component based on the capabilities of Virtual Kubelet. It disguises the base as a node in the K8S system and maps the Module as a Container in the K8S system, thereby mapping Module operations to Pod operations. Utilizing K8S’s Pod lifecycle management, scheduling, and existing controllers like Deployment, DaemonSet, and Service, it achieves second-level Serverless Module operation scheduling and base interaction capabilities.
Background
The original Module Controller (hereafter referred to as MC) was designed based on K8S Operator technology.
In this mode, the original MC logically defines a separate Module control panel isolated from the base, handling operations for the base using K8S’s native capabilities and Module operations through Operator-encapsulated logic.
While this method logically distinguishes between Module and base concepts, it also presents certain limitations:
Modules are abstracted differently from the base model. Therefore, the original MC not only needs to load/unload Modules on the base but also:
- Be aware of all current bases
- Maintain base status (online status, Module loading, Module load, etc.)
- Maintain Module status (online status, etc.)
- Implement appropriate Module scheduling logic as required
This results in high development and maintenance costs. (High cost for Operator development per scenario)
Horizontal expansion of Module capabilities and roles is difficult. This implementation method is logically incompatible with traditional microservices architectures, where roles among services are similar. However, in the Operator implementation, Module and base abstraction levels differ, hindering interoperability. For example, in Koupleless’s proposal: “Modules can either attach to the base or run independently as services.” In the Operator architecture, achieving the latter requires custom scheduling logic and specific resource maintenance, leading to high development and maintenance costs for each new capability/role.
In this architecture, Module becomes a new concept, increasing learning costs for users from a product perspective.
Architecture
ModuleControllerV2 currently includes the Virtual Kubelet Manager control plane component and the Virtual Kubelet component. The Virtual Kubelet component is the core of Module Controller V2, responsible for mapping base services as nodes and maintaining Pod states on them. The Manager maintains base-related information, monitors base online/offline status, and maintains the basic runtime environment for the Virtual Kubelet component.
Virtual Kubelet
Virtual Kubelet is implemented with reference to the official documentation.
In summary, VK is a programmable Kubelet.
Just like in programming languages, VK is a Kubelet interface that defines a set of Kubelet standards. By implementing this VK interface, we can create our own Kubelet.
The Kubelet originally running on nodes in K8S is an implementation of VK, enabling K8S control plane to utilize and monitor physical resources on nodes by implementing abstract methods in VK.
Therefore, VK has the capability to masquerade as a Node. To distinguish between traditional Nodes and VK-masqueraded Nodes, we call VK-masqueraded Nodes as VNodes.
Logical Structure
In the Koupleless architecture, base services run in Pods, scheduled and maintained by K8S, and run on actual nodes.
Module scheduling needs align with base scheduling. Thus, in MC V2 design, VK is used to disguise base services as traditional K8S Nodes, becoming base VNodes, while Modules are disguised as Pods, becoming module VPods. This logically abstracts a second layer of K8S to manage VNodes and VPods.
In summary, the overall architecture includes two logical K8S:
- Base K8S: Maintains real Nodes (virtual/physical machines), responsible for scheduling base Pods to real Nodes.
- Module K8S: Maintains virtual VNodes (base Pods), responsible for scheduling module VPods to virtual VNodes.
These are called logical K8S because they do not necessarily need to be two separate K8S. With good isolation, the same K8S can perform both tasks.
This abstraction allows utilizing K8S’s native scheduling and management capabilities without extra framework development, achieving:
- Management of base VNodes (not a core capability since they are already Pods in the underlying K8S but contain more information as Nodes)
- Management of VPods (core capability: including Module operations, Module scheduling, Module lifecycle status maintenance, etc.)
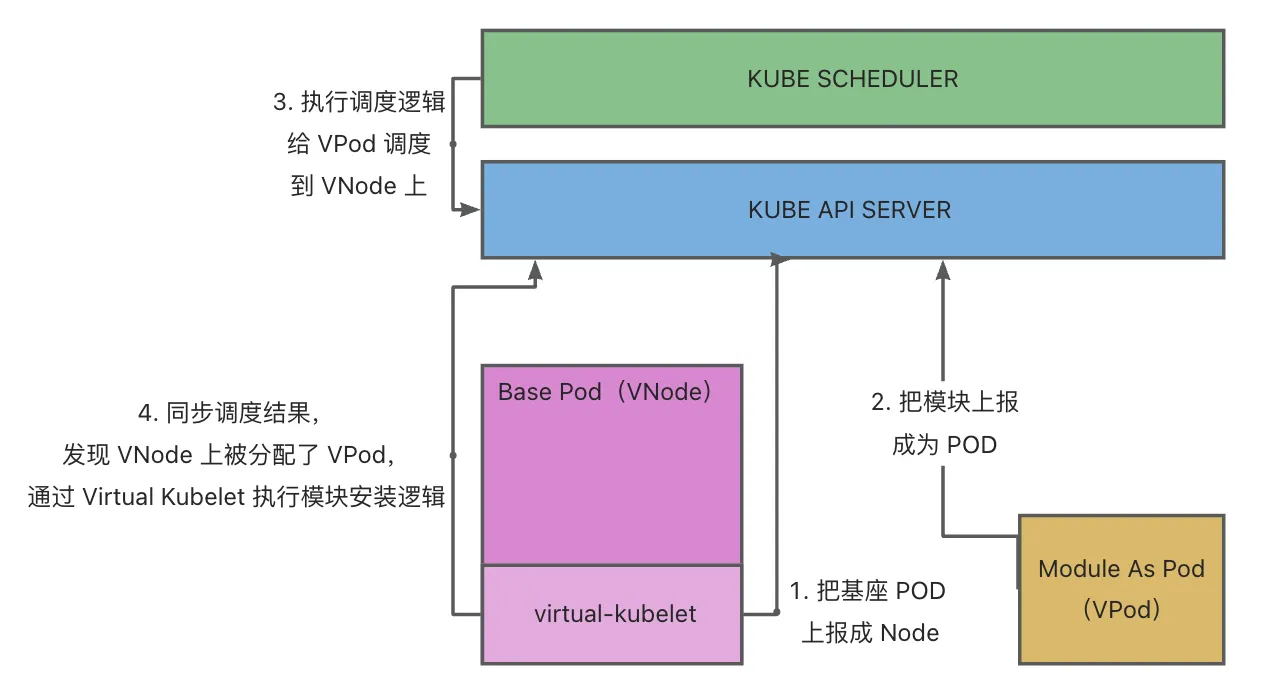
Multi-Tenant VK Architecture
Native VK uses K8S’s Informer mechanism and ListWatch to monitor pod events on the current VNode. This means each VNode requires its own monitoring logic. As the number of bases increases, API Server pressure grows rapidly, hindering horizontal scaling.
To solve this, Module Controller V2 extracts the ListWatch part of Virtual Kubelet, monitors events of specific Pods (those with certain labels in implementation), and forwards them to logical VNodes through in-process communication, reusing Informer resources. This way, each VNode only maintains local context without separate monitoring, reducing API Server pressure.
In the multi-tenant architecture, Module Controller V2 includes two core Modules:
- Base Registration Center: Discovers base services via a specific operations pipeline and maintains VK context and data transmission.
- VK: Maintains mappings between a specific base and node/pod, maintains node/pod states, and translates pod operations into corresponding Module operations for the base.
Sharded Architecture
A single Module Controller lacks disaster recovery capabilities and has an obvious upper limit. Thus, Module Controller V2 requires a more stable architecture with disaster recovery and horizontal scaling capabilities.
In Module operations, the core concern is the stability of scheduling capabilities. Under the current Module Controller architecture, scheduling stability consists of two parts:
- Stability of the dependent K8S
- Base stability
The first point cannot be guaranteed at the Module Controller layer, so high availability of the Module Controller focuses only on base-level stability.
Additionally, Module Controller’s load mainly involves monitoring and processing various Pod events, related to the number of Pods and bases under control. Due to K8S API Server’s rate limits on a single client, a single Module Controller instance has an upper limit on simultaneous event processing, necessitating load sharding capabilities at the Module Controller level.
Thus, the sharded architecture of Module Controller addresses two core issues:
- High availability of the base
- Load balancing of Pod events
In the Module Controller scenario, Pod events are strongly bound to the base, making load balancing of Pod events equivalent to balancing the managed base.
To address the above issues, Module Controller builds native sharding capability on multi-tenant Virtual Kubelet. The logic is as follows:
- Each Module Controller instance listens to the online information of all bases.
- Upon detecting a base going online, each Module Controller creates corresponding VNode data and attempts to create a VNode node lease.
- Due to naming conflicts of resources in K8S, only one Module Controller instance can successfully create a Lease, making its VNode the primary instance, while others become replicas, monitoring the Lease object and attempting to regain the primary role, achieving VNode high availability.
- Once VNode successfully starts, it listens to Pods scheduled on it for interaction, while unsuccessful VNodes ignore these events, achieving load sharding for the Module Controller.
Thus, the architecture forms: multiple Module Controllers shard VNode loads based on Lease, and multiple Module Controllers achieve VNode high availability through multiple VNode data.
Furthermore, we aim for load balancing among Module Controllers, with approximately balanced numbers of bases for each.
To facilitate open-source users and reduce learning costs, we implemented a self-balancing capability based on K8S without introducing additional components:
- Each Module Controller instance maintains its current workload, calculated as (number of VNodes currently managed / total number of VNodes). For example, if a Module Controller manages 3 VNodes out of 10, the actual workload is 3/10 = 0.3.
- Upon starting, Module Controllers can specify a maximum workload level. The workload is divided into segments based on this parameter. For example, if the maximum workload level is set to 10, each workload level contains 1/10 of the range, i.e., workload 0-0.1 is defined as workload=0, 0.1-0.2 as workload=1, and so on.
- In a sharded cluster configuration, before attempting to create a Lease, a Module Controller calculates its current workload level and waits according to the level. In this scenario, low workload Module Controllers attempt creation earlier, increasing success probability, achieving load balancing.
The process relies on K8S event broadcast mechanisms, with additional considerations depending on the operations pipeline selected during initial base onboarding:
- MQTT Operations Pipeline: Since MQTT inherently supports broadcasting, all Module Controller instances receive MQTT onboarding messages without additional configuration.
- HTTP Operations Pipeline: Due to HTTP’s nature, a base only interacts with a specific Module Controller instance during onboarding, requiring other capabilities to achieve initial load balancing. In actual deployment, multiple Module Controllers are served through a proxy (K8S Service/Nginx, etc.), allowing load balancing strategies to be configured at the proxy layer for initial onboarding balance.
6.2 - 6.6.2 ModuleControllerV2 Scheduling Principles
Brief Introduction
Module Controller V2 leverages the multi-tenant capabilities of Virtual Kubelet to map bases as Nodes in K8S. By defining modules as Pods, it reuses the K8S scheduler and various controllers to quickly build module operation and scheduling capabilities.
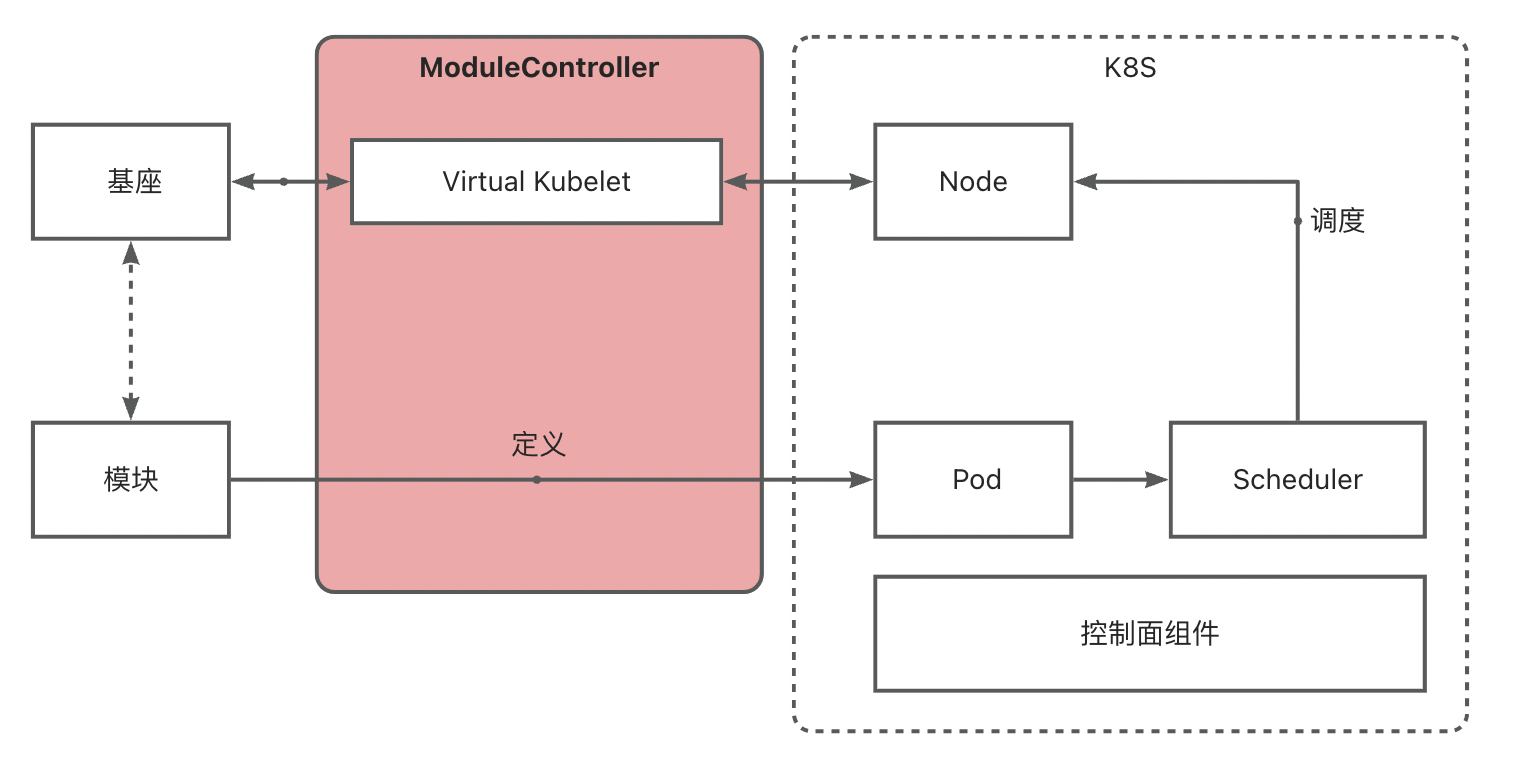
Base <-> VNode Mapping
Module Controller V2 implements base discovery through Tunnel, mapping it as a Node via Virtual Kubelet. Such Nodes are referred to as VNodes.
Upon base discovery, the configured Metadata and Network information are read. Metadata includes Name and Version, while Network includes IP and Hostname.
Metadata becomes Label information on the VNode to identify base details. Network information becomes the VNode’s network configuration. Future module pods scheduled onto the base will inherit the VNode’s IP for configuring Services, etc.
A VNode will also contain the following key information:
apiVersion: v1
kind: Node
metadata:
labels:
virtual-kubelet.koupleless.io/component: vnode # vnode marker
virtual-kubelet.koupleless.io/env: dev # vnode environment marker
base.koupleless.io/name: base # Name from base Metadata configuration
vnode.koupleless.io/tunnel: mqtt_tunnel_provider # Current tunnel ownership of the base
base.koupleless.io/version: 1.0.0 # Base version number
name: vnode.2ce92dca-032e-4956-bc91-27b43406dad2 # vnode name, latter part is UUID from the base maintenance pipeline
spec:
taints:
- effect: NoExecute
key: schedule.koupleless.io/virtual-node # vnode taint to prevent regular pod scheduling
value: "True"
- effect: NoExecute
key: schedule.koupleless.io/node-env # node env taint to prevent non-current environment pod scheduling
value: dev
status:
addresses:
- address: 127.0.0.1
type: InternalIP
- address: local
type: Hostname
Module <-> Pod Mapping
Module Controller V2 defines a module as a Pod in the K8S system, allowing for rich scheduling capabilities through Pod YAML configuration.
A module Pod YAML configuration is as follows:
apiVersion: v1
kind: Pod
metadata:
name: test-single-module-biz1
labels:
virtual-kubelet.koupleless.io/component: module # Necessary to declare pod type for module controller management
spec:
containers:
- name: biz1 # Module name, must strictly match the artifactId in the module's pom
image: https://serverless-opensource.oss-cn-shanghai.aliyuncs.com/module-packages/stable/biz1-web-single-host-0.0.1-SNAPSHOT-ark-biz.jar # jar package address, supports local file, http/https link
env:
- name: BIZ_VERSION # Module version configuration
value: 0.0.1-SNAPSHOT # Must strictly match the version in the pom
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms: # Base node selection
- matchExpressions:
- key: base.koupleless.io/version # Base version filtering
operator: In
values:
- 1.0.0 # Module may only be schedulable to certain versions of bases; if restricted, this field is required.
- key: base.koupleless.io/name # Base name filtering
operator: In
values:
- base # Module may only be schedulable to certain specific bases; if restricted, this field is required.
tolerations:
- key: "schedule.koupleless.io/virtual-node" # Ensure the module can be scheduled onto a base vnode
operator: "Equal"
value: "True"
effect: "NoExecute"
- key: "schedule.koupleless.io/node-env" # Ensure the module can be scheduled onto a base node in a specific environment
operator: "Equal"
value: "test"
effect: "NoExecute"
The above example shows only the basic configuration. Additional configurations can be added to achieve richer scheduling capabilities, such as adding Pod AntiAffinity in Module Deployment scenarios to prevent duplicate module installations.
Operations Workflow
Based on the above structure and mapping relationships, we can leverage Kubernetes (K8S) native control plane components to fulfill diverse and complex module operation requirements.
The following illustrates the entire module operations workflow using the Deployment module as an example, with the base already initialized and mapped:
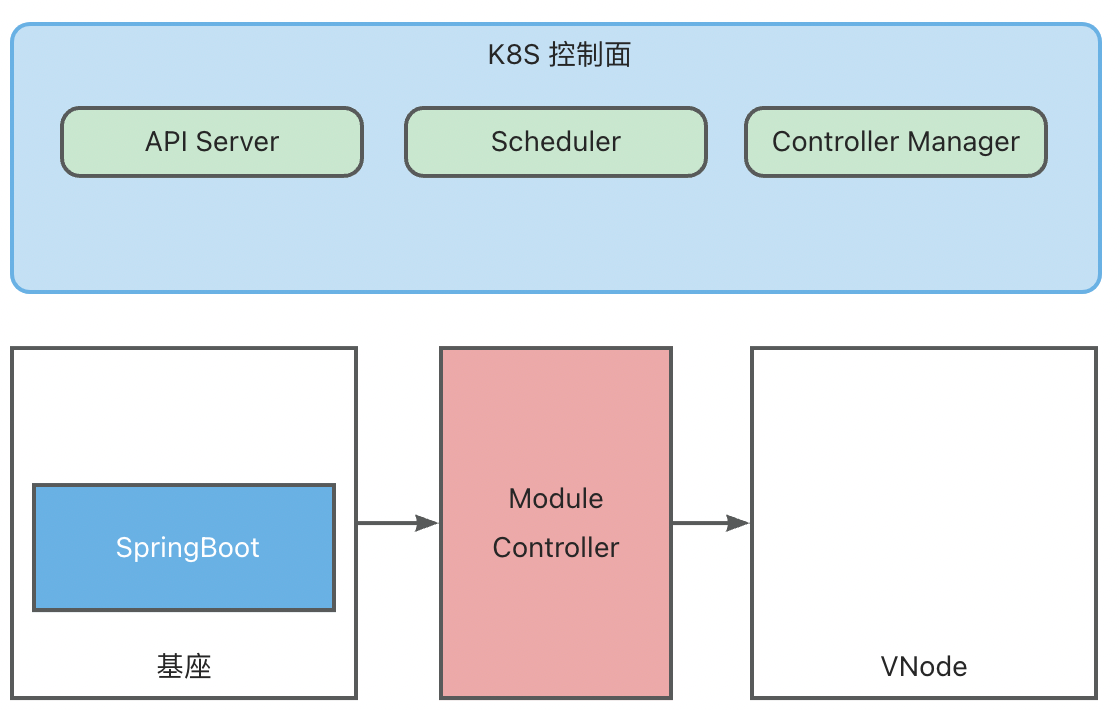
- Create the Module Deployment (a native K8S Deployment, where the PodSpec within the Template defines module information). The Deployment Controller in the K8S ControllerManager will create a virtual Pod (vPod) according to the Deployment configuration. At this point, the vPod wasn’t scheduled,with a status of Pending.
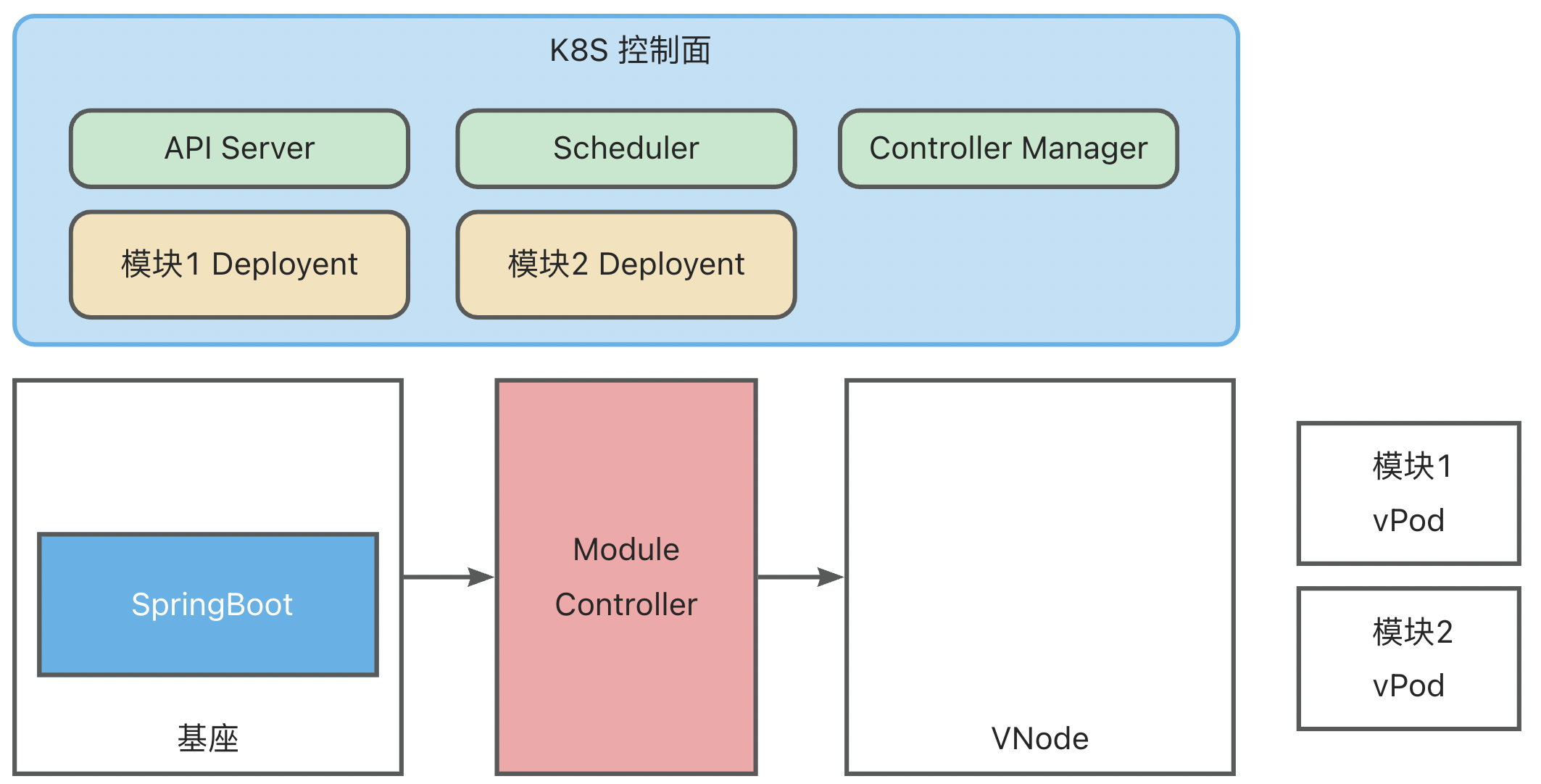
- K8S Scheduler scans unscheduled vPods and schedules them onto appropriate virtual Nodes (vNodes) based on selector, affinity, taint/toleration configurations.
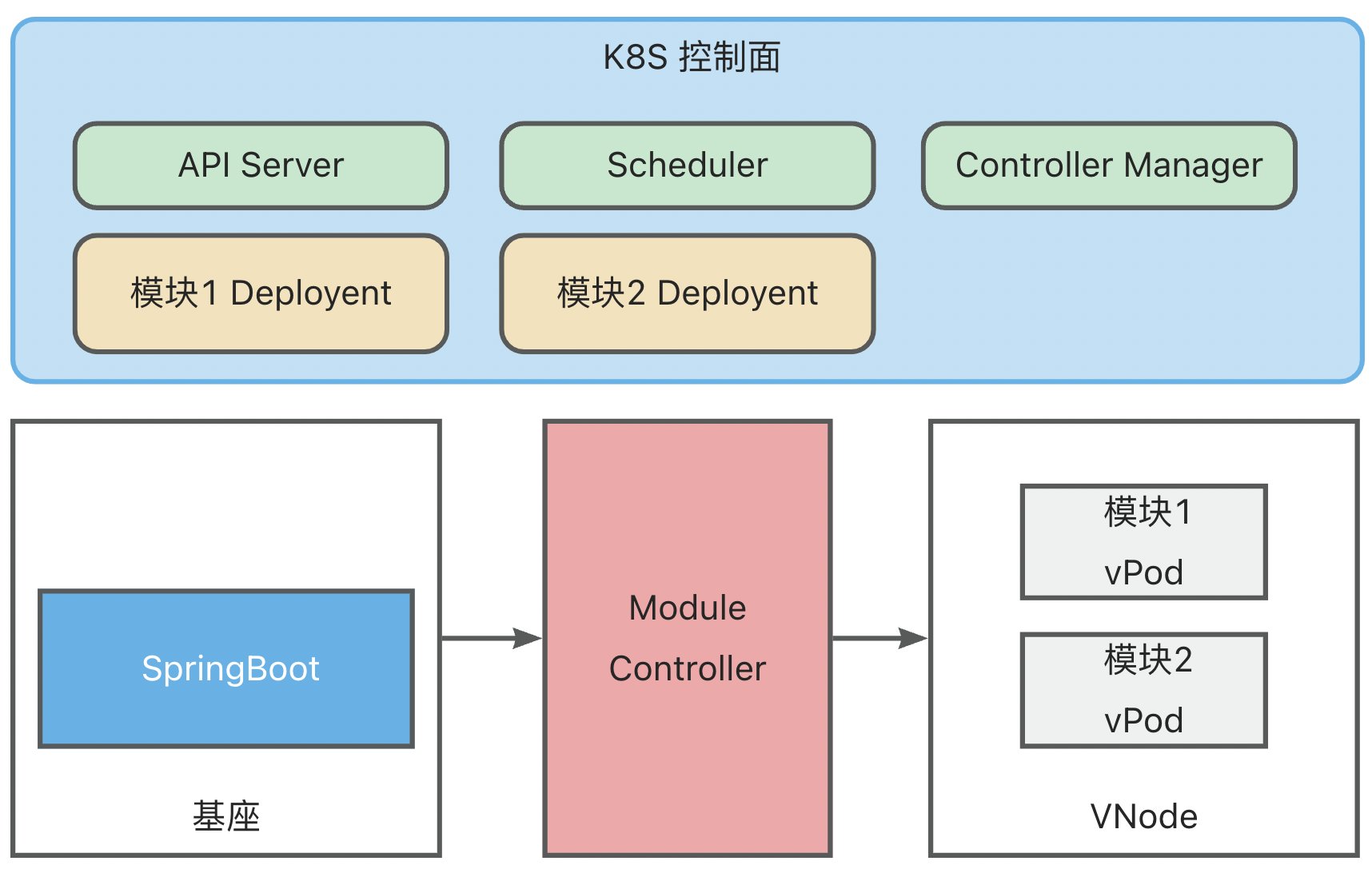
- Upon detecting the completion of vPod scheduling, the Module Controller retrieves the module information defined within the vPod and sends installation commands to the base.
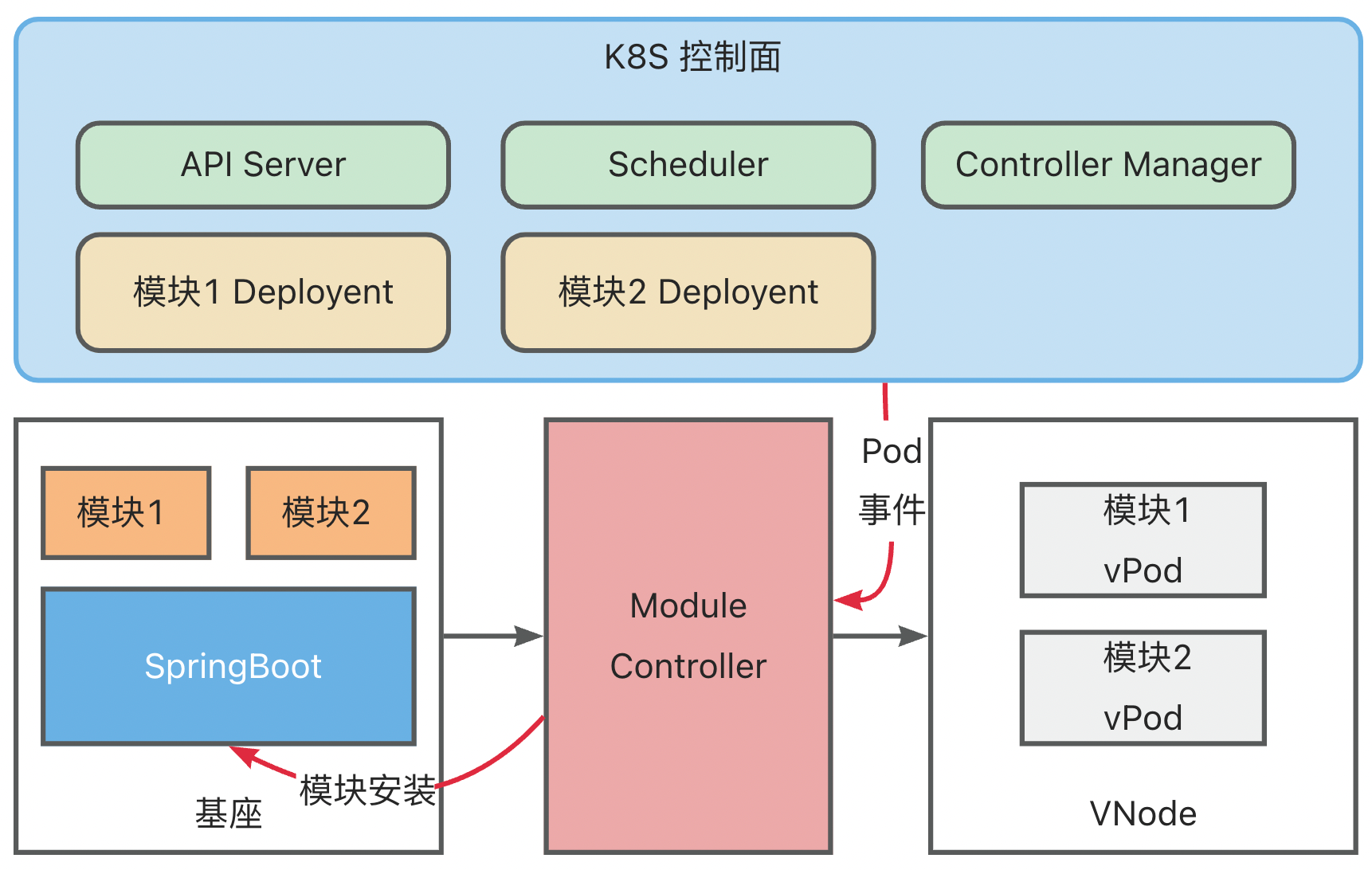
After the base completes the module installation, it synchronizes the module installation status with the Module Controller, which then translates the module status into Container Status and syncs it with Kubernetes.
Concurrently, the base continuously reports its health status. The Module Controller maps Metaspace capacity and usage to Node Memory, updating this information in Kubernetes.
Implementation Logic
The core logic involved in the implementation is as follows:
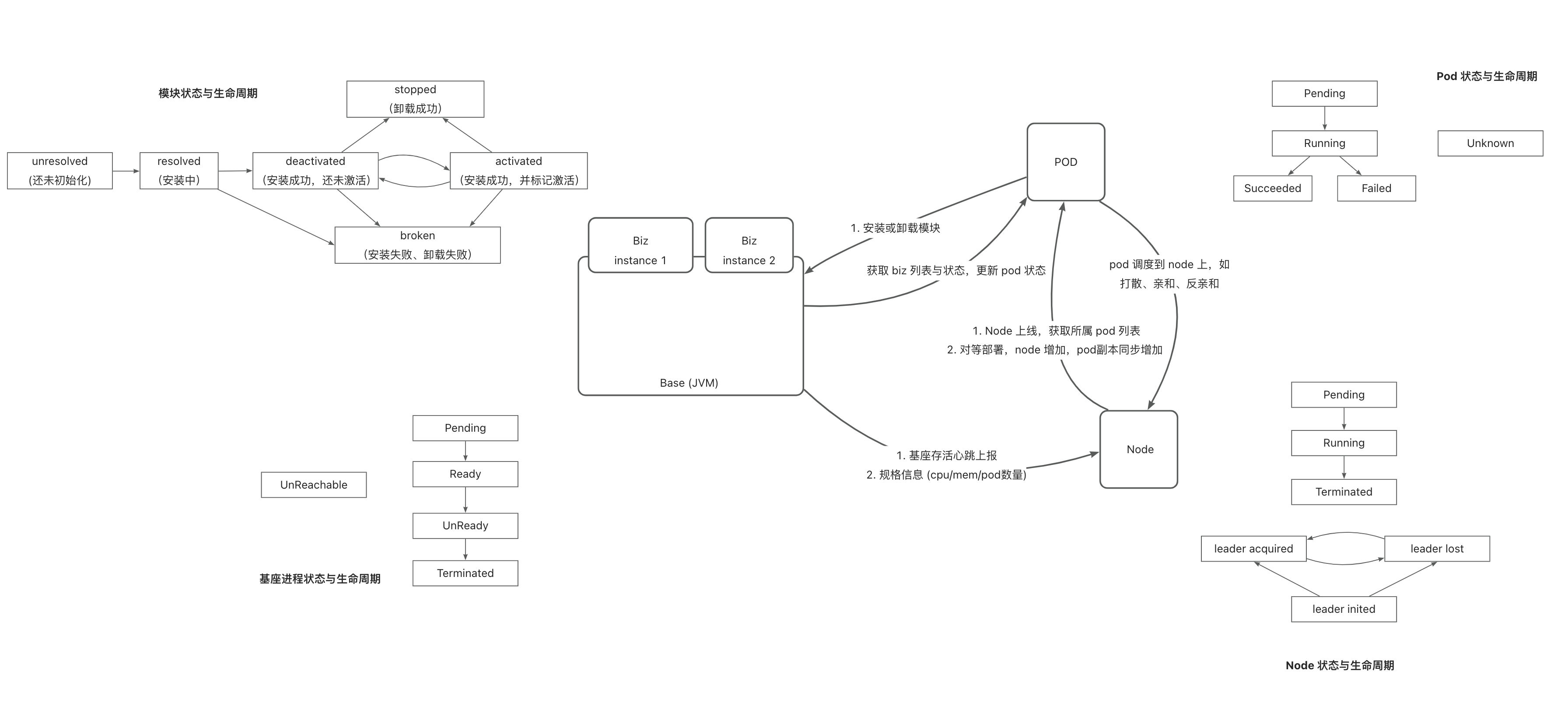
Model definition and logical relationships:
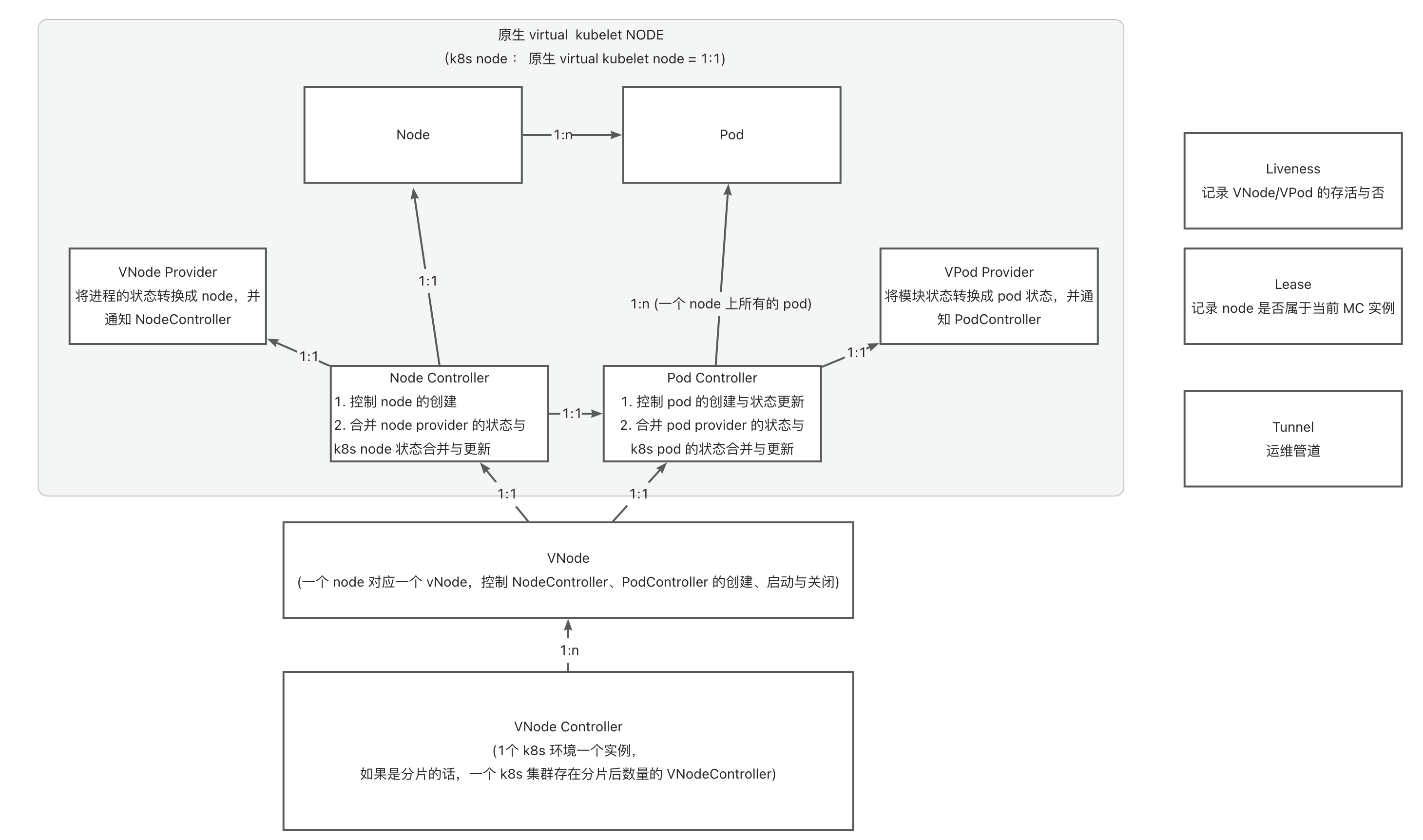
how to debug
- start module-controller test version in minikube,
serverless-registry.cn-shanghai.cr.aliyuncs.com/opensource/test/module-controller-v2:v2.1.4, the image has been configured with go-delve remote debug environment, debug port is 2345
apiVersion: apps/v1
kind: Deployment
metadata:
name: module-controller
spec:
replicas: 1
selector:
matchLabels:
app: module-controller
template:
metadata:
labels:
app: module-controller
spec:
serviceAccountName: virtual-kubelet # 上一步中配置好的 Service Account
containers:
- name: module-controller
image: serverless-registry.cn-shanghai.cr.aliyuncs.com/opensource/test/module-controller-v2:v2.1.4 # 已经打包好的镜像,镜像在 Module-controller 根目录的 debug.Dockerfile
imagePullPolicy: Always
resources:
limits:
cpu: "1000m"
memory: "400Mi"
ports:
- name: httptunnel
containerPort: 7777
- name: debug
containerPort: 2345
env:
- name: ENABLE_HTTP_TUNNEL
value: "true"
- Log in to the started container
kubectl exec module-controller-544c965c78-mp758 -it -- /bin/sh
- Enter the container and start delve
dlv --listen=:2345 --headless=true --api-version=2 --accept-multiclient exec ./module_controller
- Exit the container and set up port forwarding for port 2345
kubectl port-forward module-controller-76bdbcdd8d-fhvfd 2345:2345
- Start remote debugging in Goland or IDEA, with Host as
localhostand Port as2345.
6.3 - 6.6.3 Core Process Timeline
Base Lifecycle
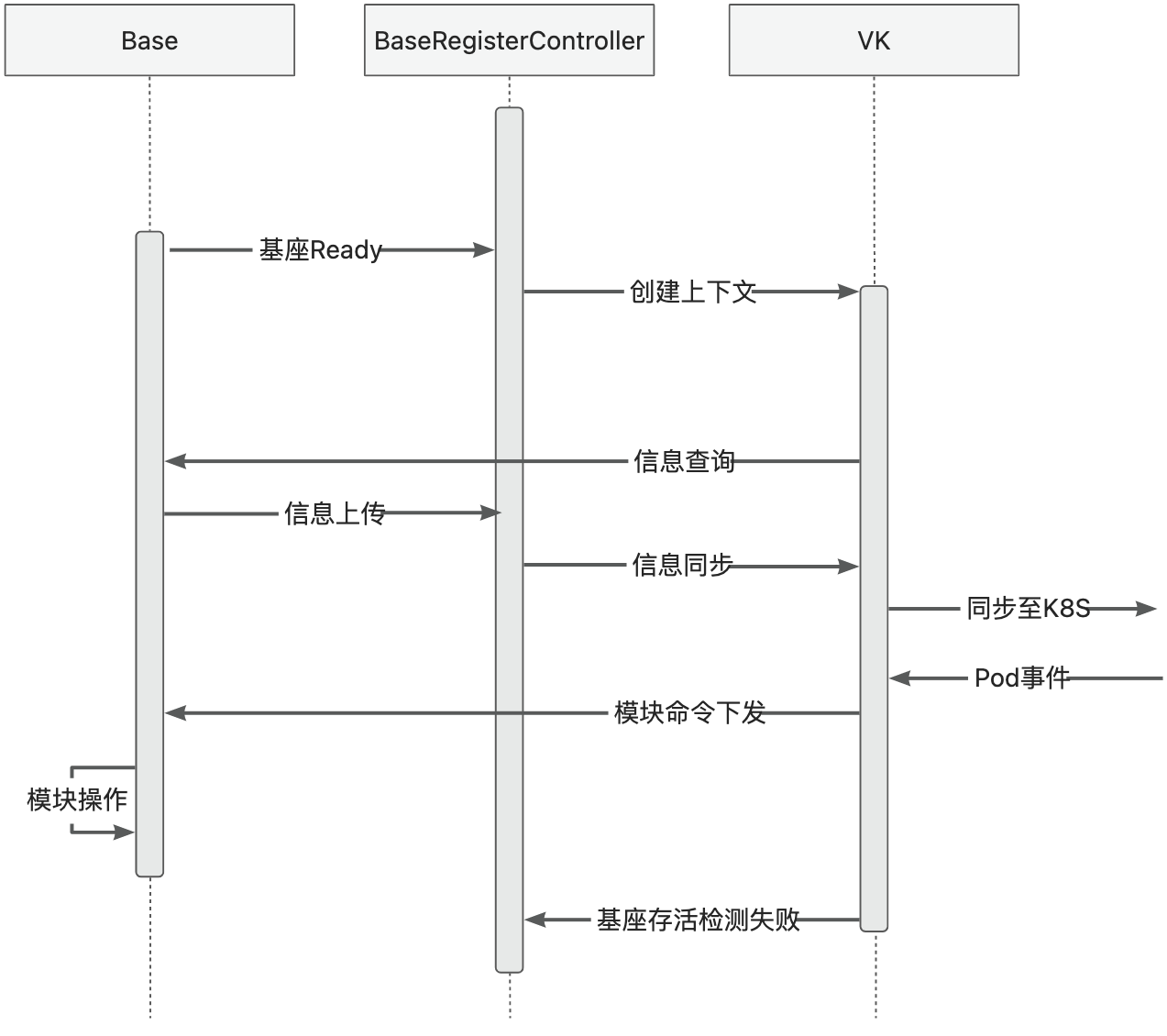
Module Release and O&M
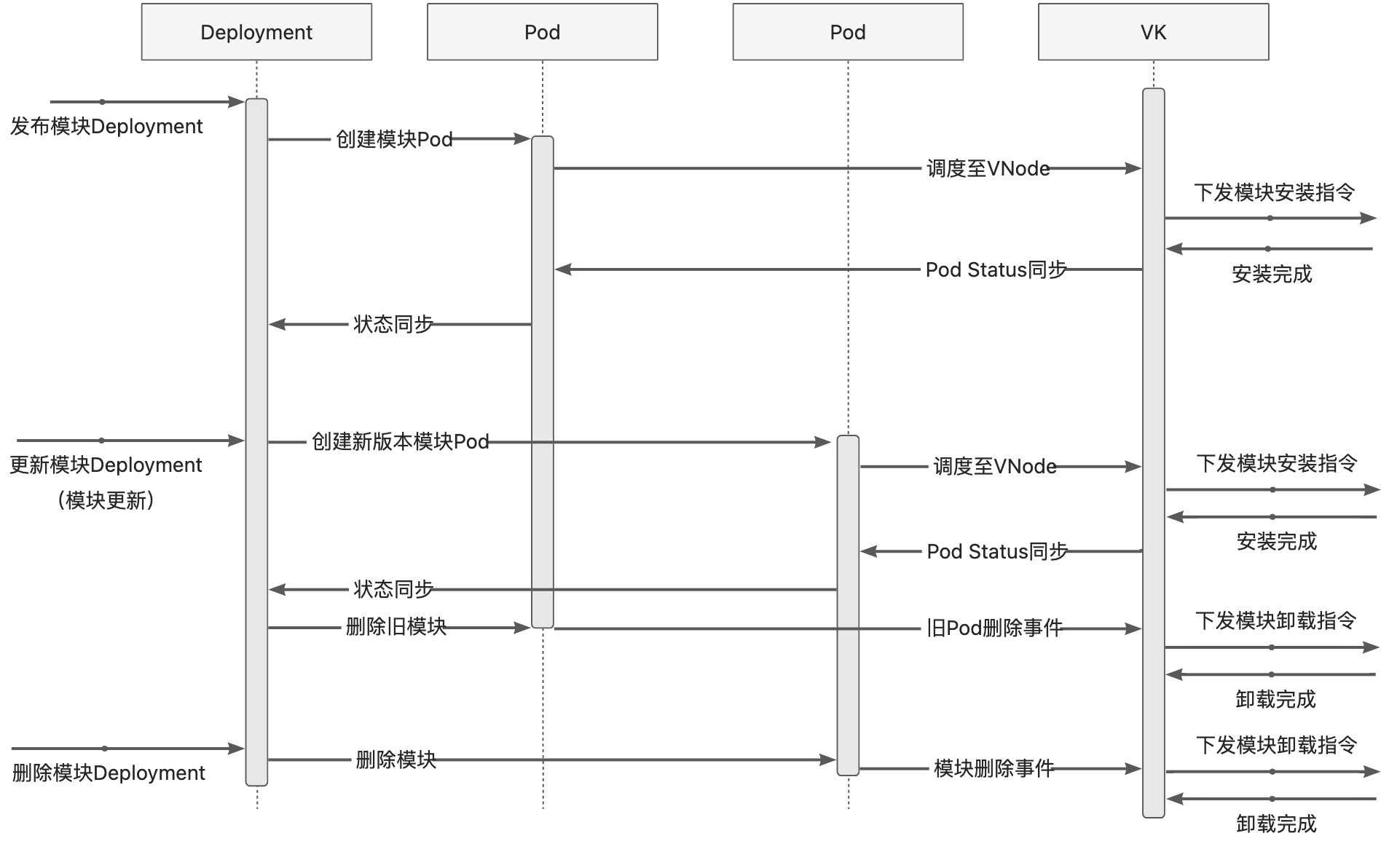
6.4 - 6.6.4 Kubelet Proxy
Kubelet Proxy
The Kubelet Proxy is an enhanced feature of Module Controller V2 on the K8s side.
It allows users to interact directly with Module Controller V2 using the kubectl tool,
providing an operational experience similar to the native K8s Kubelet.

Logs command schematic
Iteration Plan
The adaptation will be carried out in two phases:
- Use the proxy solution to provide logs capability for modules deployed in the Pod base -> Completed
- Ensure semantic consistency and implement logs capability through tunnel or arklet for smooth transition -> * Planned*
Notes
Currently, only the logs capability is implemented, and the base must be deployed in the K8s cluster.