This is the multi-page printable view of this section. Click here to print.
Module Split Tool
1 - Semi-Automated Split Tool User Guide
Background
When extracting the Koupleless module from a large monolithic SpringBoot application, users face high learning and trial-and-error costs. Users need to analyze from the service entrance which classes to split into the module, then modify the module according to the Koupleless module coding method.
To reduce learning and trial-and-error costs, KouplelessIDE plugin provides semi-automated splitting capabilities: analyzing dependencies and automating modifications.
Quick Start
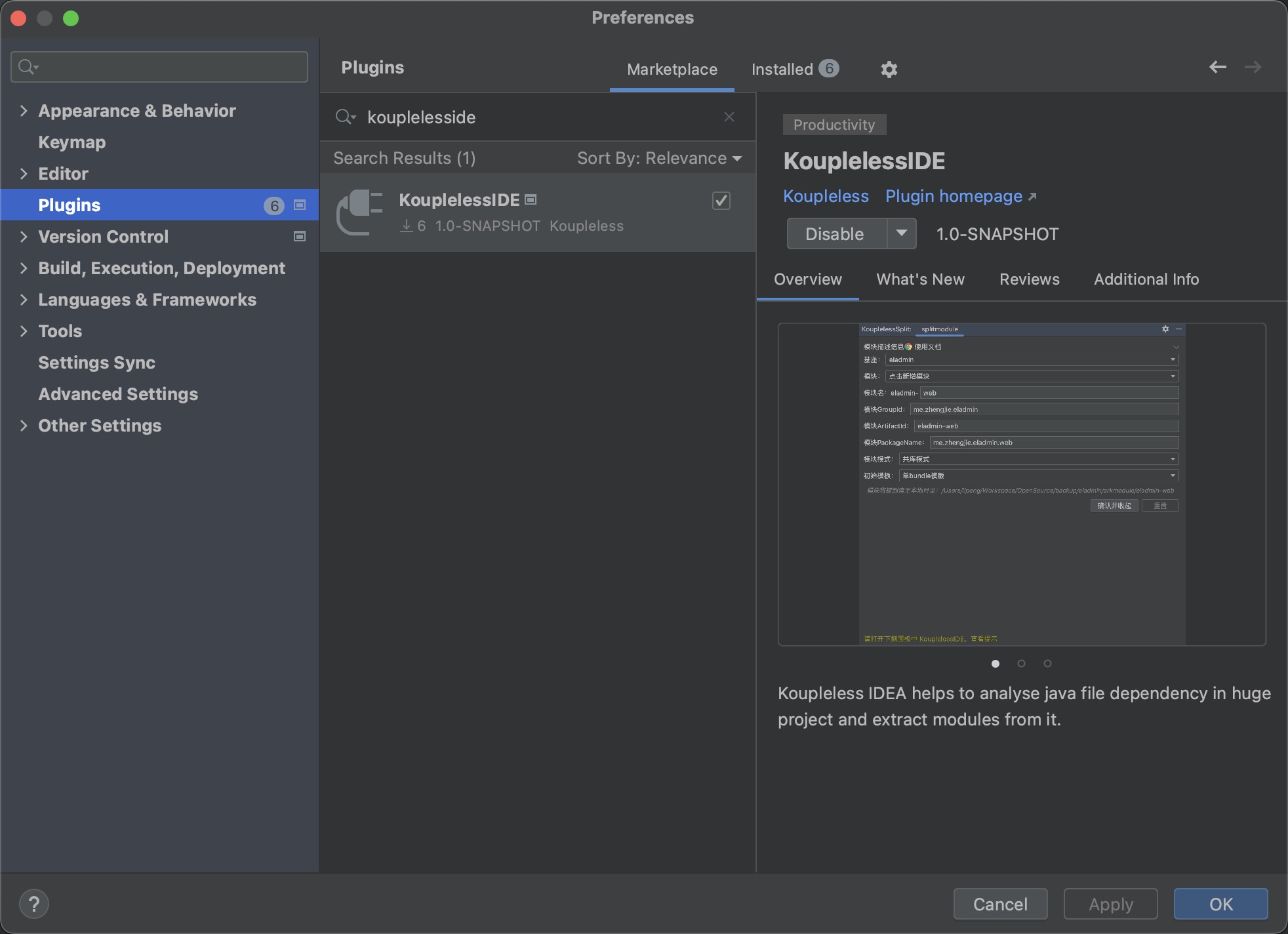
1. Install Plugin
Install the KouplelessIDE plugin from the IDEA plugin marketplace:
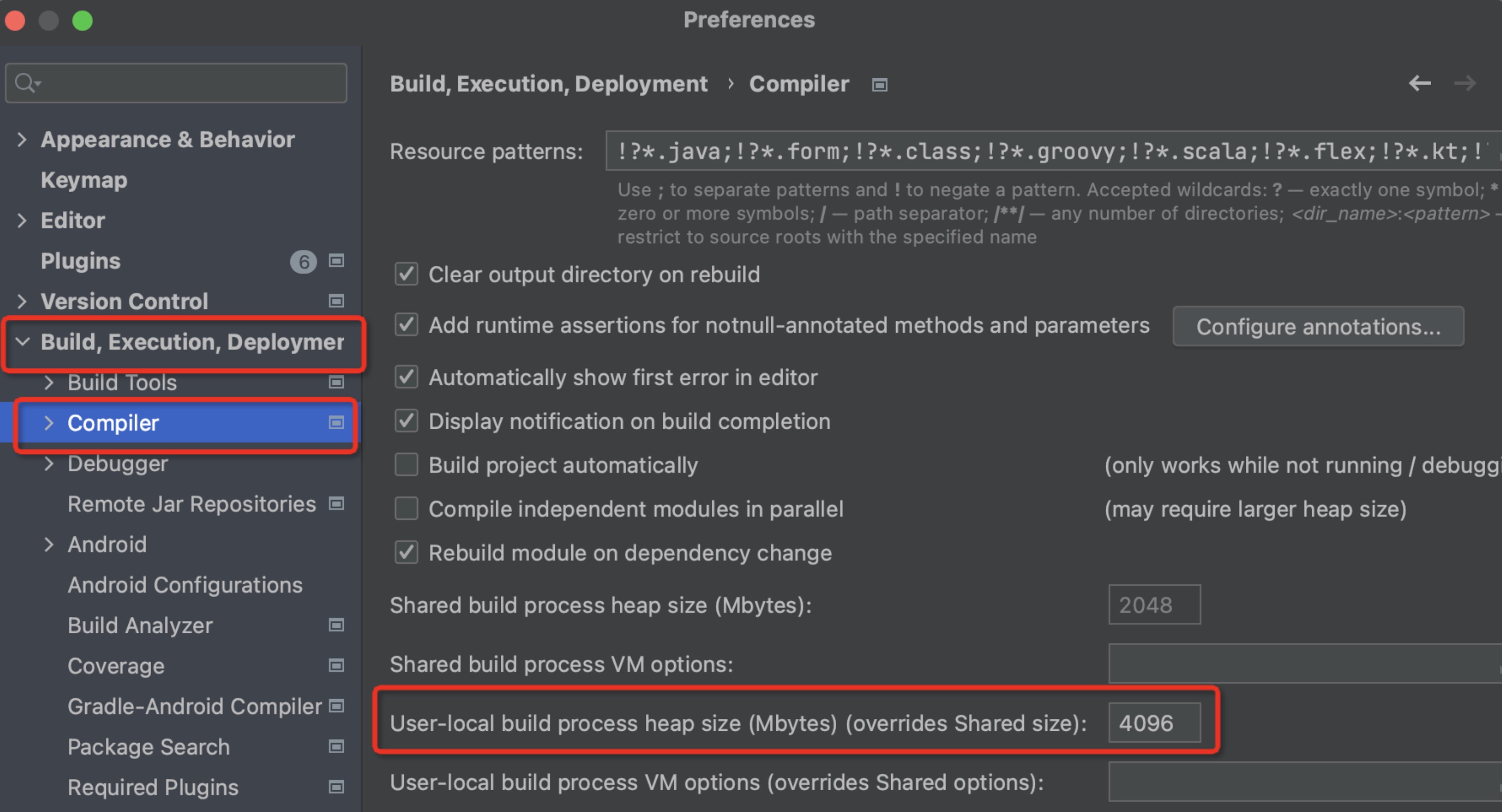
2. Configure IDEA
Ensure that IDEA -> Preferences -> Builder -> Compiler’s “User-local build process heap size” is at least 4096
3. Select Module
Step one: Open the SpringBoot application that needs splitting with IDEA, on the right panel open ServerlessSplit
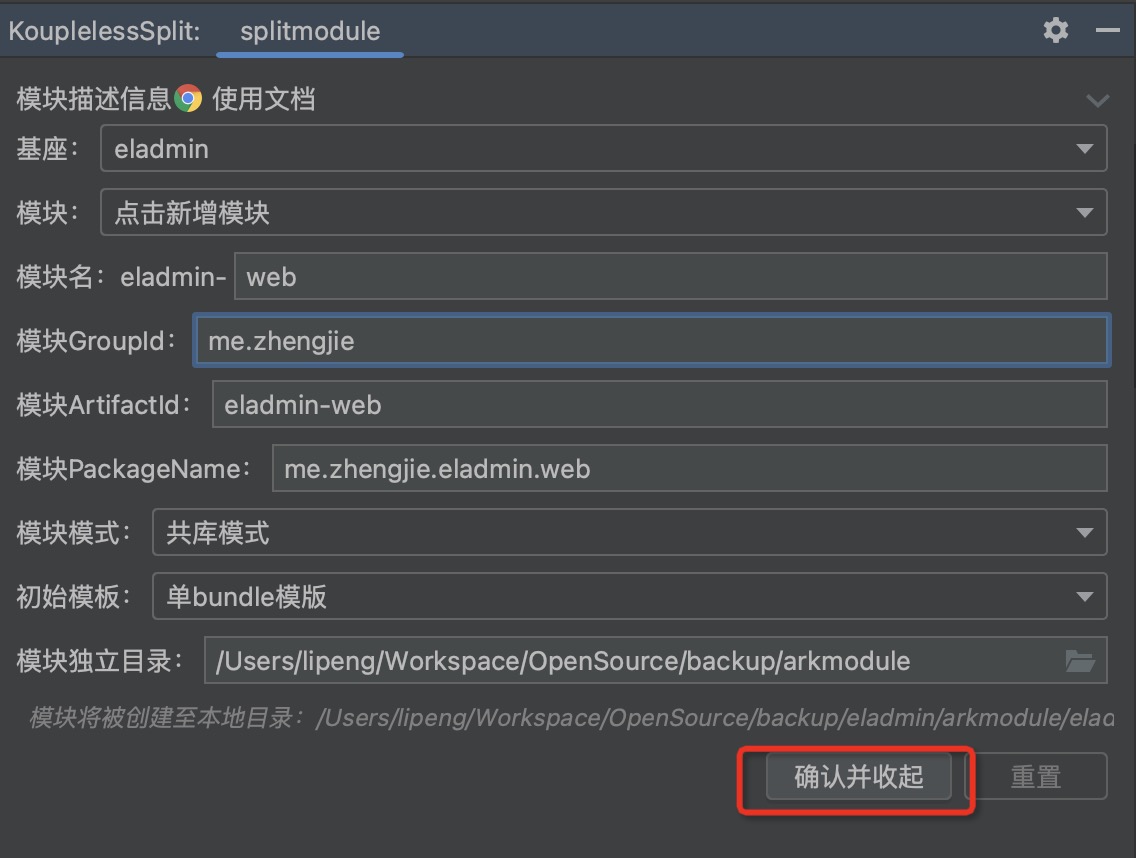
Step two: Select the splitting method as needed, click “Confirm and Collapse”
4. Dependency Analysis
During splitting, it is necessary to analyze the dependencies between classes and Beans. The plugin allows for the visualization of dependency relationships, and it is up to the business side to decide whether a class should be split into a module.
Step one: Click to activate
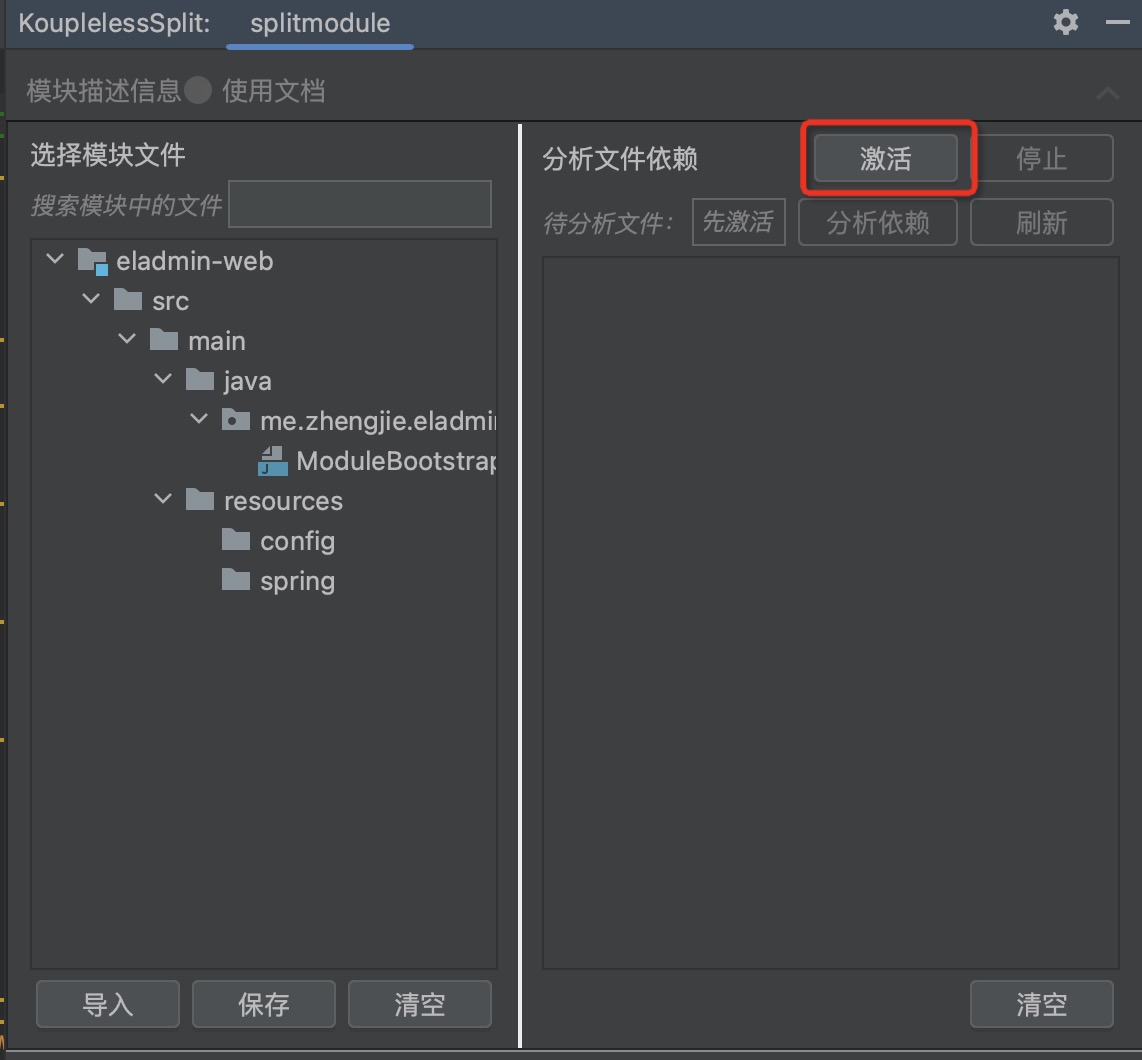
Step two: Drag the service entry to the module, supporting cross-level dragging
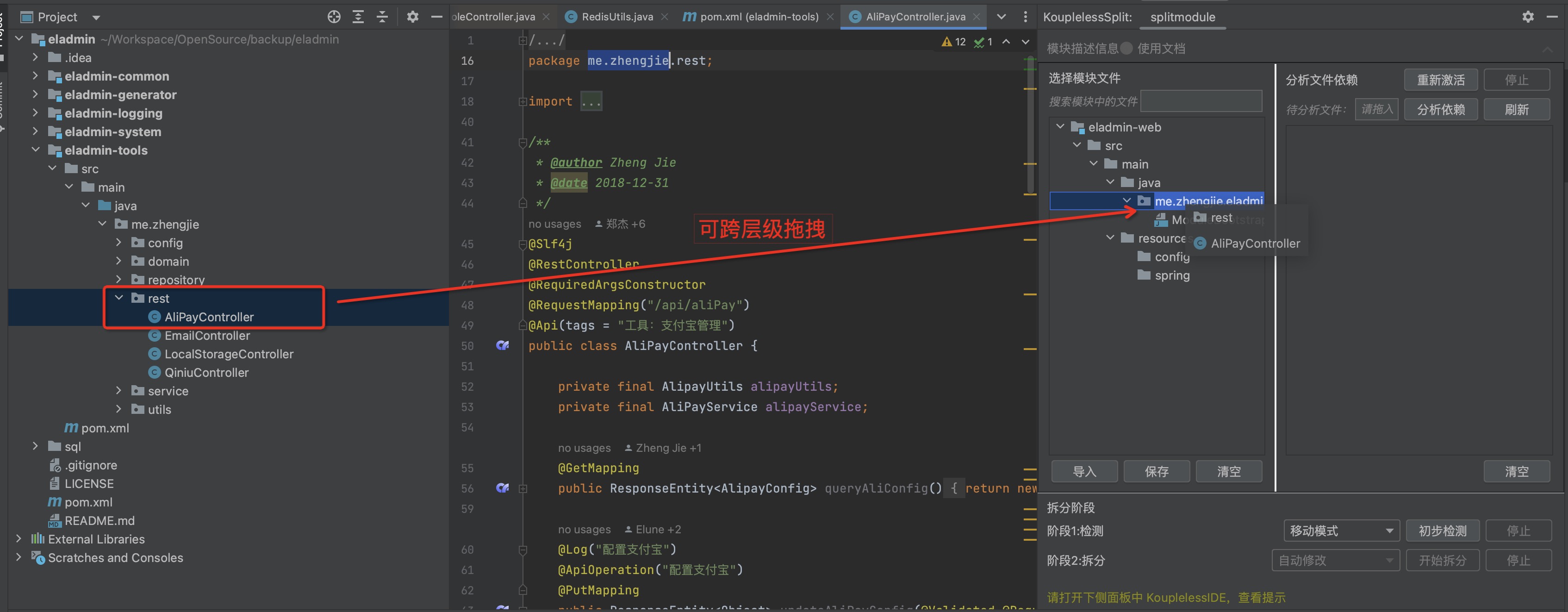
Dragging result:
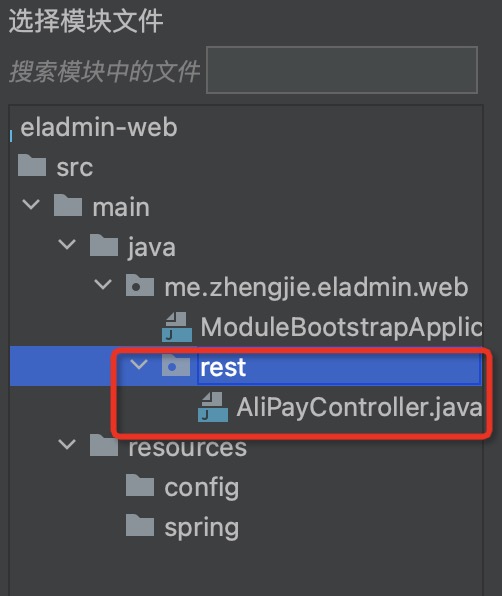
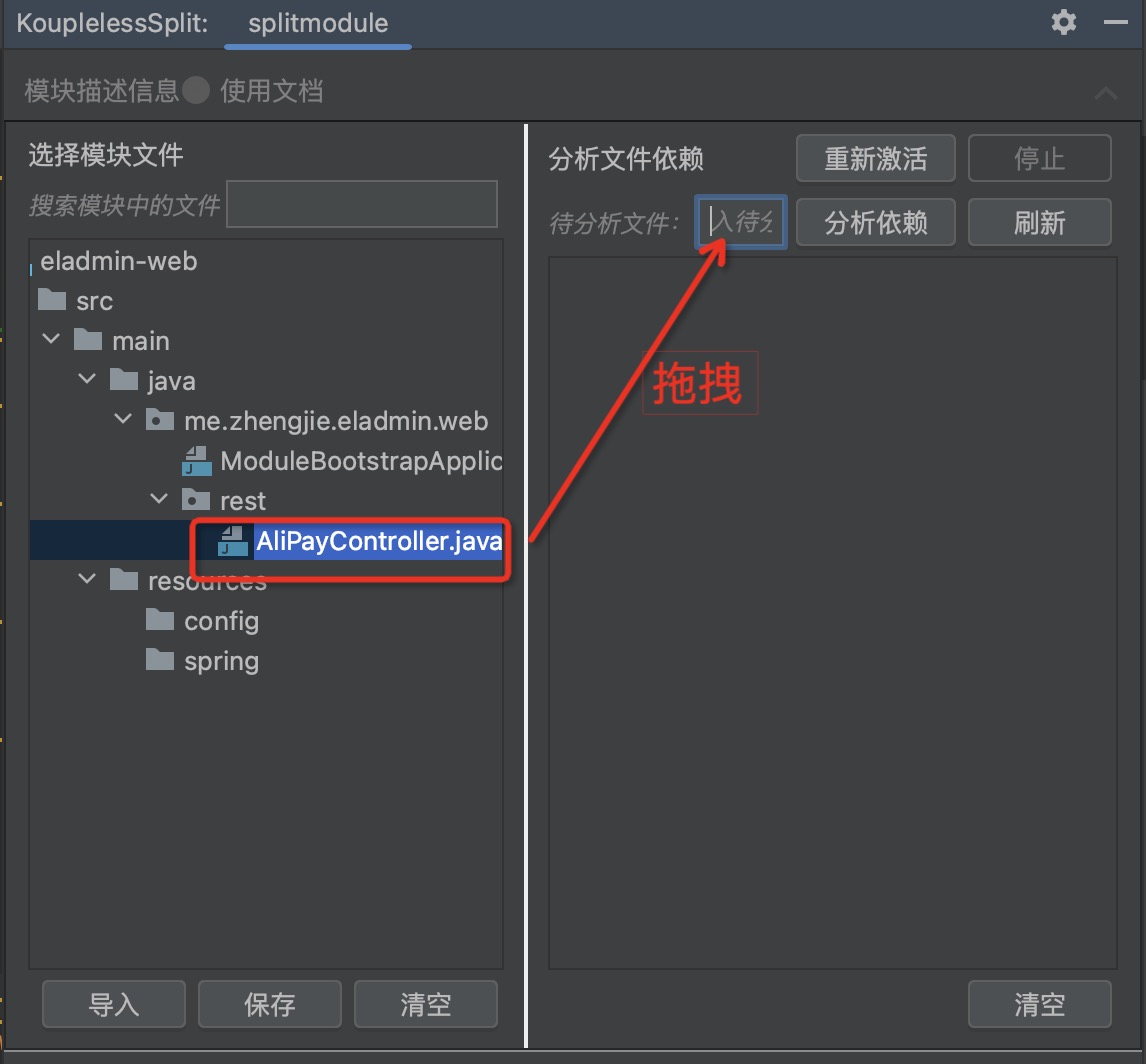
Step three: Drag the “Files for Analysis”, click to analyse dependencies, view Class/Bean dependencies as shown below:
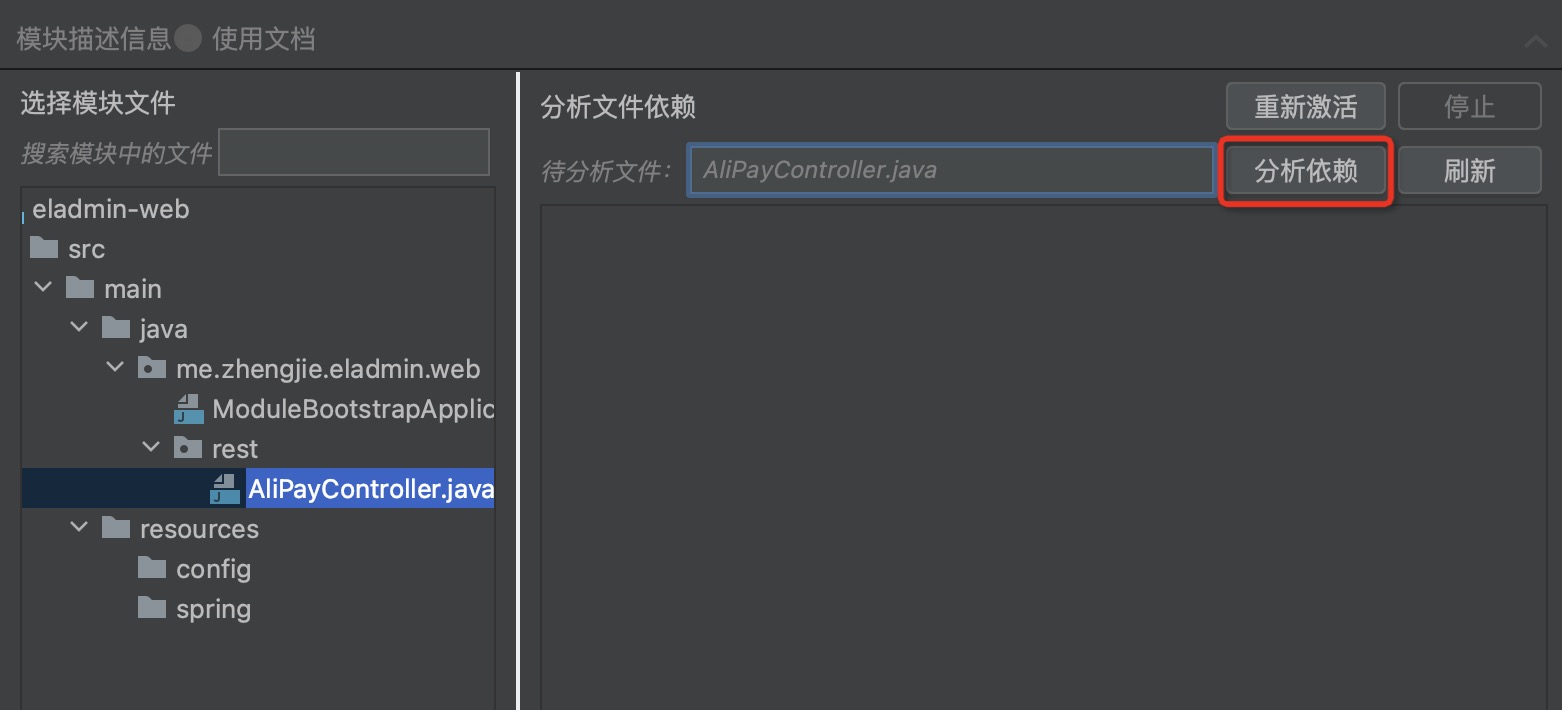
Where the icons represent:
| Icon | Meaning | Required Action |
|---|---|---|
| Already in module | No action required | |
 | Can be moved to module | Drag to module 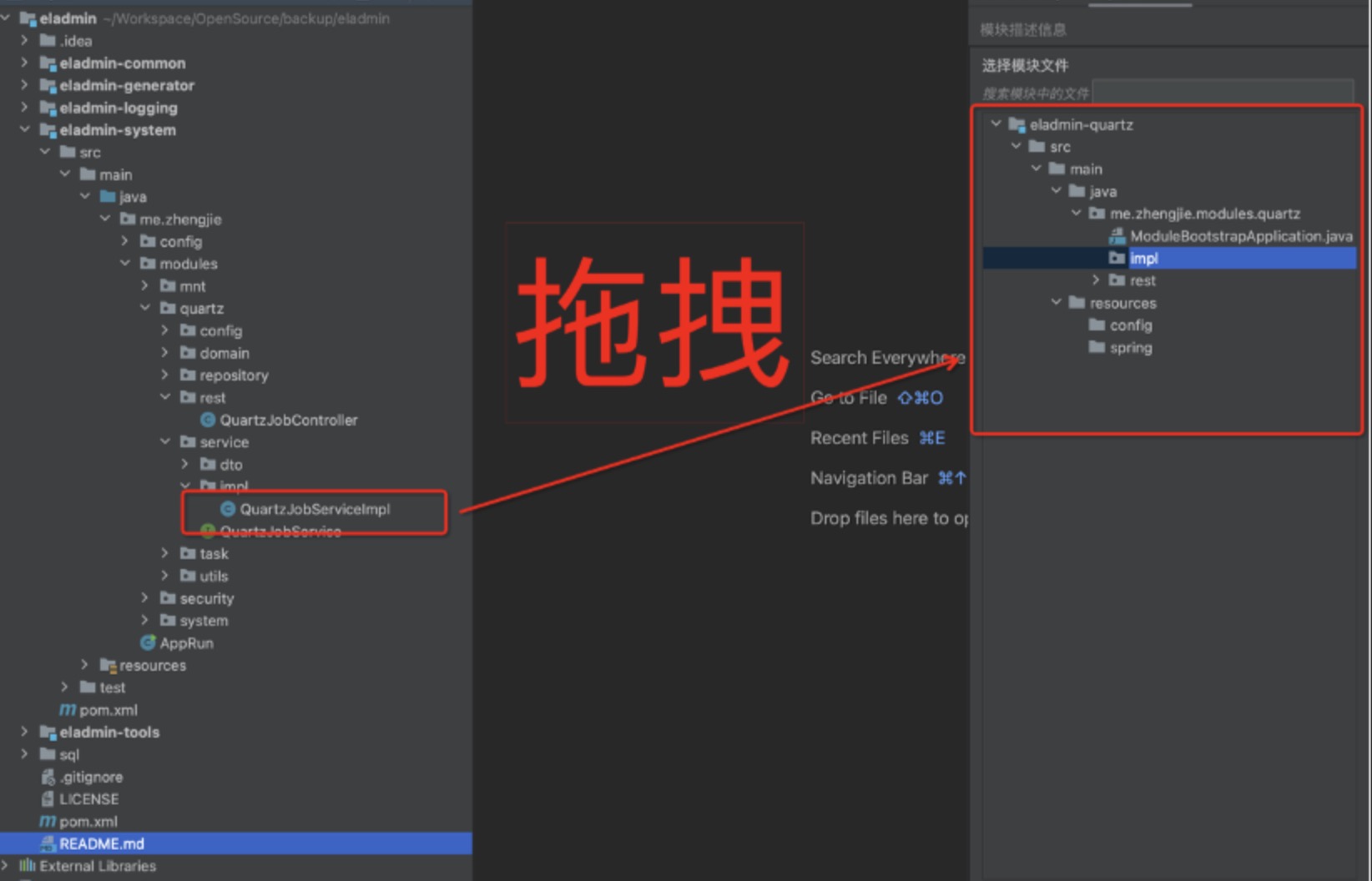 |
| Recommended to analyze dependency | Drag to analyze 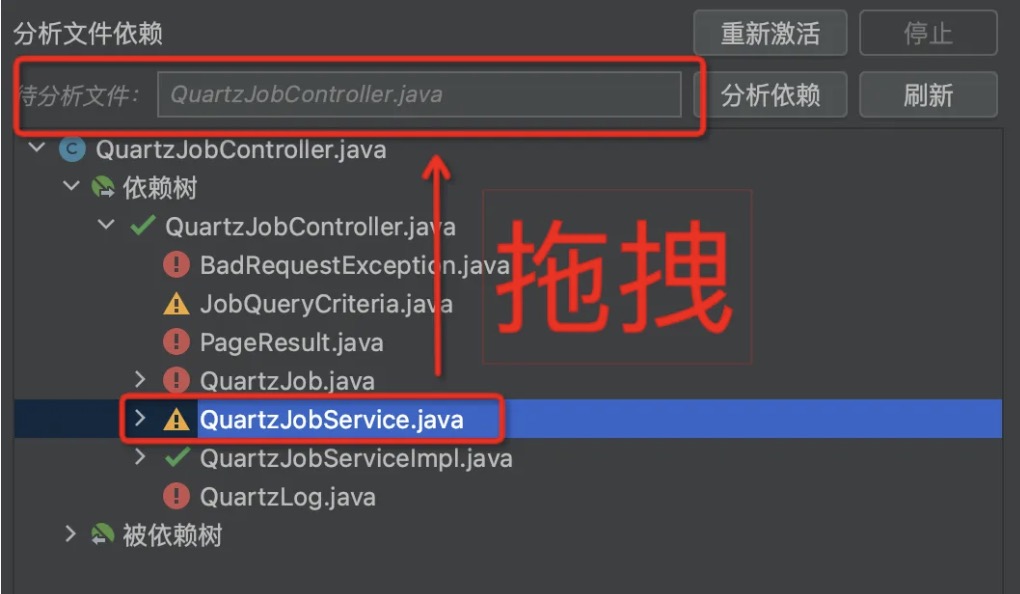 | |
| Should not be moved to module | Hover to view dependency details |
Step four: Follow the prompts, through dragging, stepwise analyze, import the necessary module files
5. Detection
Click on “Preliminary Detection”, which will prompt the user about possible issues with this split, and which middleware might require manual intervention.
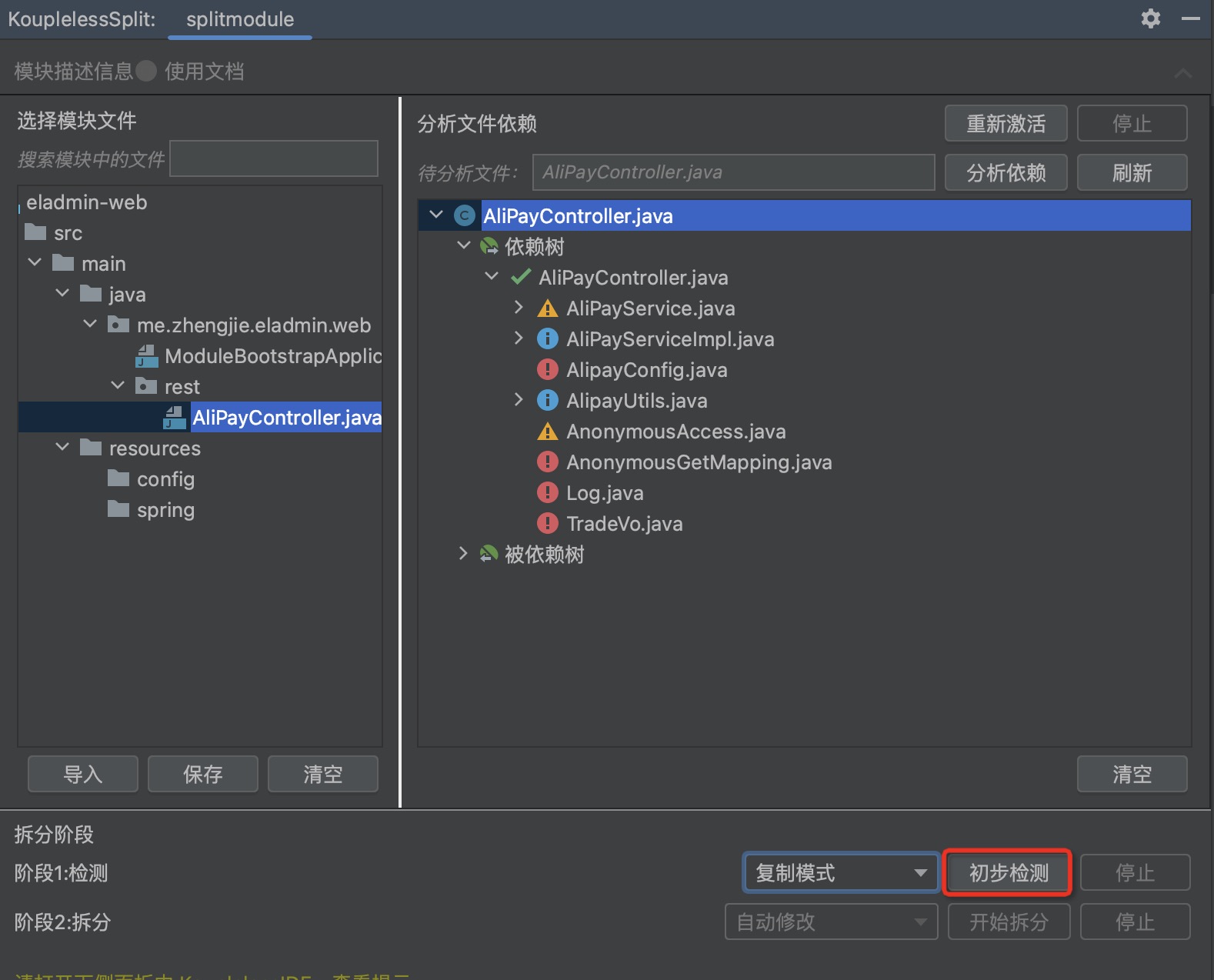
Open the lower sidebar in KouplelessIDE to view the prompts.
6. Splitting
Click to start the splitting.
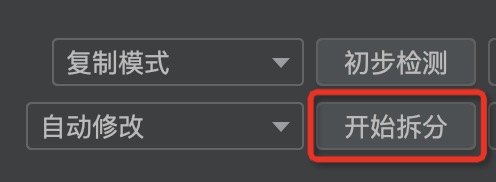
Open the lower sidebar in KouplelessIDE to view the prompts.

2 - Is it too difficult to collaborate on developing a monolithic application? Koupleless brings Split Plugin to help you streamline and improve the efficiency of collaborative development!
Background
Is the collaboration efficiency of your enterprise application low?
It takes ten minutes to compile and deploy the code even though only one line is changed;
When multiple developers work on a codebase, they frequently encounter resource contention and mutual coverage during debugging, resulting in mutual waiting for deployment…
As the project code gradually expands and the business develops, the problems of code coupling, release coupling, and resource coupling are increasingly serious, and the development efficiency keeps decreasing.
How to solve it? Try splitting a single Springboot application into multiple Springboot applications! After splitting, multiple Springboot applications can be developed in parallel without interfering with each other. In the Koupleless mode, the business can split the Springboot application into a base and multiple Koupleless modules (Koupleless modules are also Springboot applications).
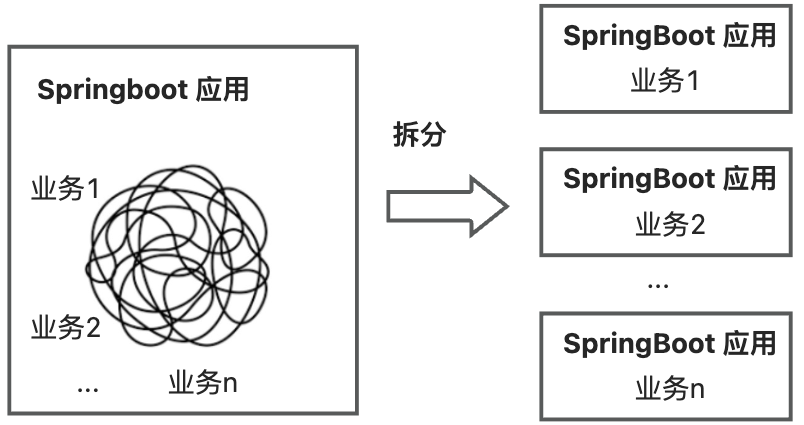
🙌 Scroll down to the “Koupleless Split Plugin Solution” section to watch the demonstration video of splitting a monolithic application!
Key Challenges
There are three key challenges in splitting multiple Springboot applications from a single one:
First, before splitting the sub-application, the complex monolithic application has high code coupling, complex dependency relationships, and a complex project structure, making it difficult to analyze the coupling between files and even more difficult to split out sub-applications, hence the need to solve the problem of analyzing file dependencies in the complex monolithic application before splitting.
Second, when splitting the sub-application, the operation of splitting is cumbersome, time-consuming, and requires users to analyze dependency relationships while splitting, thus imposing high demands on users, therefore there is a need to reduce the user interaction cost during the splitting.
Third, after splitting the sub-application, the monolithic application evolves into a multi-application coexistence, and its coding mode will change. The way Bean is called transitions from a single application call to a cross-application call, and special multi-application coding modes need to be adjusted according to the framework documentation. For example, in Koupleless, in order to reduce the data source connection of modules, modules will use the data source of the base in a certain way, resulting in a very high learning and adjustment cost, hence the need to solve the problem of the evolution of coding modes in multiple applications after splitting.
Koupleless Split Plugin Solution
In response to the above three key challenges, the Koupleless IntelliJ IDEA Plugin divides the solution into 3 parts: analysis, interaction, and automated splitting, providing dependency analysis, user-friendly interaction, and automated splitting capabilities, as shown in the following figure:
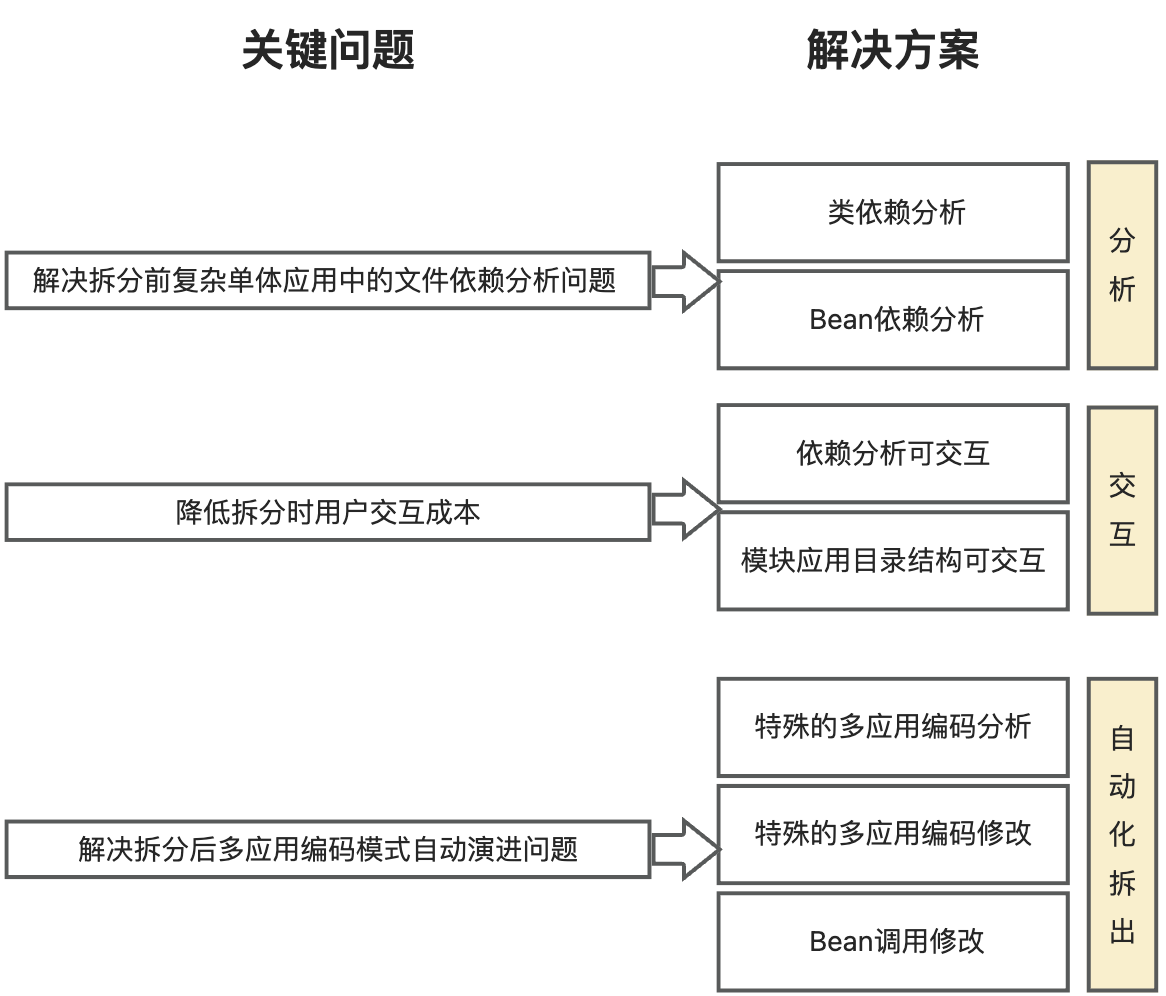
- In the analysis, analyze the dependency relationships in the project, including class dependencies and Bean dependencies, to solve the problem of analyzing file dependencies in the complex monolithic application before splitting;
- In the interaction, visualize the dependency relationships between class files to help users sort out the relationships. At the same time, visualize the module directory structure, allowing users to decide which module files to split by dragging and dropping, thus reducing the user interaction cost during splitting;
- In the automated splitting, the plugin will build the modules and modify the code according to the special multi-application coding, solving the problem of the evolution of coding modes in multiple applications after splitting.
🙌 Here is a demonstration video of the semi-automatic splitting with Koupleless, which will help you better understand how the plugin provides assistance in analysis, interaction, and automated splitting.
Example of Understanding the Advantages of Koupleless Solution
Suppose a business needs to separate the code related to the system into modules, while keeping the common capabilities in the base. Here we take the entry service of the system, QuartzJobController, as an example.
Step 1: Analyze Project File Dependencies
First, we will analyze which classes and beans QuartzJobController depends on.
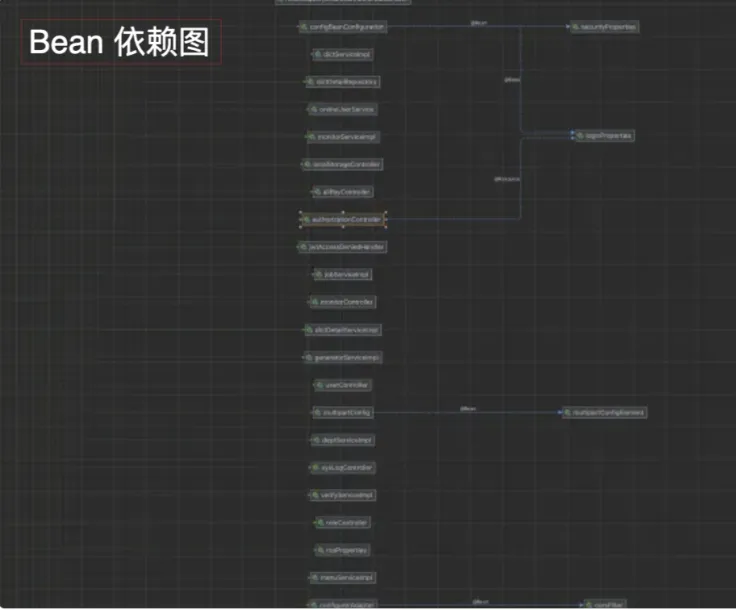
Method 1: Using IntelliJ IDEA Ultimate, perform bean and class analysis on the controller to obtain the following bean dependency diagram and class dependency diagram.
 |  |
|---|
- Advantage: Comprehensive analysis with the help of IntelliJ IDEA Ultimate
- Disadvantage: Requires analysis of each class file, and the bean dependency diagram may not be very readable.
Method 2: Use mental analysis
When class A depends on classes B, C, D, … N, when separating them, it is necessary to analyze whether each class is being depended on by other classes and whether it can be separated into modules.
- Advantage: Intuitive
- Disadvantage: When class A has many dependencies, it requires recursive mental analysis.
Method 3: Use the Koupleless assistant tool for easy analysis! Select any class file you want to analyze, click “Analyze Dependencies,” and the plugin will help you analyze. It not only analyzes the classes and beans that the class file depends on, but also suggests which classes can be separated out and which cannot.
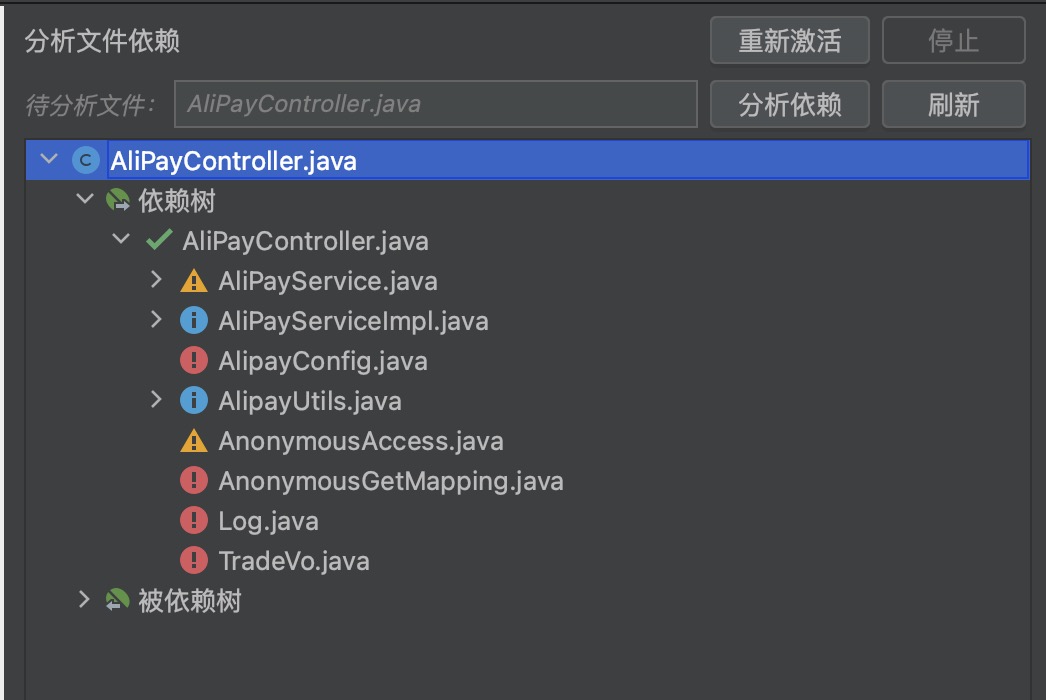
For example, when the selected module includes QuartzJobController, QuartzJobService, and QuartzJobServiceImpl, the dependency of QuartzJobController on classes and beans is as shown in the following diagram:
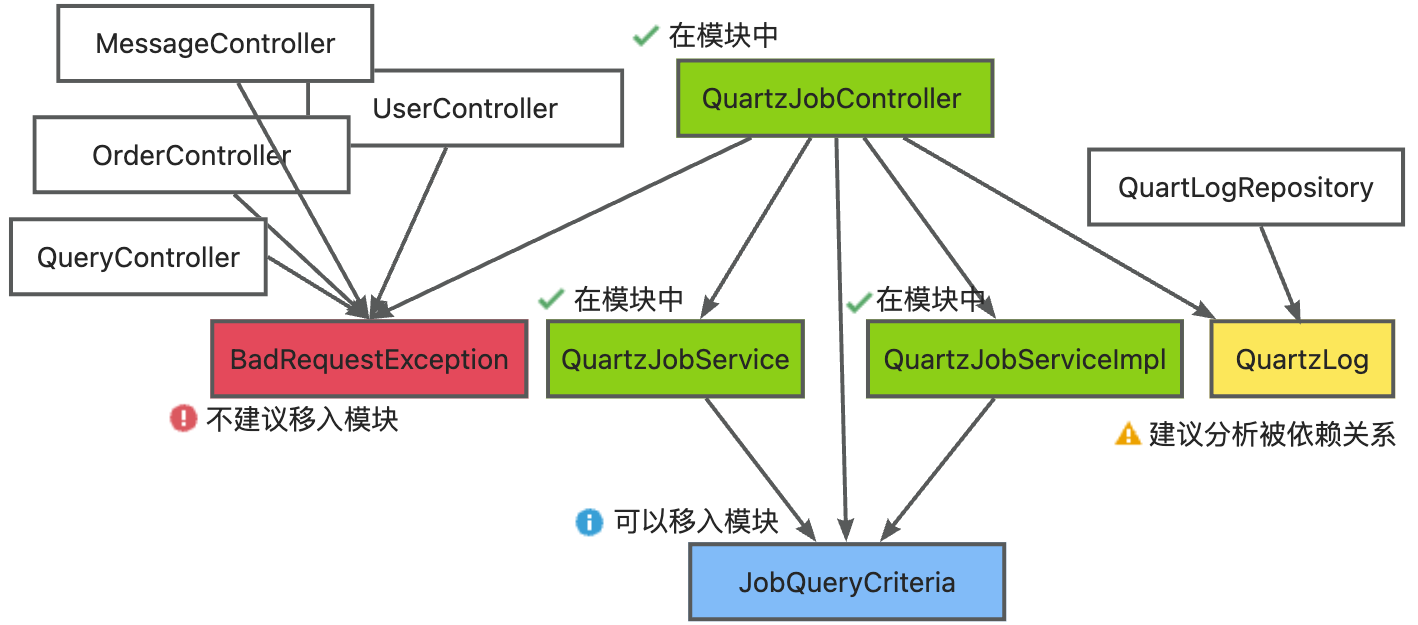
The dependent classes/beans of QuartzJobController are divided into four categories: already in the module, can be moved into the module, suggested to analyze the dependency relationship, and not recommended to be moved into the module.
- If it is in the module, it is marked as green “already in the module,” such as QuartzJobService and QuartzJobServiceImpl.
- If it is only depended on by module classes, then it is marked as blue “can be moved into the module,” such as JobQueryCriteria.
- If it is only depended on by one non-module class, then it is marked as yellow “suggested to analyze the dependency relationship,” such as QuartLog.
- If it is depended on by many non-module classes, then it is marked as red “not recommended to be moved into the module,” such as BadRequestException.
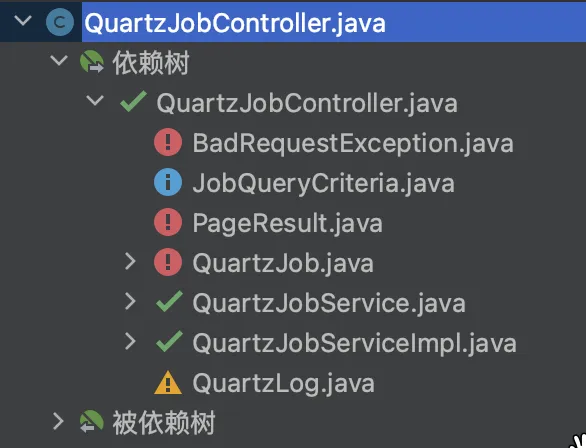
When using the plugin to analyze QuartzJobController and JobQueryCriteria, the dependency tree and the dependency by tree are as follows, corresponding to the analysis above:
 |  |
|---|
- Advantage: Intuitive, easy to use, and friendly prompts
- Disadvantage: The plugin only supports the analysis of common bean definitions and class references
Step 2: Separate into Modules & Modify Single Application Coding to Multi-Application Coding Mode
Separate the relevant class files into modules.
Method 1: Copy and paste each file, mentally analyze the bean calls between all module and bases, and modify the code according to the multi-application coding mode.
When separating, questions may arise: Where did I just separate to? Is this file in the module? Do I need to refactor these package names? Are the bean calls cross-application? Where is the documentation for multi-application coding?
- Advantage: Can handle multi-application coding modes that the plugin cannot handle
- Disadvantage: Users not only need to analyze cross-application bean dependencies, but also need to learn the multi-application coding mode, resulting in high manual costs.
Method 2: Use the Koupleless assistant tool for easy separation!
Drag the files you want to separate into the panel according to the module directory structure. Click “Separate,” and the plugin will help you analyze and modify according to the Koupleless multi-application coding mode.
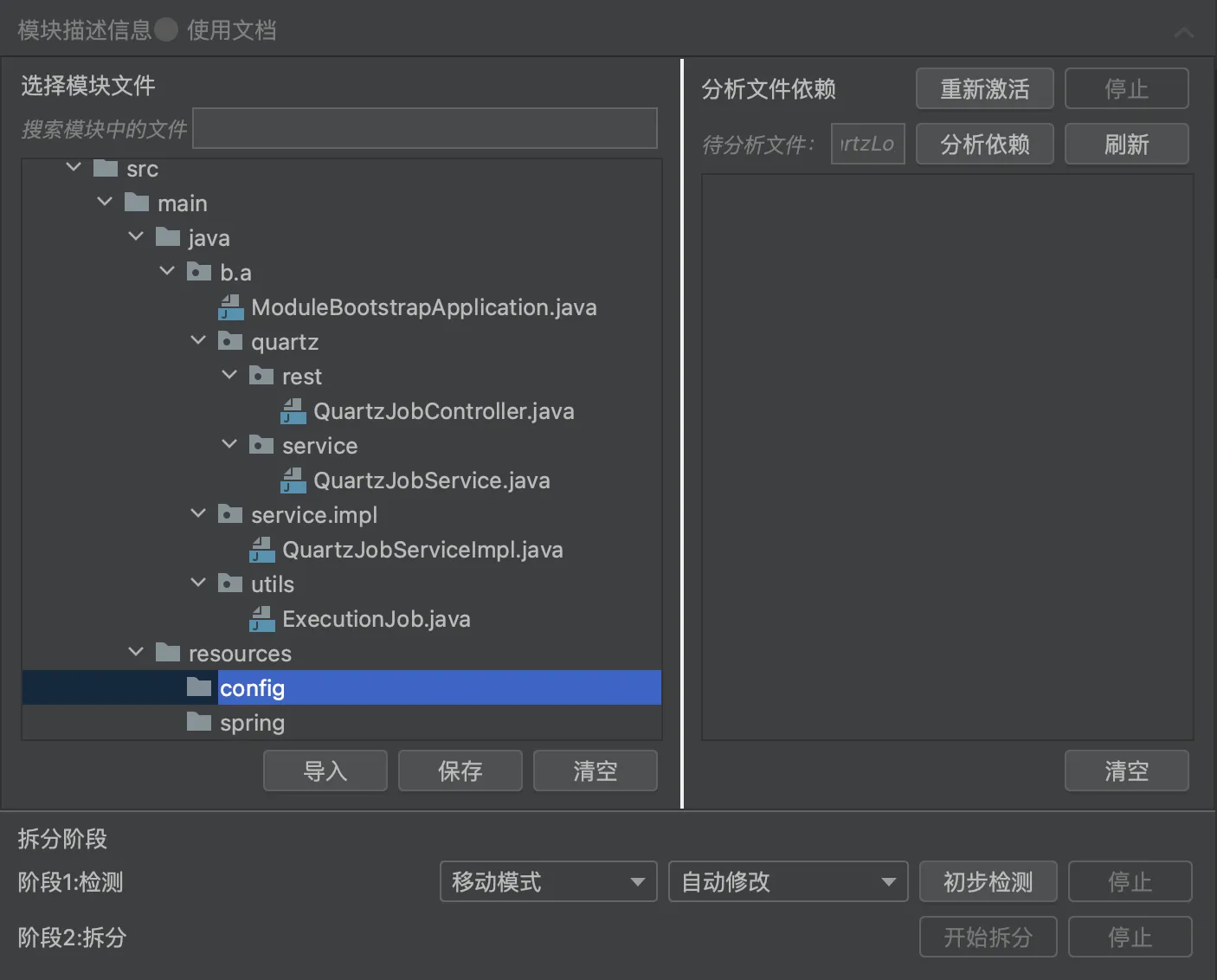
- Advantage: Intuitive, convenient interaction, and the plugin automatically modifies the way cross-application bean calls are made and some special multi-application coding modes
- Disadvantage: The plugin can only modify the code based on some multi-application coding modes, so users need to understand the capabilities of the plugin.
Technical Solution
The plugin divides the overall process into 3 stages: analysis stage, interaction stage, and automated separation stage, as shown in the following diagram:
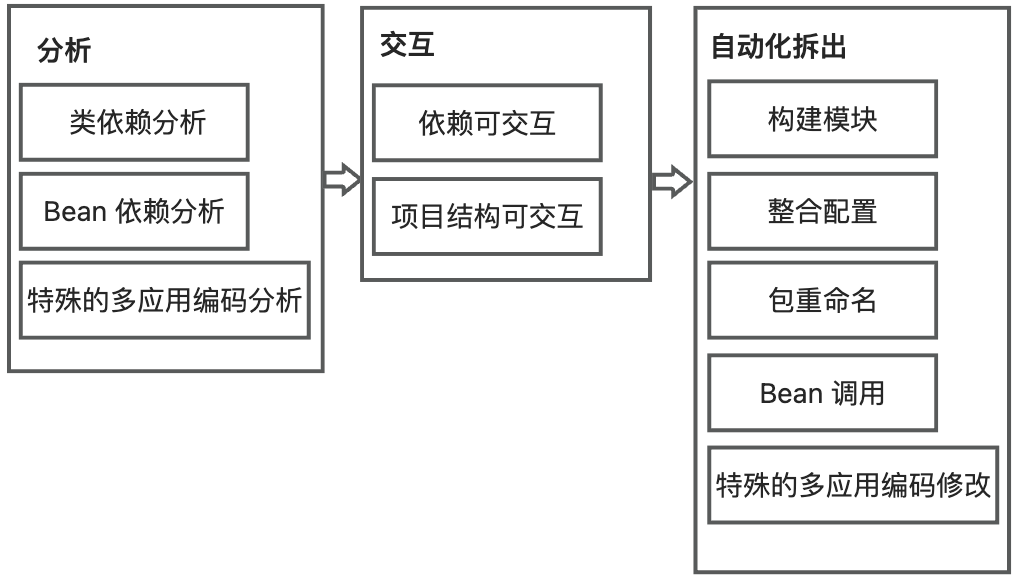
- In the analysis stage, it analyzes the dependencies in the project, including class dependencies, bean dependencies, and special multi-application coding analysis, such as MyBatis configuration dependencies.
- In the interaction stage, it visualizes the dependencies between class files and the module directory structure.
- In the automated separation stage, the plugin first builds the module and integrates the configuration, then refactors the package names according to the user’s needs, modifies the way module base bean calls are made, and modifies the code according to special multi-application coding modes, such as automatically reusing the base data source.
Next, we will briefly introduce the main technologies used in the analysis stage, interaction stage, and automated separation stage.
Analysis Phase
Plugins use JavaParser and commons-configuration2 to scan Java files and configuration files in the project.
Class Dependency Analysis
To accurately analyze the class dependency of the project, the plugin needs to fully analyze all the project classes used in a class file, that is: analyze each statement involving types in the code.
The plugin first scans all class information, then uses JavaParser to scan the code of each class, analyzes the types of project class files involved in the code, and finally records their relationships. The types of statements involved are as follows:
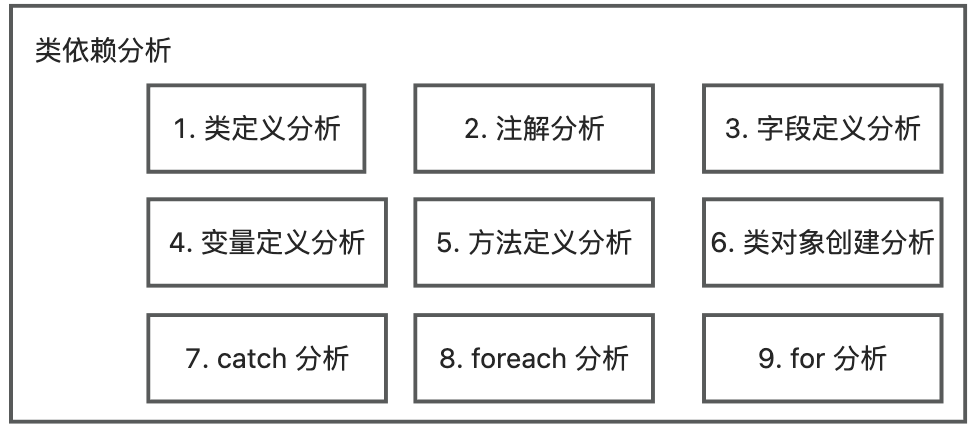
- Class definition analysis: Parsing the parent class type and implementing interface type as referenced types;
- Annotation analysis: Parsing the annotation type as referenced types;
- Field definition analysis: Parsing the field type as referenced types;
- Variable definition analysis: Parsing the variable type as referenced types;
- Method definition analysis: Parsing the return type of the method, parameter types, annotations, and thrown types as referenced types;
- Class object creation analysis: Parsing the object type of the class object creation statement as referenced types;
- Catch analysis: Parsing the object type of catch as referenced types;
- Foreach analysis: Parsing the object type of foreach as referenced types;
- For analysis: Parsing the object type of for as referenced types; To quickly parse object types, since directly using JavaParser for parsing is slow, first check if there are matching types through imports. If the match fails, then use JavaParser for parsing.
Bean Dependency Analysis
To accurately analyze the project’s bean dependency, the plugin needs to scan all the bean definitions and dependency injection methods in the project, and then analyze all the project beans that the class file depends on through static code analysis.
There are three main ways to define beans: class name annotation, method name annotation, and xml. Different ways of bean definition correspond to different bean dependency injection analysis methods, and the ultimately dependent beans are determined by the dependency injection type. The overall process is as follows:
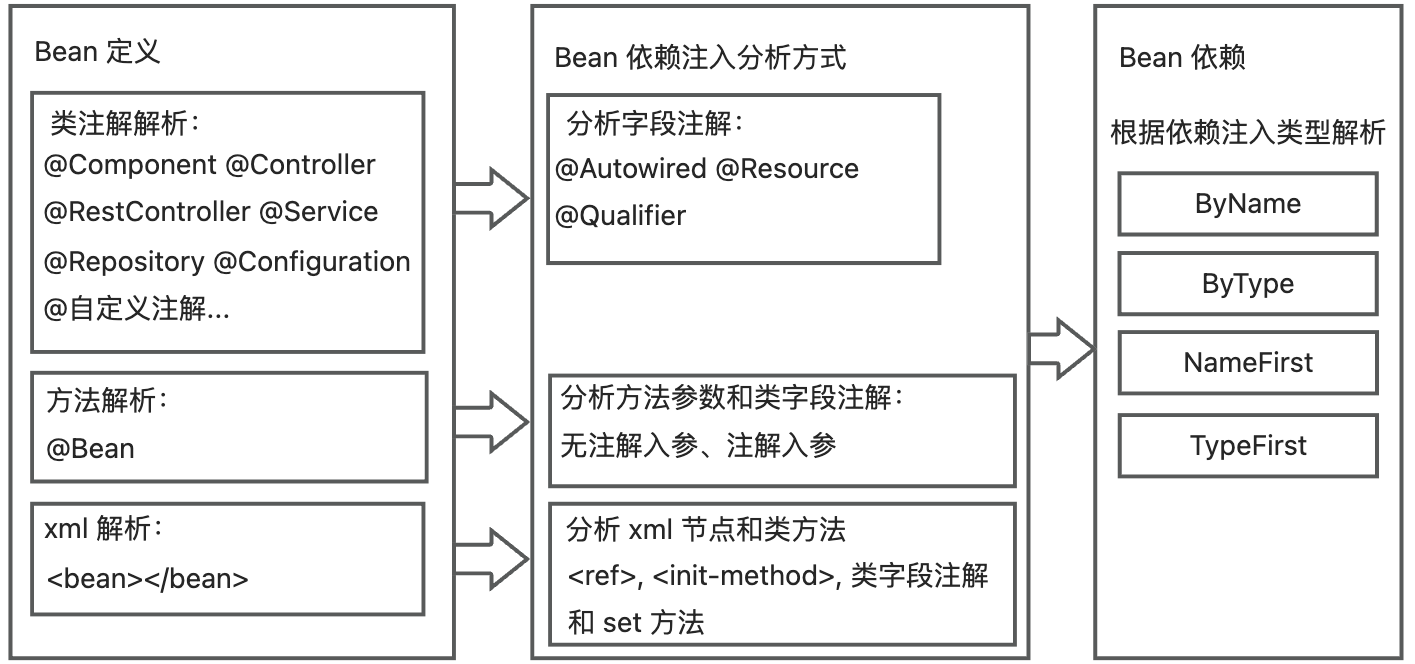
When scanning beans, the plugin parses and records bean information, dependency injection type, and dependent bean information.
- For classes defined with class annotations, it will parse the field annotations and analyze the dependency injection type and dependent bean information of the field.
- For classes defined with methods, it will parse the parameter information and analyze the dependency injection type and dependent bean information of the parameter.
- For classes defined with xml, it will analyze the dependency injection by parsing the xml and class methods:
- Parse dependencies of type byName using and
- Parse the dependency injection type and dependent bean information by parsing the fields.
- If the dependency injection type of the xml is not ’no’, then parse the dependency injection type and the corresponding dependent bean information of the set method.
- Parse dependencies of type byName using and
Finally, according to the dependency injection type, find the dependent bean information in the project’s recorded bean definitions to analyze the bean dependency relationship.
Special Multi-Application Code Analysis
Here we take the MyBatis configuration dependency analysis as an example.
When splitting out the Mapper to a module, the module needs to reuse the base data source, so the plugin needs to analyze all MyBatis configuration classes associated with the Mapper. The overall relationship between the various MyBatis configuration classes and Mapper files is connected through the MapperScanner configuration, as shown in the figure below:
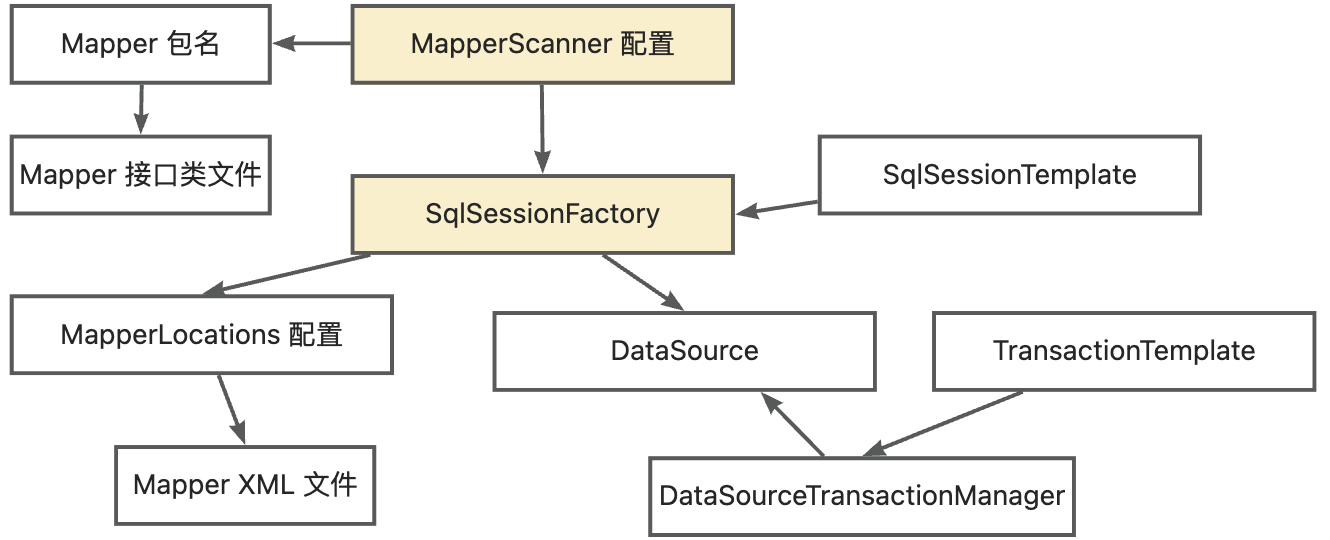
Therefore, the plugin records all Mapper class files and XML files, analyzes the associated MapperScanner, and parses all Mybatis configuration bean information associated with the MapperScanner configuration.
Interaction Phase
Here is a brief description of the implementation of dependency visualization and cross-level import.
- Visualization of dependency relationships: The plugin recursively analyzes the dependency relationships between all class files (including class dependency relationships and bean dependency relationships). Since there may be cyclic dependencies between class files, a cache is used to record all class file nodes. When recursing, the plugin prioritizes taking the dependency nodes from the cache to avoid stack overflow problems when constructing tree nodes.
- Cross-level import: Record all selected files. If folders and files within folders are selected, only import the marked files during import.
Automation Phase of Splitting
Here is a brief description of the implementation of package renaming, configuration integration, bean invocation, and special multi-application code modification (using “reusing the base data source” as an example).
- Package renaming: When the user customizes the package name, the plugin will modify the class package name and, according to the class dependency relationship, modify its import field to the new package name.
- Configuration integration: For each module of the sub-application, read all the original module configurations where the split files are located and integrate them into the new module; automatically extract bean nodes related to the sub-application from XML.
- Bean invocation: Based on the bean dependency relationship analyzed earlier, the plugin filters out the bean calls between the module and the base, and modifies the field annotations (@Autowired @Resource @Qualifier) to @AutowiredFromBase or @AutowiredFromBiz.
- Reuse of the base data source: Based on the user’s selection of Mapper files and MyBatis configuration dependency relationships, extract the MyBatis configuration information related to the Mapper. Then fill in the configuration information to the data source reuse template file and save it in the module.
Future Outlook
The above-mentioned features have been completed internally but have not been officially open-sourced. It is expected to be open-sourced in the first half of 2024. Stay tuned.
In addition, in terms of functionality, there are still more challenges to be addressed in the future: how to split the unit tests and how to verify the consistency of the split multi-application ability and single-application ability.
We welcome more interested students to pay attention to the construction of the Koupleless community together to build the Koupleless ecosystem.