用户案例
1 - 蚂蚁集团大规模 Serverless 降本增效实践
作者:刘煜、赵真灵、刘晶、代巍、孙仁恩等
蚂蚁集团业务痛点
蚂蚁集团过去 20 年经历了微服务架构飞速演进,与此同时应用数量和复杂度爆发式增长,带来了严重的企业成本和效率问题:
- 大量长尾应用 CPU 使用率不足 10%,却由于多地域高可用消耗大量机器。
- 应用一次构建+发布速度慢,平均 10 分钟,研发效率低下且无法快速弹性。
- 多人开发的应用,功能必须攒一起 “赶火车”,迭代互相阻塞,协作和交付效率低下。
- 业务 SDK 和部分框架升级对业务有较高打扰,无法做到基础设施对业务微感甚至无感。
- 业务资产难以沉淀,大中台建设成本高昂。
蚂蚁集团 Koupleless 使用场景
合并部署降成本
在企业中 “80%” 的长尾应用仅服务 “20%” 的流量,蚂蚁集团也不例外。
在蚂蚁集团存在大量长尾应用,每个长尾应用至少需要 预发布、灰度、生产 3 个环境,每个环境最少需要部署 3 个机房,每个机房又必须保持 2 台机器高可用,因此大量长尾应用 CPU 使用率不足 10%。
通过使用 Koupleless,蚂蚁集团对长尾应用进行了服务器裁撤,借助类委托隔离、资源监控、日志监控等技术,在保证稳定性的前提下,实现了多应用的合并部署,极大降低了业务的运维成本和资源成本。
此外,采用这种模式,小应用可以不走应用申请上线流程也不需要申请机器,可以直接部署到业务通用基座之上,从而帮助小流量业务实现了快速创新。
模块化研发极致提效
在蚂蚁集团,很多部门存在开发者人数较多的应用,由于人数多,导致环境抢占、联调抢占、测试资源抢占情况严重,互相阻塞,一人 Delay 多人 Delay,导致需求交付效率低下。
通过使用 Koupleless,蚂蚁集团将协作人数较多的应用,一步步重构为基座代码和不同功能的模块代码。基座代码沉淀了各种 SDK 和业务的公共接口,由专人维护,而模块代码则内聚了某一个功能领域特有的业务逻辑,可以调用本地基座接口。模块采用热部署实现了十秒级构建、发布、伸缩,同时模块开发者完全不用关心服务器和基础设施,这样普通应用便以很低的接入成本实现了 Serverless 的研发体验。
以蚂蚁集团资金业务为例,资金通过将应用拆分为一个基座与多个模块,实现了发布运维、组织协作、集群流量隔离多个维度的极致提效。
蚂蚁集团资金业务 Koupleless 架构演进和实践,详见:https://mp.weixin.qq.com/s/uN0SyzkW_elYIwi03gis-Q
通用基座屏蔽基础设施
在蚂蚁集团,各种 SDK 的升级打扰、构建发布慢是痛点问题。借助 Koupleless 通用基座模式,蚂蚁集团帮助部分应用实现了基础设施微感升级,同时应用的构建与发布速度也从 600 秒减少到了 90 秒。
在 Koupleless 通用基座模式里,基座会提前启动好,这些预启动的基座包含了各种通用中间件、二方包和三方包的 SDK。借助 Koupleless 构建插件,业务应用会被构建成 FatJar 包,在发布业务应用新版本时,调度器会选择一台没有安装模块的空基座将模块应用 FatJar 热部署到基座,装有模块的老基座服务器会异步的替换成新服务器(空基座)。
基座由专职团队负责维护和升级,对模块应用开发者来说,便享受到了基础设施无感升级和极速构建发布体验。
低成本实现高效中台
在蚂蚁集团,有不少中台类业务,典型如各个业务线的玩法、营销、公益、搜索推荐、广告投放等。通过使用 Koupleless,这些中台业务逐渐演进成了基座 + 模块的交付方式,其中基座代码沉淀了通用逻辑,也定义了一些 SPI,而模块负责实现这些 SPI,流量会从基座代码进入,调用模块的 SPI 实现。
在中台场景下,模块一般都很轻,甚至只是一个代码片段,大部分模块都能在 5 秒内发布、扩容完成,而且模块开发者完全不关心基础设施,享受到了极致的 Serverless 研发体验。
以蚂蚁集团搜索推荐业务中台为例,搜索推荐业务将公共依赖、通用逻辑、流程引擎全部下沉到基座,并且定义了一些 SPI,搜索推荐算法由各个模块开发者实现,当前搜索推荐已经接入了 1000+ 模块,平均代码发布上线不到 1 天,真正实现了代码的 “朝写夕发”。
总结与规划
Koupleless 在蚂蚁集团历经 5 年多的演进与打磨,目前已在所有业务线完成落地,支撑了全集团 1/4 的在线流量,帮助全集团实现了功能平均上线从 12 天减少到 6 天、长尾应用服务器砍半、秒级发布运维的极致降本增效结果。
未来,蚂蚁集团会更大规模推广 Koupleless 研发模式,并持续建设弹性能力,做到更极致的弹性体验和绿色低碳。同时,我们也会重点投入开源能力建设,希望和社区同学共同打造极致的模块化技术体系,为各行各业的软件创造技术价值,助力企业实现降本提效。
2 - Koupleless 助力蚂蚁搜推平台 Serverless 化演进
作者:陈铿彬
背景介绍
蚂蚁推荐平台 [Arec, Ant Recommender Platform, 后续简称 Arec] 是针对蚂蚁搜索、推荐、营销以及投放等业务特点建设的在线算法 FaaS 平台。Arec 是由支付宝通用推荐平台 [recneptune, 中文称: 海王星] 演进发展而来,目前在蚂蚁内部服务了支付宝、数金、网商、国际等多个部门的搜索、营销、投放等基于大数据和算法的业务[后面统一叫个性化业务]。
在个性化业务的特点下,算法同学的核心在于通过在线多版本能力,面向体验和效果实现和优化相关策略和算法,而不关心整体系统、环境、稳定性保障等细节,专注于数据、策略和算法以及效果提升是个性化业务取得成功的关键。而蚂蚁传统的业务开发是一套复杂、周期性的迭代式发布流,针对高频变化、实验的个性化业务来说,建设相关平台能力,提升整体效率是 Arec 2.0 在 Serverless 化的重要目标。
问题与挑战
早期的 Arec 是基于 SOFA4 [Cloud-Engine] 技术栈开发的应用系统,是基于 SOFA4 提供的动态模块化方案来实现的,采用集中部署策略,将所有业务方案代码通过 SOFA CE 动态 Bundle 方式热部署到同一个在线应用中。这种方式虽然在部署效率、切流稳定性和资源利用率上都有一定优势,但当业务场景增长到几百上千个,并且在线请求量增长到上百万 QPS 之后,业务隔离性挑战越来越大、平台维护成本越来越高、方案代码编译发布保障弱效率低、头部场景多人协同研发效率等问题不断。

- 随着蚂蚁在搜推广业务的发展,在单台机器里部署的方案和代码越来越多,业务隔离性诉求、服务稳定性差、平台维护成本高,以至于混合部署的方案难以继续推进。
- 从 Arec 整体的产品层视角出发,为了解决隔离性问题,势必需要引入独立部署机制。Arec 2.0的模型、产品设计上,目标在于平滑衔接独立部署机制以确保算法部署效率不受影响,甚至达到更优的效果;并且针对算法在线部分,Arec 1.0原本地编译流程不可控、产物不可信、导致部署和运维困难的问题,以及如何良好的解决头部场景多人协同研发以及在线多版本实验的效率问题,都极大影响了个性化业务日常研发的效率以及产品的使用体验,亟待解决。
- 经过近两年的迭代后,Arec 更是产生了 CPU 等物理资源利用率不高的问题,存在较大空间优化。
解决方式
为此,Arec 1.0 算法研发能力通过接入 Koupleless 做了化全面升级。

多集群化与模块化
通过对集中部署机制升级为多个按业务或按场景隔离部署,彻底解决了业务隔离问题和平台维护问题。
首先,我们将原来大的集群,根据业务域拆分出不同的集群,如下图的腰封集群、基金集群、底纹词集群,每个集群上按业务安装不同的模块代码包。这样解决了不同业务域的隔离和稳定性问题。

完整的研发模式升级为如下图,具备如下的优势:

- 研发过程解耦:模块和基座、模块和模块间的研发活动、运维活动完全独立,互不干扰。
- **模块极速研发:**模块非常轻量,构建 20 秒,发布仅 10 秒,极大提高了开发效率。此外,模块与应用一样,通过标准迭代发布到线上基座,迭代可以做到非常快,甚至是朝写夕发。
- **低成本业务隔离:**几分钟即可创建逻辑集群(机器分组),只部署特定模块,服务特定业务流量,和其他业务实现资源隔离、变更隔离,模块还支持秒级弹性伸缩。
- 变更部署能力全面升级:通过打通 Git 仓库,对接 ACI,我们实现 Git 仓库自动创建,算法编译部署流程自动化,代码产物从未知不可信提升 到 模块产物可信可交付,发布链路难定位 到 链路可溯源、状态有感追踪,通过编译缓存优化将日常构建时间从7分钟缩短到1分钟;并升级支持多灰度方案,和代码实验极大提升复杂场景多人协同研发效率。
模块组与流量单元
Arec 除了将代码拆分出各个不同的模块外,它还有两个问题需要解决:
- 模块里放基座SPI实现,负责一个个业务逻辑片段,但还需要多个模块搭配在一起才能组装出一个完整的业务,即需要有多个模块组合运维的能力;
- 中台业务基座一般会暴露一套统一服务来承接业务流量,但又经常有业务隔离部署的诉求,希望将机器资源划成几份,安装不同模块服务不同业务。如果对服务不做区分,就会出现业务A的请求打到业务B的机器(只部署了业务B相关模块)上,请求失败的情况:

我们将参数发布和代码发布解耦,并定义场景的模型(场景=模块组 + 流量单元),一个场景可以圈多个模块,一起打包部署,一个场景发布出的服务可以通过场景 id 作为服务 id,这样每个场景都有自己特有的一套服务,和其他场景完全独立。通过这种『拆』服务的方式,实现业务流量隔离。

即使代码相同也可以发布不同的服务,通过这种方式我们实现了 AB 测试能力。
在线多版本与代码实验
Arec 作为面向算法 FaaS:实现线上并行化的 A/B 实验能力,需要丰富整个 A/B 实验的生态,是产品的核心诉求。
1、当时的 Arec 仅能支持三个在线版本同时运行:<font style="color:rgba(25, 26, 31, 0.9);">基线 Base</font>、<font style="color:rgba(25, 26, 31, 0.9);">切流 UP</font>、<font style="color:rgba(25, 26, 31, 0.9);">压测 LT</font>。单一的开发、测试版本能力不满足多人协同研发的诉求。
- 原来针对同一个场景,多位算法、工程同学需要创建多个同名前缀的场景单独验证。例如,主场景
<font style="color:rgba(25, 26, 31, 0.9);">feeds_v1</font>,就可能同时创建了<font style="color:rgba(25, 26, 31, 0.9);">feeds_v1_01</font>,<font style="color:rgba(25, 26, 31, 0.9);">feeds_v1_02</font>,<font style="color:rgba(25, 26, 31, 0.9);">feeds_v1_03</font>,分别用于不同研发同学研发、验证与实验。
2、并且在实际多人协同研发的场景下,同一算法、业务实验,工程代码的验证往往我们需要推进到切流、甚至基线阶段,才能看到工程代码对于算法的效果,原本基于原有的纯参数 A/B 实验能力,难以支持代码实验的诉求;
方案
在线多版本
在产品优化中,我们明确支持多个版本在线同时运行,并且可以支持指定版本和白名单测试的能力,让一个场景能同时支持多位算法、工程同学在线研发、验证和实验。
【2.0 产品设计】针对多版本问题,我们基于原来三个版本的类型,加入了开发版本类型,和验证阶段的概念
- 验证阶段:支持多个开发版本的代码同时运行在线,并且支持指定版本和白名单指定验证的能力;
- 切流阶段:保持原1.0的产品设计,用以可发布版本的线上端到端流量的验证;
- 基线阶段:保持原1.0的产品设计,用以线上完成功能、实验验证的推全版本;
代码实验
基于多版本在线运行,以及指定版本验证的能力下,将在线运行的代码A [基线CTR=1.0] 进行A/B实验,以此获取到具体的算法产出结果,用于判断代码B [实验组] 是否会大面积影响了算法的指标[CTR=0.5/1.5],用于决策代码B [重构、大规模改动] 是否可以进行推全发布。
- 为了不影响业务实验的逻辑,我们将业务实验的流量单元和代码实验的流量单元独立出来,代码实验的决策优先级高于业务实验,待代码版本确认后,再继续执行业务实验的参数合并逻辑;
- 【代码实验】代码实验的流量单元决策当前 PV 所执行的版本,通过达尔文的参数实验能力,在 A/B 实验参数中决策出当前流量所命中的代码版本,例如 Version=重构。而基于我们可指定版本验证的能力下,Version=重构的流量将直接命中重构代码的逻辑,并且返回相关的实验指标,反馈到实验桶中,用于基线版本和重构版本之间各类指标的体现。

Serverless 调度与弹性伸缩
随着支付宝业务的快速发展,包括但不限于首页、Tab3、生活管家、医疗助理等,Arec 平台截止 2024-07 目前使用和管理几十万核的 CPU 资源,承载超过 几百万 QPS 的峰值流量。在降本增效的背景下,结合多方面的目标和长期问题的暴露,如何建设并优化一套有效的、高效的、低成本的资源管理和优化能力,成为 Arec 当前阶段亟需解决的问题。
从解决利用率问题的角度切入,应用级别的粒度确实非常大,并且需要求整体最优解的难度就更难。因此,我们通过拆解问题单位,用子问题更优解反推问题更优解的方式,一步步拆分和验证各个问题的解决方案,并且取得对应的结果。
我们将应用级的利用率提升拆分到业务集群粒度的利用率提升;再将业务集群天级利用率提升拆分到业务集群小时级利用率提升,从而反向一环环的影响整体结论。
我们通过将资源分配的调度粒度更细化到模块粒度,也是我们当前正在做的优化方式。通过提供预热集群,业务集群和模块的扩容,将跳过基座冷启动阶段,转而直接进行模块等代码片段的安装,可以让弹性的速度更快,资源部署的密度更高。
基于非对称部署的场景混部提升平台资源利用率保障场景资源诉求
Arec 承接了上千个活跃场景,支撑的服务器集群达到了几十万核级别,随着业务接入越来越多,对机器的需求量越来越大。当集群达到一定的规模之后那机器成本是必须要考虑的,不可能无限制的扩充机器。如何在资源有限的情况下支撑更多的业务?必然要做的就是提升资源利用率。
针对资源利用率的提升云原生领域已经有成熟的思路,即做资源调度。常见的产品如开源的 K8S 。
为什么资源调度能够提升资源利用率?简单来讲,调度就是通过各种技术手段提升机器部署密度把机器资源充分使用上。为什么已经有基于 K8S 的成熟产品了还需要做 Serverless 资源调度?
两者面临的调度场景是不同的。
- K8S 调度的粒度是 Pod,Pod 与应用的比例是 1:1 ,他解决的问题是如何把各种规格诉求的应用部署到按照各种规格虚拟化后的 Pod 里。比如一台物理机有 32C,可以把他虚拟化为一个 16C 和2个 8C 的 Pod,然后就可以把一个规则为 16C32G 的应用和两个 8C16G规格的应用部署到该物理机上。
- 而 Serverless 调度的粒度是模块,虽然 Arec 是一个应用,可以在上面安装多个模块。模块的启动速度更快,与传统 K8S Pod 的启动速度有很大优势;模块占用资源小,可以在模块这层将资源部署密度做的更高。
那么 Serverless 做模块资源调度要做什么?与 K8S 类似,要做两大能力:1、场景混部 2、非对称部署
场景混部
Arec 上运行着上千个场景,而且场景各异,有的只有几 qps,有的却有几万 qps。考虑到蚂蚁的应用部署架构有8个 zone,而每个 zone 为了避免单点至少需要2台机器,那每个场景至少需要 82=16 台机器。头部场景流量大,独立部署可以将资源充分利用起来,但是长尾场景如果都按照独占计算的话,假如长尾场景有 1000 个,那至少需要 161000 = 16000 台机器,这个规模是惊人的,无法让人接受的,通过混部可以将资源利用起来,实际运行中 1000 台机器就将长尾业务支撑起来,直接可节省 1w+ 台机器。
非对称部署

如上图(基于 Koupleless 模块化架构),是对称部署还是非对称部署是针对一组机器来讲的。如果一组机器上部署的模块(如果是 K8S 对应着一组物理机上都部署着相同的 Pod ),那我们称之为对称部署。相反的,如果一组机器中,有的机器部署着3个模块(对应与 K8S 就是3个 Pod),而另一个部署着5个模块,或者说有的机器部署着 A、B ,有的机器部署的 C、D,那我们就称之为非对称部署。
资源隔离其实是对虚拟化后的容器做了个规格约束,可以类比于普通应用的规格。当做完资源隔离之后其实我们就能够对 Arec 的场景设置规格,比如一个小的场景我给他约束规格为 2C4G,稍大一点的约束为 4C8G,再大一点的约束为 8C16G,这样就能够比较准确的评估出场景所需要的资源,可以称之为场景副本数,也就是虚拟化后的容器部署个数。不同的场景流量不同,逻辑不同所需要的副本数也就不同。Arec 整体集群的机器数是一定的,而不同的场景需要的副本数不同,那就无法做到所有的场景都平铺到集群的所有机器上,因此 Arec 需要做非对称部署。

该非对称部署方案满足了 Arec 的两个诉求
1、亲和与非亲和部署
- 类比 K8S ,消耗资源高的场景容器不能部署到同一台 Pod 上,避免由于容器隔离不彻底导致的两个场景都受影响。
- 存在场景互调的场景尽可能部署到同一台 Pod 上,由于推荐场景 tr 请求的 request 和 response 都很大,这样可以减少序列化和非序列化消耗。
2、提高部署密度提升资源利用率
- 把资源进一步细化分隔,从而把碎片化的资源利用起来。举个例子:一个场景有隔离诉求,按照蚂蚁 K8S 现在的调度,蚂蚁现在有 8 个 zone,那流量再小也要最少 16 台机器,但是对于流量小的业务 16 台根本无法将资源充分利用起来。
多目标弹性决策降低弹性对业务的影响
在执行弹性的过程中只有准确的评估出服务的运行情况才能够更好的做到弹的稳。
Arec 上运行着上千个异构的场景,各个场景的逻辑不同,有 io 密集型的,有 cpu 密集型的。有的场景 cpu 达到了 80% 服务成功率还能保持在 99%,而有的场景可能 cpu 只有 40% 但是已经出现大量超时和抖动了。怎么样才能够比较准确的评估出场景的运行情况是决定弹的是否稳定的关键。
我们认为在对场景能否能够正常运行的评估中除了 cpu、load 等基础指标,再观察场景的超时情况、异常情况以及降级熔断发生的情况能够比较真实的反应运行情况。基于此,Arec 建设了多目标评估的弹性。目前 Arec 的评估指标包括:
- 超时
- 异常
- 降级
- 限流
- 熔断
- cpu 利用率
在弹性缩容的过程中通过多批次,多目标的评估执行,保证弹性的安全平稳。

弹性算法
Arec 基于 Metrics 提供了基于过往峰值的计算决策 Base Max、基于过往均值权重的计算决策 Base Weight,联合 OPTK 的时序预测算法,提供了不同的弹性决策算法能力。
而 OPTK 是一个主要针对互联网、金融等产业应用中的多种垂直领域超大规模优化问题,蚂蚁自研的一套高效分布式数学规划求解器套件。OPTK 从【领域问题建模与抽象】【求解算子和算法】及【分布式引擎】三个方面提供了全方位的统一求解套件。
弹性配置化
在收获到上述的成本优化结论和实践后,Arec将业务集群日常的运维委托交付到 SRE 手中,减轻平台日常的运维成本,并且提升 SRE 可自主化运维的可控性。针对不同集群可以开启不同的弹性算法,例如:时序预测、历史峰值决策、算比决策等。
因此 Arec 定义了一套声明式设计,以及可调整的配置内容。API 与 Config First,减少 UI 开发成本和链路健壮性。未来还将持续扩展更丰富的配置策略,支持不同的诉求:按时、按天、不同 Metrics 决策、独立 Zone、全量 Zone 等;


阶段结果
当前所有 Arec 的算法与流量都运行在基于 Koupleless 建设的 Serverless 能力之上,除了隔离和业务稳定性得到保障外,支持了日均 1000+ 的工程师协同研发,个性化场景分钟级上线,日均 CPU 利用率从原来 17% 提升到 27%。
未来规划
- 极致的搜推 Serverless 的生态建设,包括但不仅限于:研发、运维、高可用、弹性、实验、特征数据等;
- 绿色计算的优化与生态能力共建,包括但不仅限于:决策算法、弹性能力;
3 - 大象转身:支付宝资金技术 Serverless 提效总结
作者:代巍、何鑫铭
–支付宝资金技术交付提效之路系列之一
1 前言
本文是支付宝资金技术团队在《大象转身-支付宝资金技术交付提效之路》系列总结之一。如果你正在负责一个所支撑的业务面临从平台,到场景化创新的发展阶段,希望通过提升交付效率来提升技术团队的竞争力和团队研发幸福感, 那么这篇文章也许对你有收获:
1)Serverless的技术理念是什么?对业务研发有什么借鉴意义?
2)如何基于Serverless驱动研发模式的升级,设计一个能让场景化创新快起来的技术架构,提升全局研发效率?
文章较长,建议收藏和保存
本篇作者:代巍(呆莫)、何鑫铭(歆明)
为什么写这篇文章
我们做了近两年的Serverless研发模式的探索和落地,目前该模式已经承接了大部分资金业务的场景,平台也已经进入推广期,有20+团队经过SOFAServerless技术团队的介绍找到我们。未接入SOFAServerless想从业务视角寻求架构选型依据和应用架构设计,已接入SOFAServerless的同学来寻找基座治理经验。因此决定写一篇文章,将我们的架构选型、设计和落地经验做一次完整的总结。
2 我们遇到的问题
我们的问题:随着场景创新增多,SOFA应用变臃肿、团队研发人数变多导致研发和运维难度升高,阻碍了业务创新的交付效率,系统需要做重构。
2.1 简单说说背景
资金在这两年时间,肩负了很多业务创新,寻找业务增量的目标。增量时代的创新是残酷的,成功的明星产品背后,是无数次的失败 (这三年间,技术支撑了15+个创新产品的建设,包括小程序、行业解决方案)。而对于支付团队转型做创新,也面临巨大挑战,动辄1-2个月起的研发交付周期,那会儿,使得技术团队被按在地上摩擦,各种问题接踵而来。

蚂蚁集团CTO苗人凤曾经说过,创新是九死一生,技术就是要帮助业务降低机会成本。
我们逐渐意识到业务创新的快速发展,一定离不开业务快速交付的新型技术研发模式。如果我们还是沿用平台化的架构思路,在一个庞大的资金平台上写一堆创新场景的代码,在完成业务需求的同时还要思考如何抽象、如何保障增量的代码不影响平台稳定性,那一定快不了。
2021年,我们成立“资金场景创新提效项目”,试图通过平台架构升级、研发模式升级解决场景创新效率问题。
2.2 问题定义:资金场景应用变成巨石应用带来一系列问题
试图代入一下案例:
如果有那么5个创新业务迭代在同一个应用发布窗口进行推进会存在各种各样导致延期的原因:
A业务验证的delay了2天,那么5个迭代都要延后两天;
B业务升级了中间件版本,那整个应用的业务都面临回归成本一样要延后整个发布期;
C业务想要在预发搭个车微调一些代码,但是由于动作慢没能成功验证,导致污染了主干,进而耽误了整体;
……
在应用架构层面,资金部门早期孵化出的一个“大资金场景层应用”——fundapplication,fundapplication在研发协作方面,从一开始的几个同学,到几个业务团队,几十个研发同学,都在一个应用系统上研发,通过多个bundle区分不同业务,公共的bundle沉淀通用能力和研发工具(类似于之前的mng系统),如下图。

这种架构设计,遇到大量的彼此没有复用的业务创新需求时,逐步沦为了巨石应用(如下图):

1)研发运维效率低:作为入口系统,mgw接口无法在本地开发自测,改动任何代码必须发布到联调环境。发布一次需要10分钟以上,还要忍受环境不稳定因素带来的额外时间花费。
2)业务迭代抢占,协同成本高:系统作为创新应用系统,有10+个创新产品,30+个正式员工和外包员工也在这个系统上做研发迭代,火车式发布迭代痛点明显——一人晚点,全体延期。
3)研发时隔离效率低:30+研发同学(含外包)在一个系统内研发,经过不到1年的时间,我们的系统就变成10+个bundle、2w+个java文件(全站均值4000)的体量了,因为各种业务的各种依赖的增加,系统启动一次需要15分钟。随着创新场景增多会变得更加糟糕,而且很多代码没有办法随着业务的下线而删除。
4)运行时不隔离:目前我们没有对不同的业务区分不同的机房,业务吃大锅饭,难以做到按产品的资源和稳定性保障。
如果你的应用也存在上述问题,对业务创新的交付效率产生了一定的影响,那可以继续参考第3、4章我们的架构选型和关键设计。
3 应用架构的选型
当前蚂蚁基于SOFABoot的应用架构,在规模化创新场景研发的交付效率、分工协作模式上存在局限性。从行业的发展趋势分析,云原生等新技术引领的“集装箱”架构模式,有利于促进规模化的生产效率和分工协作方式。借助蚂蚁SOFAServerless的孵化,我们决定作为种子用户,使用Serverless中BaaS+FaaS的理念,重塑创新场景研发的研发模式。
3.1 微服务应用架构的局限性
大应用创新的模式,是在一个应用系统中按照不同bundle来隔离创新应用,可复用的代码可能是放到一个公共的bundle中。优点当然是复用效率高,运维统一,缺点主要是协作效率、隔离成本和研发效率。大应用变成巨石应用如何解决?这个我们很容易就想到使用分治的思路,将一个大应用拆成多个应用,通过RPC来互相调用。
在蚂蚁当前体系下,微服务系统的0-1成本、后续运维成本、硬件机器成本仍然会是一个不小的开销,创新试错还是快不起来。且后端业务创新具有巨大的不确定性,如果因为业务没量了变成长尾系统下线的成本也很高;在性能方面,多个系统间通用能力的调用,会使全链路的调用耗时增加,在业务上不可接受。所以有没有一种技术,可以让业务既能够隔离,又能够降低隔离带来的负向影响:运维成本、能力复用效率、性能?
3.2 行业技术架构的发展趋势
一部分做架构的同学喜欢用“架构隐喻”来介绍架构的理念。近几年容器化、云原生、Serverless等新技术层出不穷,作为架构师需要在对新技术保持敏感的同时,能够有一双洞察架构本质的眼睛。
这些底层新技术的出现,本质上是通过抽象定义“集装箱”的方式,规范了构建、部署、运行、运维标准,提升了软件的生产效率。大家可以感受一下这些技术底层理念的相通之处:
①docker通过定义容器“集装箱”提升传统虚拟机、基础设施软件构建、运维效率
②K8S进一步抽象万物皆可定义为CRD(自定义资源)提升“集装箱”的部署、运维效率
③中间件Mesh化将“集装箱”理念应用到中间件近端,将中间件近端与业务代码剥离解耦
④BaaS、FaaS等Serverless技术,将“集装箱”理念范围进一步扩大到可复用的“业务领域插件”
可以这么说,集装箱改变世界航运效率,计算机软件行业的docker、k8s们通过“集装箱”的架构理念改变了基础软件生产效率。而随着serverless的兴起,“集装箱”的架构理念将会自底向上地,重塑对软件交付效率重度依赖的互联网、金融等行业。

我们来看下,集装箱的理念对我们业务研发的启示。
过去,业务研发需要关注独立的业务应用,既需要关注业务代码、中间件代码等代码信息,又需要关注java进程、CPU、内存等运维信息,随着这两年蚂蚁mosn等servicemesh基础设施的出现,将中间件代码做了拆分和代托管运维,解放了业务研发的部分精力,不需要再经常性的忍受中间件近端升级带来的迭代变更。
再进一步的,我们开一个脑洞,能否将SOFA运行容器的jvm托管出去?甚至更进一步的,一些通用的业务流程能力、日志和框架等能力托管出去呢?这样创新业务研发的关注点,可以从一个独立的java应用,进一步聚焦到java业务功能性代码,而将非功能性的java容器、日志、框架的构建、部署、运行、运维等工作交给非业务研发同学来负责。带着这样的脑洞,我们来了解下Serverless的行业概念并分析架构的可能性。
3.3 理解Serverless的设计理念
Serverless****的行业概念解释
先带大家看一下行业中对于Serverless的解释。
第一个层面是站在运维、和云计算厂商的视角:将Serverless拆开看,Serverless = Server(服务端) + less(较少关心),组合起来便是“较少关心服务端”。这里的“服务端”是指对服务运行资源的运维。因此,Serverless还有另一种解释是服务端免运维,即NoOps。概念方面Serverless是对运维体系的一个极端抽象。在这种架构中,我们并不看重运行一个函数需要多少 CPU 或 RAM 或任何其他资源,而是更看重运行函数所需的时间,我们也只为这些函数的运行时间付费。
第二个层面是站在应用开发的视角:在Serverless中,“计算资源”这个概念,除了是作为服务器出现之外也作为服务出现。与传统架构的不同之处在于,它可以完全由第三方管理,由事件触发,无状态的(Stateless)暂存(可能只存在于一次调用的过程中)在计算容器内。我们基于这些“服务计算资源”,就可以更容易的搭建出一个应用,比如你可以把账户管理、交易管理、营销管理等服务完全托管给这些第三方“服务计算资源”。
一个Serverless化的应用,就是指大量依赖第三方服务(也叫做后端即服务,即“BaaS”)或暂存容器中运行的自定义代码(函数即服务,即“FaaS”)的应用程序。这是一种架构思想,类似微服务一样,不过微服务这种思想架构,目前已经有成熟的框架来支撑,比如dubbo、spring cloud等,但是Serverless架构目前还没有一个框架来支撑,也因此说Serverless技术实际上是一组技术的集合和一种站在服务视角上的应用设计理念。
按照 CNCF(Cloud Native Computing Foundation 云原生技术基金会)对Serverless的定义,Serverless 架构应该是采用 FaaS(函数即服务)和 BaaS(后端服务)服务来解决问题的一种设计。

它的整体架构如上图所示,包含两种模式和形态:
•BaaS(Backend as a Service):后端即服务。具备高可用&弹性,且免运维的后端服务。可以是符合以上特点的对象存储服务、数据库服务、身份验证服务等等。从狭义上讲,BaaS是为FaaS提供服务支撑。
• FaaS(Function as a Service):函数即服务。提供流程化的服务,将客户对流程的扩展采用一定范式的抽象发布成函数实例,外部可通过触发器使用该服务。FaaS支持动态扩缩容。以http请求为例,当请求量很大时FaaS函数会自动扩容多实例同时运行;在http请求降低时自动缩容;无流量时还可以缩容到0实例。
Serverless的设计理念抽象成应用架构
理解了Serverless的行业概念解释,我们带着这个理念再回顾上面3.2的第二张图。借助集装箱的架构思想,Serverless理念无非是站在云服务视角,将一个应用程序按照集装箱的方式、拆分成不同的“image”,并进行可标准化的构建BUILD、SHIP部署、RUN运行,以提升规模化生产效率。
如下图所示,可拆分成使用方、服务方,服务方以baas独立服务、faas独立流程模版的形式将业务代码抽象成“image”(镜像),使用方将简单的业务代码或者基于faas扩展的函数也打包成“image”,大家将image作为基本单元。我们知道docker是有一套容器运行环境来支持image镜像的构建、部署和运行的,类比的Serverless也需要有这样一套基本容器环境。这套容器环境,需要对镜像的构建、部署和运行做实现。

Java应用的Serverless运行环境实现
2021年,我们看到蚂蚁内部有SOFA-Ark这样的模块化框架,提供同jvm内多个模块分离研发、部署、运行的研发框架。我们经过POC技术验证认为,基于SOFA-Ark定义的ark模块、基座概念和SOFA-Ark提供的模块构建、部署和运行机制(模块粒度代码拆分、模块热部署、同一jvm运行),是初步符合Serverless的设计理念的。
同时我们看到,围绕这套框架的配套运维系统、产品系统也开始初见雏形,经过架构决策后,非常笃定这个架构演进方向,决定作为种子用户加入初创团队,作为SOFAServerless的业务样板间进行孵化。

4 关键架构设计
如何重构我们巨石应用?我们借助SOFAServerless对模块、基座的理念,对巨石应用fundapplication进行了拆分、托管,将业务的关注点从应用聚焦为“轻应用”,将公共模块、基座采用了类baas和faas的全托管模式。
4.1 新模式的探索
基于SOFAServerless,我们探索了“轻应用架构范式”,通过sofa-ark框架将应用程序拆分为基座、业务模块、公共模块这三种不同的“image”。
这种做法的好处,一方面可复用的业务能力、日志等技术服务能力抽象为公共模块,由能力的供给方托管,可快速实现规模化复用;另一方面模块和基座的边界比较清楚,基座不承载业务逻辑,只承载java运行时容器、二方jar包管理、蚂蚁全套中间件集成等基础运行能力,可完全由非业务研发同学托管,真正实现业务模块研发同学的关注点聚焦。业务研发同学只需要关注业务模块,把所有业务高频变更的代码都放在业务模块,减少迭代竞争。

4.2 Serverless无服务器化带来的轻运维方式
因Serverless无服务器化技术的的核心原理,能够带来一些显著的变化。比如热部署的技术、场景化服务动态发布的技术、无服务器技术(共享基座运行时),可以让模块快起来、并能够做到隔离、“免”运维。
形成了一种新的研发模式,基座这种低频变更可以对标传统的经典SOFA体系;模块高频变更可以走到轻研发模式,同时有了容器弹性腾挪的能力加持,也一定程度上做到了流量隔离和弹性伸缩(见下图)。
- 研发过程独立,互不影响,4个业务方,20+模块独立迭代敏捷变更
- 快速划分并创建集群,隔离部署业务,业务集群间模块支持弹性伸缩,方便快速弹出解决运维的问题。
- 基座统一托管代运维,贴合人性,削减为轻运维成本极低

试图想象这个案例,大家研发中可能经常提交部署后发现一个if else判断逻辑写反,需要commit修复代码+重新部署。
SOFA应用:10min的成本,研发同学的直觉肯定是先去干别的,过一会儿再回过头来再去做验证工作,我相信同学很难有这个时间节点把握,不太可能定一个10min的闹钟提醒自己回来,所以整体花费可能远大于10min
SOFAServerless模块:30s的成本,研发同学一般会认为可能可以等一等,马上就能投入验证和自测工作,所以整体是一个“延续性”的过程,可以一鼓作气把整个研发自测做完。
4.3 Serverless应用架构带来的复用提效
SOFAServerless代表了一种应用设计范式,有基座抽象、模块内聚的特性,通过基座这种复用模式可以提供开箱即用的方便模块快速集成的技术能力,让我们可以在基座上有所发挥。
基座可以成为一个“BaaS化的应用服务市场”,我们可以把一些例如工具、脚手架等能力内置到模块上;提供一些技术产品让模块可以选装快速集成;引入一些通用业务能力委托给基座加载,减少模块的集成和运维层面的负担。我们之所以把他比作应用服务市场,是因为我们仍然认为模块应该被松绑,基座提供的能力是可以按需选购,且轻量使用的。
从单应用研发,到随意从市场选购,复用可以很敏捷。通过Baas化的市场,已内置、选用、托管等方式把复用成本打到很低。

直击心灵,研发时我们是不是有一些事项是重复性工作、甚至非常想偷懒
比如研发过程中做一个模块级应用,势必需要一些通用的切面、工具集、方法执行模板、基础模型类……有些甚至还需要自己设计一把,还可能需要集成参数中心等较重的配置平台,如果已经内置好了研发体验会非常舒适。
得益于模块和基座在运行时共享一个Java进程,所以我们可以非常方便的为模块提供无感的集成体验。
5 基座owner的自我修养
如果你已经决定选型或者已经使用SOFAServerless了,可以继续查看本章。本章将资金近2年Serverless的落地经验,浓缩成基座owner的自我修养。
在新的应用架构下,将原先的系统owner拆分成基座owner和业务模块owner两类角色。业务的owner、基座的owner存在上下游服务和供需关系,基座owner要服务好模块客户、解决模块客户问题,让业务模块开发者能够享受到基座建设的红利,进而更快速支撑业务增长。
以前的系统owner,只需要关心单应用的稳定性、容量评估、演练、应用的中间件升级等。但是当我们做了基座和模块的拆分之后,也带来了一些新的问题。因为新的研发模式,引入了热部署框架、场景服务托管框架、跨模块通讯等新的研发框架需要去理解,相比原先的系统owner,对基座owner也有了一些新的角色要求。我们将资金这两年基座owner走过的路和经验总结为4个代名词——效能官、技术布道师、应用架构师、治理同行者。

5.1 业务模块研发提效的效能官
面相场景交付提效,实际上对基座管理员有更高的要求,这个变化的来源于模块研发者需要一整套敏捷研发、轻运维、高质量保证的交付模式,这就需要让基座提供更多的能力、更便捷的运维能力、更好的统一防控。新的应用架构下,我们愿景是场景的研发者可以只关心场景服务,一切与场景模块研发提效相关的命题都可以由基座管理员的去承担托管。
基于交付提效的目标,我们需要下探一下,需要一个可刻画、可跟踪、可优化的全链路研发和协作机制

研发洞察体系
说“提效”并不是盲目拍一个目标,而是一个有数据指标刻画以及有追踪低效的手段,所以首先就需要定义研发效能的度量。因此,我们解剖了交付过程,然后通过“湖水岩石效应”的方法论,来圈定我们改进的方向。因此在2022年我们和研发效能团队一起探索了资金业务全链路研发洞察体系,发现了很多的效能短板,我们也基于指标的牵引,完成了很多针对性成片的建设。
 | > 我们把软件开发整个交付周期比作湖的水位,那所有问题都掩藏于水面下方,可能全量问题都看不到,或者只是感觉可能有问题但没那么严重。如果我们想要削减交付周期(降低水位),那水面下的“岩石”就逐渐暴露出来,如需求复杂度的问题、多人协作成本的问题、环境稳定性的问题、研发的理解成本的问题、研发复用的问题、质量回归的问题、跨团队组织沟通的问题…… |
|---|
研发提效
基于SOFAServerless这样一种新的应用架构,首先,对于一个小白用户来说,一定是有一些理解成本的,例如对中间件的理解、对框架的理解。其次,在新研发模式的研发过程中,也有一些“过程成本”,例如代码库从0-1的成本、代码调试的成本、非功能性考量的成本……
由于引入了热部署框架,就需要研发同学理解运维单元、服务发现的生命周期;
由于框架层面深度使用了spring上下文、跨classloader等机制,需要对研发同学的基本功有一定要求;
由于中间件、框架演进(中间件演进、Serverless框架演进、基座能力封装演进)带来的编程界面差异,需要研发同学掌握一些编程技巧和问题规避。
我们也一直在尝试削减Serverless引入的新要素带来的负向效能影响。
在系分阶段:我们就非常注重提高同学们对所需技术能力和服务可复用性的认识,提供了成熟度对照表、复用对照分母等,告别“手口相传”这样的低效方式。
在研发阶段:研发的“过程成本”层面,我们一开始面临环境可用率很差、常调飞的问题,通过环境中心上云、迁移九州等一些代际升级解决。后来我们发现了模块初始化建设提效、服务抽象复用的诉求,也做了通用脚手架内置,框架集成等针对性的建设;研发的“理解成本”层面,起初模块研发者使用中间件的编程方式跟之前有一定差异,我们作为客户推动SOFAServerless研发框架的研发体验升级,“将复杂留给自己,将简单留给模块研发者”,做了多个版本的框架升级,最终达到常用中间件的原生编程界面的体验。
质量风险提效
目前处于在SOFAServerless质量工具配套适配过程态,我们也在抓紧基座防控体系的建设,确保风险可控,不出大问题。 在我们面临一些大版本升级、大项目上线的过程中,很依赖一线质量同学的人肉回归。需要把这部分成本削减下来。所以需要各个阶段的质量工具配套的适配,第一阶段是预期拉平SOFA应用,即能够支持SOFABoot的质量工具也要能适配SOFAServerless,主要包括线下研发阶段的的flytest测试框架集成、预发阶段的仿真回放比、灰度阶段的灰度引流。第二阶段是探索出和Serverless要素适配的质量能力,比如智能化回放、动态弹性伸缩、智能变更防御等。
5.2 团队Serverless研发模式的技术布道师
Serverless研发模式对一线研发者的编程方式、服务路由方式、基础运维方式都有一定的变化,这些变化会让一线同学经历“不适应”阶段,基座owner需要具备能力和心理素质,来做技术布道的第一责任人,帮助大家熟悉这些变化。
编程界面差异

SOFA应用:都是基于SOFA中间件体系进行研发,包括半模块化、spring上下文、中间件starter等能力都是蚂蚁SOFA STACK原生的编程界面。
SOFAServerless应用:场景化服务的动态发布、中间件的使用、通讯路由……等,我们经历过linglongsdk或者基座封装的方式,这个阶段很多服务发布、服务通讯的编程界面都是非标的,对研发者来说还是有一些理解成本的。后续演进为SOFA-Trigger框架统一做封装和管理,各类中间件如果按照SOFA-Trigger的标准来适配,就能够正常在SOFA-Ark框架下运转。所以在升级了SOFA-Trigger的基座上,模块可以原生使用SOFA STACK编程界面
举例说明一下,假如我们研发过程中需要使用事务型消息
在SOFA应用下:我们肯定是使用msgbroker的原生编程界面去实现消息的发送和监听、以及事务的回查;
在linglongsdk环境下:SOFAServerless的linglongsdk并不能提供事务消息的能力,我们可能需要通过基座做一层代理和消息中心交互。通过基座和模块的通讯去间接实现模块的事务消息监听、发送、回查;
在SOFA-Trigger环境下:SOFA-Trigger框架已经能够完全代理消息中间件,做到协助消息中间件在Serverless运行时和注册中心进行服务发布、注销的交互。让用户可以使用消息中心SOFA的编程注解、配置。
场景化路由和通讯隔离

SOFAServerless具有多AIG、多场景隔离的特性,AIG是一个网络层面的切分概念,AIG之间的机器、域名、服务都是隔离的;场景是一个服务发布管理层面的概念,场景具有动态发布服务的能力,一个模块可以在多个场景内发布出不同服务实现业务隔离。
我们也做了多业务AIG的隔离、多业务场景的拆分,拆出一个通用AIG用作多场景混布,主要承载一些低流量、新孵化的业务。一些比较高保、量级大的场景则独占AIG。例如C业务场景几乎是独享AIG,C场景和B场景在公共集群上混布。所以整体上我们是一种多AIG非对等部署的部署形态。当然在这个形态下我们也需要应对服务治理相关的问题。
- 在各类型的中间件、流量入口、路由,都有了一些特殊的要点,比如SOFA-Trigger框架下,各个rpc服务、消息的场景ID隔离和路由。
- 涉及到跨场景、跨AIG的特殊通讯方式。比如一些公共服务,在同AIG内要做到jvm级别的服务通讯,也要考虑跨AIG通讯的情况。
更细运维粒度和生命周期

代码变更的过程、以及运维的过程,最小的研发、运维单元由原来的应用级别缩减到场景级别。这样研发和运维关注点就可以细到只关注自身的服务,尽可能的减少对部署单元、服务器的关注。
而在单机视角来看,每台服务器只有在基座启动时会受到耗时长的影响,模块的拆装生命周期都是在热部署的环境下运转的。会极大缩小部署和运维过程带来的耗时
5.3 模块发展规划的业务应用架构师
虽然Serverless模块是一个面向“轻运维”的一个粒度,但是轻不代表可以无序扩张,无序扩张也会带来一些治理成本,防止架构陷入低成本模块新建陷阱。
我们在前期解决了各个场景的隔离问题,按照垂直领域拆分出了模块。但是在模块发展到一定规模的时候(资金创新业务在2022年末已经有20+模块),大家面临的问题就不仅仅是单一模块的研发过程提效了,而是有大量可复用的服务没有能够复用起来形成烟囱式建设了。公共服务的沉淀又成为了新的挑战,虽然重复建设的基础上做一些归并,选择部分模块增强“东西向”的接口调用承接一些公共服务,这样很可能会有边界分歧;如果把公共服务下沉到基座,就很有可能形成高频热点,让我们的又重回大量迭代竞争的巨石应用时代。
因此我们对模块的创建也是有一定原则的,当然,任何原则订立下来都是具有二义性的。我们只是在业务动态发展和增长的情况下,尽可能的适配我们的业务发展,怎么更好的削减理解成本和运维成本,寻找一个拆分和抽象的折中点。

很直观的例子,一个创业公司初期会孵化出很多微服务,但是当微服务发展到一定规模的时候会面临额外的运维成本、研发理解成本、运行时通讯成本……此时就需要集中进行治理,尤其是对可复用的部分的沉淀和抽象。
这个时候一方面是需要一些原则来约束增量应用的扩张的,另外一方面也要依据这些原则去做存量的模块的架构治理,做好归并和场景化复用。
5.4 蚂蚁研发全链路治理同行者
在SOFAServerless的新应用架构下,我们也需要关注周边生态和配套,可能部分能力的适配具有一些滞后性的。但是整体上,终态肯定是要追平甚至超越经典SOFA体系。所以我们尽可能梳理清楚我们不同的阶段、不同的维度到底需要哪些能力,这些能力是否已经适配,已经适配我们就直接享受这个红利,适配有滞后我们就寻求一些短期方案去度过。

基座管理员要对配套成熟度梳理清楚,在SOFAServerless发展的前期,有一些中间件、二方包、质量配套、技术风险配套对模块研发者来说是有适配滞后性的,所以短期必须需经过一些特殊的机制去封装。且作为基座owner,需要有研发体系全链路视角,洞察研发模式变化后对一线模块研发同学研发生命周期过程中的变化,并建立与研发效能团队的通道来消化、推进他们的诉求。
举个例子,现在质量仿真体系、智能化CI自动化用例体系,对于SOFAServerless的兼容具备一定滞后性,基座owner需要与相关团队建立链接,并关注进展
目前SOFAServerless已经解决了大多数的成熟度问题,已经度过了催熟期,对基座owner已经减少了80%的工作,研发模式已经趋近于稳定成熟。
6 回顾和展望
我们目前取得的成果
场景创新技术效率的极致提升——我们基于SOFAServerless,构建了“资金场景应用中心”系统,颠覆了传统巨石SOFA应用做场景化创新的模式
我们构建的“资金场景应用中心”平台,采用了上述思路,将业务关注点从SOFA应用粒度聚焦到了轻应用粒度,对java运行容器、通用业务能力做了全托管,平台陪伴了业务idea不断落地试错、业务创新节奏小步快跑2年时间,我们业务轻应用模块已经达到20+,部署次数在月均2000+次。但是我们的每次部署耗时维持在20秒左右,相比之前每月开发迭代部署整体耗时减少了95%以上;业务之间基于场景的互相隔离机制,也基本上摆脱了传统SOFA应用火车式发布频繁抢占。整体研发和发布效率的体感,毫无疑问提升了大家研发幸福度和“今晚早下班”的概率。

回顾落地方法和原则
回顾全篇文章,我们从分析问题、定义问题、技术选型、详细设计、落地执行去把我们资金技术Serverless提效的思路描绘了出来。需要明确的是,虽然对应用架构的创新和探索是非常激进的一件事,但是创新并不是拿锤找钉,带着“造好的轮子”摸着黑去探索,而是遵循了一些方法论和原则,把优秀的架构设计、优秀的提效特性吃透后做到在业务域平稳落地。
基座落地前的推演,我们会思考以下几个问题
1.如何做到激进的架构升级同时也兼顾业务的稳定性?
2.Serverless配套拼图如何落地?中间件的配套、质量风险配套、研发过程配套……等相关设施如何建设?
3.需要深度思考如何把增量价值放大?以及如何把基座的复利性发挥出来?
结合资金域的落地过程,我们是这样应对的
落地过程面临很多未知问题,初期我们可能只是宏观上做了可行性考量,但是随着对Serverless架构的认知提升,我们做架构治理的问题分母也变大了,这些“不确定性问题”带来的边际成本是比较大的。所以我们也遵循了一些的成熟的方法论来牵引整个架构升级的事项推进,初期我们运用了假设验证的方法来削减不“确定性”,通过问题反馈做调整和持续迭代;中期通过战役、跨团队协作去联动各个问题域弥补Serverless发展中的过程态短板;后期我们也针对资金基座的下探,去锚定低效问题的治理方向的同时,做精准发力并沉淀一些效能领域的建设。

分时:运用mvp最小价值交付的方法,先做poc假设验证,再进一步在可试错的业务上迭代,最终形成成熟稳定的态势后规模化推广。
分治:分拆问题,各自突破。协同了SOFAServerless战役的8+团队,把业务面临最紧迫的问题分析清楚并提供输入。
中间件适配滞后性的问题:短期用自身的适配框架度过+长期推进SOFA-Trigger适配中间件;
研发效能工具的问题:专题战役给linke、linkw、九州提供了输入并推进解决;
技术风险配套的问题:让仿真回放工具、灰度引流工具、采集框架工具等平台各自带回;
自身的架构治理:包括迁移九州机房、升级SOFA-Trigger等代际升级,和SOFAServerless团队做了紧密联动。
分层:按照自上而下不同的层次发掘提效点,从模块研发的层面、基座管理的层面、风险防控的层面各自去做一些下探,形成一些经验和过程的沉淀。
对“轻研发”模式的期待
作为轻应用这种研发模式的早期探索者,我们已经把心路历程分享出来,但是与此同时也有一些新的思路。
虽然蚂蚁的每个域的业务形态不一样,但是“资金场景应用中心”还是比较有代表性的,如果把所有技术产品都按照“类中间件”的方式提炼、抽象成starter插件放在插件市场里,顺便把一些问题规避、二方包基线、通用配置等运行时要素也提取出来,我们可以得到一个通用的基座模板。其他域可以基于这个模板,快速实例化构建出一个适合自己业务域的基座,让使用方可以大幅削减基座0-1成本, 可以快速丝滑的接入SOFAServerles
我们在2023初开了一个脑洞,也和玲珑产品团队贡献了这个想法。(如下图所示)

这样还是不够,实际上还是存在多个业务基座各自运维,还可以更进一步
比如目前的基座还是由业务团队的基座owner来负责的,且模块研发者可能或多或少还需要接触基座的概念,实际上这部分与业务没太大关系,可以考虑由特定技术团队完全托管掉并持续做技术演进。如果未来有一个通用基座的设想,基座如果能全面BaaS化,基础能力的集成、弹性资源的管控、业务流量的管控都能够技术产品化,我们就能够让模块开发者真正专注于业务场景的研发不用关心底层运维事项,让SRE能够接管基座的“代运维”,统一运维的基线可以覆盖到BaaS化基座。

实际上SOFAServerless技术产品也在做一些相关通用基座的试点。如果真正具备通用基座的广泛运用,才可以真正称得上是“轻研发”模式。
对SOFAServerless架构的期待
SOFAServerless是一种新兴的、高效的应用架构,具有敏捷开发、低复用成本、高灵活性、易隔离等优势,正在逐渐运用到蚂蚁的各个业务领域。但是Serverless架构也面临着治理上的挑战,需要建立相应的事件处理、安全性控制、性能测试、成本控制等机制来保证服务的稳定性、可用性和可靠性。
未来,随着SOFAServerless的不断发展,蚂蚁架构部也在做Serverless提效样板间推广,在蚂蚁各业务领域中的应用必将越来越广泛。当然,Serverless架构仍有一些优化空间,需要不断建设以满足不断变化的业务需求,如更灵敏的弹性能力、轻运维托管能力、智能化质量工程能力等还需要持续进行技术创新和探索。我们相信,借助Serverless技术的进步和发展,将会为蚂蚁集团未来的业务创新带来更多的机会与可能!
SOFAServerless开源助力企业低成本实现Serverless
SOFAServerless 当前已平稳支撑了蚂蚁集团 42 万核数规模的生产业务,并成功支撑了近 3 年的大小促活动,随着这套技术在蚂蚁内部越来越成熟,凸显了它能够让普通应用以尽可能低的成本平滑演进到 Serverless 架构,并且还很好解决了微服务领域里 4 个痛点问题:
- 资源与维护成本之痛:存量微服务如果拆分过多,能低成本改造成模块合并部署在一起,从而解决拆分过多带来的企业资源成本和维护成本痛点。
- 研发协作之痛:一个应用可以低成本拆分出多个模块,模块间可以并行独立迭代,从而解决业务多人协作阻塞问题。
- 开发认知之痛:通过拆分出基座屏蔽了业务以下的基础设施、中间件和业务通用逻辑等部分,从而极大降低了开发者的认知负荷,提升了开发效率。
- 微服务演进之痛:模块可以灵活部署,解决了微服务拆分与组织发展灵敏度不一致导致的协作低效和分工不合理问题。应用能低成本拆分成多个模块,可以部署在一起,也可以演进成独立微服务,同样微服务拆分过多也可以低成本改为模块合并部署在一起。
因此,蚂蚁集团开始致力于 SOFAServerless 开源版建设(当前已有 8+ 企业在使用 SOFAServerless 开源版),旨在帮助整个行业去解决上述痛点问题,帮助企业早日实现降本增效!
欢迎大家关注 SOFAServerless 开源社区,加入我们的社区钉钉群:24970018417。更欢迎大家与我们来一起共建,一起创造价值解决行业痛点!
SOFAServerless Star 一下✨:
4 - 阿里国际数字商业集团中台业务三倍提效
作者: 朱林(封渊)、张建明(明门)
项目背景
过去几年,AIDC(阿里巴巴海外数字商业)业务板块在全球多个国家和地区拓展。国际电商业务模式上分为"跨境"和"本对本"两种,分别基于AE(跨境)、Lazada、Daraz、Mirivia、Trendyol 等多个电商平台承载。以下将不同的电商平台统称为“站点”。
对于整个电商业务而言,各个站点核心的买卖家基础链路存在一定的差异性,但更多还是共性。通过抽象出一个通用的平台,在各个站点实现低成本复用有助于更高效的支持上层业务。所以过去几年基础链路一直在尝试通过平台化的建设思路,通过 1个全球化业务平台 + N个业务站点 的模式支持业务发展;其中技术的迭代经历了五个阶段的发展,从最初的中心化中台集成业务的架构模式,逐步转变为去中心化被业务集成的架构,已经基本可以满足全球化各个站点业务和平台各自闭环迭代。
各个站点逻辑上是基于国际化中台(平台)做个性化定制,在交付/运维态各个站点被拆分成独立的应用,分别承载各自业务流量,平台能力通过二方包方式被站点应用集成,同时平台具备能力扩展机制,业务站点的研发能在站点应用中覆写平台逻辑,这最大化的保证了站点业务的研发/运维自主性,同时一定程度上保证了平台能力的复用性。 但由于当前各个电商站点处于不同的发展时期,并且本对本跟跨境在业务模式上也存在差异性,以及业务策略上的不断变化,业务的快速迭代跟平台能力的后置沉淀逐步形成了矛盾,主要表现在如下几个方面:
- 平台重复建设:由于平台采用开放、被集成的策略且缺乏一定的约束,需求的迭代即便是需要改动平台逻辑,站点也基本自闭环,在平台能力沉淀、稳定性、性能、开放性等各个站点都存在重复建设,支持不同站点的平台版本差异性逐步扩大;
- 站点维护成本高:各自闭环的站点应用,由于同时维护了定制的平台能力,承担了部分"平台团队的职责",逐渐的增加了站点研发团队的负担,导致人力成本升高;
- 研发迭代效率低:核心应用构建部署效率低下,以交易站点应用为例,系统启动时长稳定在 300s+,编译时长 150s+,镜像构建时长 30s+,容器重新初始化等调度层面的耗时 2min 左右,研发环境一天部署次数100+,如果能降低构建部署时长,将有效的降低研发等待时长;
所以,下一代的架构迭代将需要重点解决平台去中心化被业务集成的架构模式下如何实现能力的迭代自主性以及版本统一,另外也需要考虑如何进一步降低站点的研发、运维成本,提升构建、部署效率,让业务研发真正只关注在自身的业务逻辑定制。 Serverless 的技术理念中,强调关注点分离,让业务研发专注在业务逻辑的研发,而不太需要关注底层平台。这样一个理念,结合上述我们面临的问题或许是一个比较好的解法,让平台从二方包升级成为一个平台基座应用,统一收敛平台的迭代,包括应用运行时的升级;让业务站点应用轻量化,只关注定制逻辑的开发,提升部署效率,降低维护成本,整体逻辑架构图如下:
概念阐述
Serverless 普遍的理解是“无服务器架构”。它是云原生的主要技术之一,无服务器指的是用户不必关心应用运行和运维的管理,可以让用户去开发和使用应用程序,而不用去管理基础设施,云服务商提供、配置、管理用于运算的底层基础设施,将应用程序从基础结构中抽离出来,让开发人员可以更加专注于业务逻辑,从而提高交付能力,降低工作成本。传统 Serverless 在实现上其实就是 FaaS + BaaS。FaaS 承载代码片段(即函数),可随时随地创建、使用、销毁,无法自带状态。和 BaaS(后端即服务)搭配使用。两者合在一起,才最终实现了完整行为的 Serverless 服务。
在传统 Serverless 技术体系下,Java 应用架构更多的是解决了 IaaS 层 + 容器化 的问题,Serverless 本身无法将涵盖范围下探到 JVM 内部。因此,对于一个复杂的 Java 巨石应用,可以借助 Serverless 的理念将 Java 技术栈下的业务代码和基础设施(中间件)依赖做更进一步的剥离与拆分。本次实践中的 Serverless 改造可以抽象为如下过程和目标:
将一个单体应用横向拆分成上下两层:
- 基座:将一些业务应用迭代中不经常变更的基础组件以及 Lib 包下沉到一个新的应用中去,这个新应用我们称之为
基座应用,有以下特点:- 基座是可独立发布与运维的
- 基座应用开发者可以统一升级中间件和组件版本,在保证兼容性的前提下,上层 App 无需感知整个升级过程
- 基座具备不同站点间的可复用性,一个交易的基座可以被 AE、Lazada、Daraz等不同的站点 App 共用
- Serverless App:为了最大程度减少业务的改造成本,业务团队维护的 App 依旧保持其自身的发布运维职责的独立性不变,Serverless 化后业务开发人员只需要关心业务代码即可。JVM 对外服务的载体依旧是业务应用。
技术实施
Serverless 架构演进的实施过程分为两个部分:
- 重新设计 Serverless 架构模型下的应用架构分层与职责划分,让业务减负,让 SRE 提效。
- 在研发、发布&运维等领域采用新的研发框架、交付模型与发布运维产品来支持业务快速迭代。
应用架构
以 Daraz 基础链路为例,应用架构的分层结构、交互关系、团队职责如下:
我们将一个 Serverless 应用完整交付所需的支撑架构进行逻辑分层与开发职责划分,并且清晰定义出 App 与基座之间交互的协议标准。
研发域
- 构建了 Serverless 运行时框架,驱动"基座-Serverless App"的运行与交互
- 与 Aone 研发平台团队协作,建设一整套 Serverless 模式下基座与 App 的发布&运维产品体系
voyager-serverless framework
voyager-serverless framework 是一个基于 Koupleless 技术自研的提供 Serverless编程界面 的研发框架,允许业务 App 以 动态 的方式被装载到一个正在运行的基座容器(ArkContainer)中。在 Koupleless 模块隔离能力的基础上,我们针对阿里集团技术栈做了深度改造定制。
整套框架提供以下关键能力:
隔离性与运行时原理
框架实现了基座与应用模块的 ClassLoader隔离 与 SpringContext隔离。启动流程上,一共分为 两阶三步,启动顺序自底向上:
- 一阶段基座启动
- 第一步: 启动 Bootstrap,包含 Kondyle 以及 Pandora 容器,加载
Kondyle 插件以及Pandora 中间件插件的类或对象 - 第二步:
基座应用启动,其内部顺序为- 启动 ArkContainer,初始化 Serverless 相关组件
- 基座应用 SpringContext 初始化,对象初始化过程中加载
基座自有类、基座Plugin类、依赖包类、中间件SDK类等
- 第一步: 启动 Bootstrap,包含 Kondyle 以及 Pandora 容器,加载
- 二阶段app启动
- 第三步:
Serverless App启动,由 ArkContainer 内置组件接受Fiber调度请求下载 App 制品并触发 App Launch- 创建 BizClassLoader,作为线程 ClassLoader 初始化 SpringContext,加载
App自有类、基座Plugin类、依赖包类、中间件SDK类等
- 创建 BizClassLoader,作为线程 ClassLoader 初始化 SpringContext,加载
- 第三步:
通信机制
在 Serverless 形态下,基座与 App 之间可以通过 进程内通信方式 进行交互,目前提供两种通信模型: SPI 和基座Bean服务导出
SPI 本质上就是基于标准 Java SPI 的扩展的内部特殊实现,本文不额外赘述,这里重点介绍下
基座Bean服务导出。
一般情况下,基座的 SpringContext 与 App 的 SpringContext 是完全隔离的,且没有父子继承关系。因此 App 侧不能通过常规 @Autowired 的方式引用下层基座 SpringContext 中的 Bean。
除了 Class 的下沉,在一些场景下,基座可以将自己已经初始化好的 Bean 对象也下沉掉,声明并暴露给上层 App 使用。这样之后 App 启动的时候可以直接拿到基座 SpringContext 中的已经完成初始化的 Bean,用以加快 App 的启动速度。其过程如下:
- 用户通过配置或者注解标注声明需要在基座中导出的 Bean 服务
- 基座启动结束后,隔离容器会自动将用户标注的 Bean 导出到一个缓冲区中,等待 App 的启动使用
- App 在基座上启动,App 的 SpringContext 初始化过程中,会在初始化阶段读取到缓冲区中需要导入的 Bean
- App 的 SpringContext 中的其他组件可以正常
@Autowired这些导出的 Bean
插件机制
Serverless 插件提供了一种能够让 App 运行时所需的类默认从基座中加载的机制,框架支持将平台基座需要暴露给上层 App 使用的SDK/二方包等包装成一个插件(Ark Plugin),最终实现中台控制的包下沉到基座而不需要让上层业务改动:
中间件适配
在 Serverless 架构演进中,由于一个完整应用的启动过程被拆分成基座启动和 App 启动,因此在一二阶段相关中间件的初始化逻辑也发生了变化。我们对国际侧常用的中间件和产品组件进行了测试,并对部分中间件进行了适配改造。 总结起来,大部分问题都出现在中间件一些流程逻辑没设计这种多 ClassLoader 的场景,很多类/方法使用中不会将ClassLoader 对象作为参数传递进来,进而在初始化模型对象时出错,导致上下文交互异常。
开发配套
我们也提供了一整套完整且简单易用的配套工具,方便开发者快速接入 Serverless 体系:
发布 & 运维域
除了研发域,Serverless 架构在发布运维领域也带来很多新的变化。首先是研发运维分层拆分,实现了关注点分离,降低研发复杂度:
- 逻辑拆分:将原本应用拆分,将业务代码和基础设施隔离,基础能力下沉,比如将改造前启动过程中耗时中间件、一些富二方库和需要管控的二方库等等下沉到基座中,实现了业务应用轻量化。
- 独立演进:分层拆分后,基座和业务应用各自迭代,SRE 可以在基座上将基础设施的统一管控和升级,较少甚至杜绝了业务的升级成本。
我们也和 Aone 一起合作,voyager-serverless 借助 OSR(Open Serverless Runtime) 标准协议接入 Aone Serverless 产品技术体系中去。借助新的发布模型和部署策略,在 App 构建速度和启动效率上得到很大提升。
构建效率提升
- Maven 构建优化: 由于很多依赖包都已经下沉到已经就绪的基座,因此对于 App 来说就可以减少需要构建的二方包数量以及 Class 文件数量,进而整体优化制品大小,提升构建效率
- Docker 构建移除: 由于 Serverless 模式下业务 App 部署的制品就是轻量化 Fat Jar,因此也无需进行 docker 构建
发布效率提升
在 Serverless 模式下,我们采用 Surge+流式发布 替换传统的分批发布来进一步提升 App 的发布效率。
| 名词 | 描述 |
|---|---|
| 分批发布 | 分批发布策略是达到每个批次的新节点后,进行下一批次,如 100 个节点,10 个批次,第一批次卡点 10 个新节点,第二批次卡点 20 个新节点,依次类推 |
| Surge | Surge 发布策略可以在不影响业务可用性的前提下加速业务发布效率: 1) 发布时会新增加配置 Surge 比例的数量节点,比如业务有 10 台机器,Surge 配置百分比为 50,发布过程就会首先增加 5 台机器用于发布 2) 如果基座中配置了合理大小的 Buffer,那么可以直接从 Buffer 中获取这 5 台机器,直接发布新版本代码 3) 整体新版本节点数达到预期数量(本例中 10 台机器),直接下线旧节点,完成整次发布过程 其中 Surge 结合流式发布一起使用,同时配合 Runtime 中合适数量的 Buffer,可以最大程度地加速业务发布效率 |
- 瀑布流分批发布:每一个批次的机器全部发布上线之后开始发布下一批次,批次内机器并行发布,批次之间串行。假设有100台机器,分10批次发布,每批发布的机器数为10台,发布总耗时为:
- Surge流式发布:发布过程中,允许多分配一些机器来参与更新,核心原理为
满足可用度的前提下,增大单轮次中参与更新的机器个数。例如有100台机器,在满足可用度≥90%的前提下,即任意时刻至少有90(100*90%)个机器在线,surge=5%的发布调度过程如下:
借助这个新的发布模型,我们在开发变更最频繁的日常和预发环境全面开启 Surge 发布,用来加速业务 App 的发布。
- 在进行 Serverless 改造前:
- 为了保证发布过程中流量不受影响,一般情况下,一个预发环境会保留两台机器(replica = 2),执行传统的分批发布(batch=2),也就是每台机器轮流更新。
- 这里我们假定应用启动耗时为5min,其中频繁变更的业务代码1min,平台以及中间件等组件加载耗时4min
- 发布总耗时为 5min + 5min = 10min
- 完成 Serverless 改造,采用 Surge 流式发布后
- App 的预发环境只需要保留一台机器(replica = 1),基座设置buffer = 1,即保留一台空基座用于准备给 App 调度使用
- 发布策略上,App 环境 Surge 比例为100%
- 由于只发布更新了 App 的 Biz 代码,发布总耗时为 1min,并且整个过程机器总成本保持不变
同时,我们也在生产环境配置一定数量的基座 Buffer,支持站点 App 的快速弹性扩容。
总结与展望
目前已经完成 Daraz 业务站点的交易、营销、履约、会员、逆向应用的 Serverless 升级改造,在 构建时长、单机应用启动时长、预发环境发布时长 三个指标上均取得了较大优化效果。在个别领域,甚至真正做到了 App 的 10秒 级启动。
可以看到,本次 Serverless 架构的升级,无论从理论推演还是实践结果,都产生了较大的正向收益与效率提升,这给后续业务 App 的快速迭代带来了不少便利。同时,由于平台代码下沉为基座应用,也具备了跟业务站点正交的发布能力,基本上可以实现基础链路平台版本统一的目标;“关注点分离"也解放了业务开发者,让他们更多关注在自己的业务代码上。但是,还有一些如开发配套成熟度、问题定位与诊断、生产环境成本最优的基座配置等问题与挑战需要进一步解决。我们也会深度参与共建 Koupleless 开源社区,发掘更多的落地场景与实践经验。
Serverless 从来不是某个单一的架构形态,它带来的更多是一种理念和生产方式。理解它、利用它,帮助我们拓宽新的思路与解题方法。
5 - 高效降本|深度案例解读 Koupleless 在南京爱福路的落地实践
作者:祁晓波, 南京爱福路汽车科技基础设施负责人, 主要研究微服务、可观测、稳定性、研发效能、Java 中间件等领域。
Koupleless(原 SOFAServerless)自 2023 年开源以来已经落地了若干企业,这些企业也见证了从 SOFAServerless 到 Koupleless 的品牌&技术能力迭代升级。随着 Koupleless 1.0 的重磅发布,一些企业已经在内部取得了不错的效果,例如南京爱福路汽车科技有限公司。
南京爱福路汽车科技有限公司和大多数科技企业一样,在企业生产开发过程遇到了微服务的一些问题,例如资源成本过高、启动慢等问题。在看到 Koupleless 项目正不断开源出实实在在的能力和案例,在解决很实际的微服务痛点问题,决定采用 Koupleless 进行尝试,并随着 Koupleless 一路走来,已经将 6 个应用合并成 1 个应用大幅降低资源成本,取得了不错的效果。
背景
南京爱福路汽车科技有限公司(以下简称爱福路)作为行业 top 的汽车后市场解决方案提供商,为维修门店提供智慧管理系统、为行业提供维修应用大数据,致力于成为汽车后市场数智化构建者。
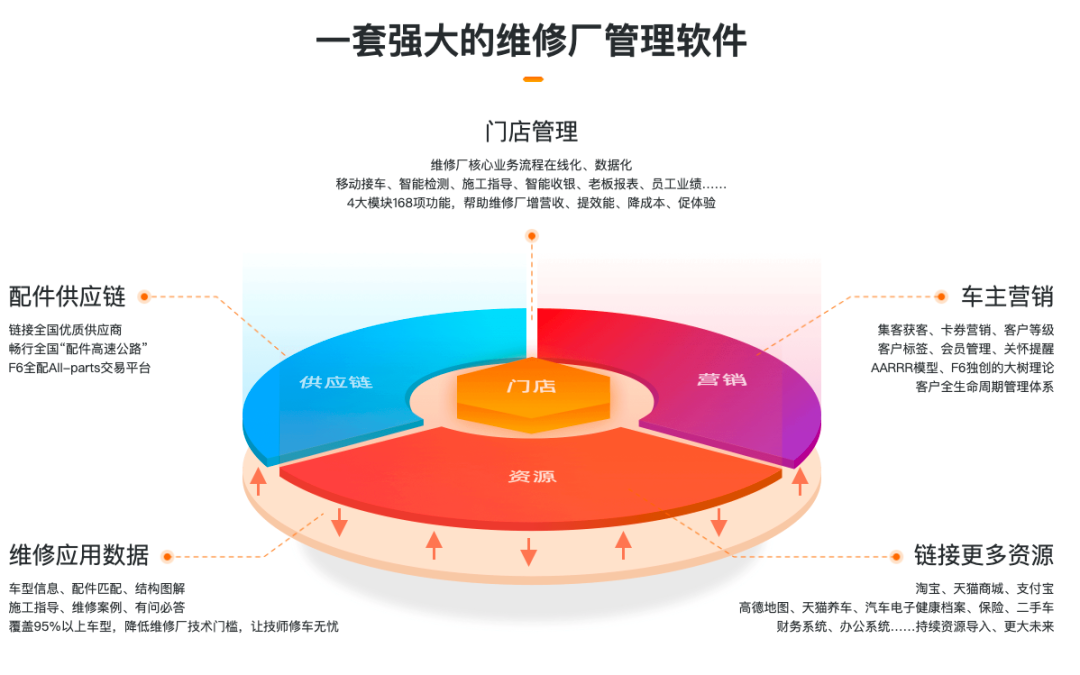
随着其服务的企业增多,爱福路也越来越多地接触到了各类体量的企业。这就对爱福路的服务提供形式提出了较多不同的诉求:除了单纯的公有云 SAAS 之外,还包括私有化部署等解决方案的诉求。
问题提出
我们知道,随着微服务和云原生技术的普及,应用数量急剧膨胀。
如此多的应用也带来了比较大的成本问题。爱福路在为海量公域客户提供服务的时候,更关注稳定、弹性。
但是在为某个客户提供独立部署方案时,爱福路发现如此多的服务在部署到 K8s 时所带来的服务器成本非常高(通常来说,独立部署服务面向的客户群体比之公域客户少了 1-2 个数量级),而单个客户也很难有足够的预算负担整个部署方案。这就大大阻塞了爱福路后续持续拓展私有化部署客户的进度。
举个例子:一个应用在进行 K8s 交付时,最少会提供两个副本;而大量这样的 Java 应用存在对于整体的集群利用率不高,继而造成较高的成本。
因此爱福路面临着如下的课题:当进行私有化交付时,如何能够更便捷地、低成本地交付我们现有的产物?
其中,低成本至少应该包含如下几个角度:
1、既存代码的低成本改造;
2、新的交付方式低成本的维护;
3、运行产物低成本的 IT 成本。
问题探索和推导
爱福路基于当前的微服务架构和云原生方式进行了思考和探索:是否到了爱福路微服务架构进一步升级的时候了?
在当前整体降本增效的大环境趋势中,在保持服务稳定的前提下对于服务器有更加极致的使用。
从业务视角来看,服务单店的整体服务器成本越低,爱福路的竞争力就越强。
那么,有没有可能在保持 Java 的生态环境下,低成本的同时能够保证爱福路继续享受云原生的红利?爱福路做了如下推导:
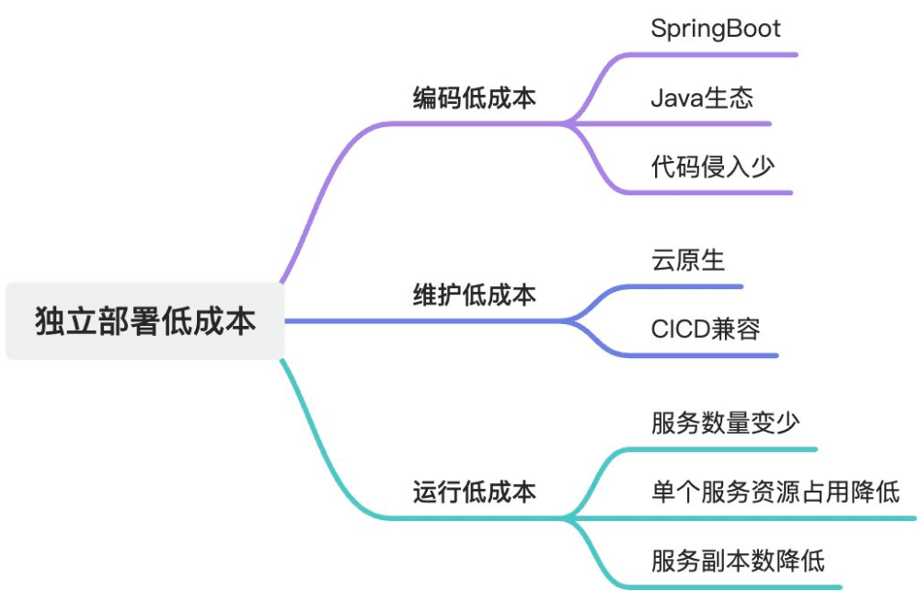
通过上述的推导,爱福路判断也许「模块化+Serverless」将是一种解法。
因此一款来自蚂蚁的开源框架成为他们重点的关注,那就是 Koupleless。( 阅读原文可跳转官网地址:https://koupleless.io/user-cases/ant-group/ )
当然一个重要原因是蚂蚁开源一直做得不错,社区也比较活跃。除了社区群和 GitHub 之外,PMC 有济也积极地建立了独享的 VIP 群进行专门对接。
Koupleless(原SOFAServerless)
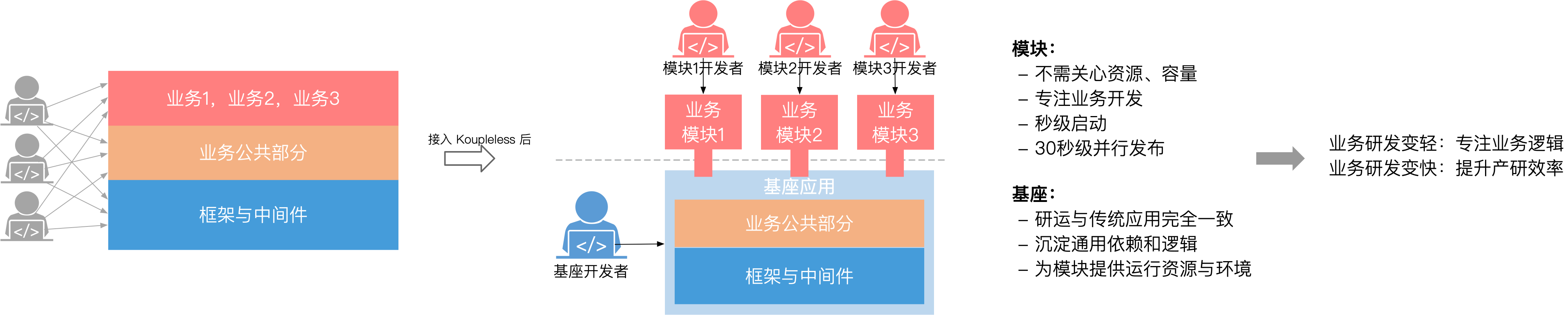
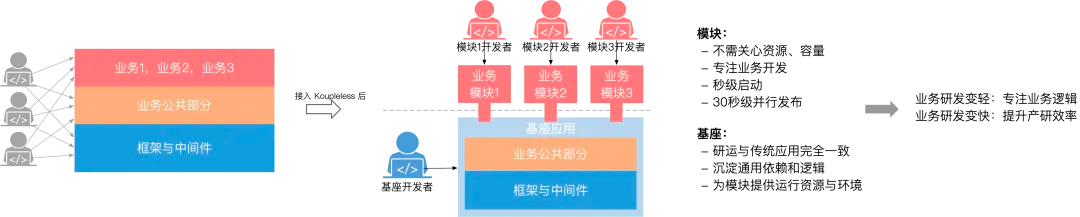
Koupleless 技术体系是在业务发展、研发运维的复杂性和成本不断增加的情况下,蚂蚁集团为帮助应用又快又稳地迭代而决定研发,从细化研发运维粒度和屏蔽基础设施的角度出发,演进出的一套低成本接入的「模块化+Serverless」解决方案。
核心方式是通过类隔离和热部署技术,将应用从代码结构和开发者阵型拆分为两个层次:业务模块和基座,基座为业务模块提供计算环境并屏蔽基础设施,模块开发者不感知机器、容量、中间件等基础设施,专注于业务研发帮助业务快速向前发展。
合并部署降成本
在企业中, “80%” 的长尾应用仅服务 “20%” 的流量,蚂蚁集团也不例外。在蚂蚁集团存在大量长尾应用,每个长尾应用至少需要 预发布、灰度、生产 3 个环境,每个环境最少需要部署 3 个机房,每个机房又必须保持 2 台机器高可用,因此大量长尾应用 CPU 使用率不足 10%。
通过使用 Koupleless,蚂蚁集团对长尾应用进行了服务器裁撤,借助类委托隔离、资源监控、日志监控等技术,在保证稳定性的前提下,实现了多应用的合并部署,极大降低了业务的运维成本和资源成本。
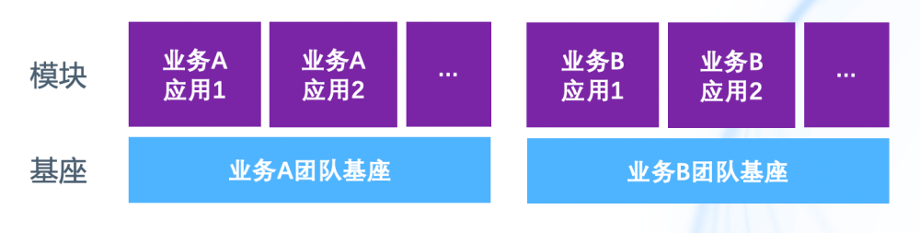
此外,采用这种模式,小应用可以不走应用申请上线流程,也不需要申请机器,可以直接部署到业务通用基座之上,从而帮助小流量业务实现了快速创新。
2023 年底 SOFAServerless 品牌全新升级为 Koupleless( GitHub页面:https://github.com/koupleless/koupleless )。
企业里不同业务有不同的发展阶段,因此应用也拥有自己的生命周期。
初创期:一个初创的应用一般会先采用单体架构。
增长期:随着业务增长,应用开发者也随之增加。此时您可能不确定业务的未来前景,也不希望过早把业务拆分成多个应用以避免不必要的维护、治理和资源成本,那么您可以用 Koupleless 低成本地将应用拆分为一个基座和多个功能模块,不同功能模块之间可以并行研发运维独立迭代,从而提高应用在此阶段的研发协作和需求交付效率。
成熟期:随着业务进一步增长,您可以使用 Koupleless 低成本地将部分或全部功能模块拆分成独立应用去研发运维。
长尾期:部分业务在经历增长期或者成熟期后,也可能慢慢步入到低活状态或者长尾状态,此时您可以用 Koupleless 低成本地将这些应用一键改回模块,合并部署到一起实现降本增效。

可以看到 Koupleless 主要通过将应用模块化来降低整个服务的运行成本,更值得称道的是支持模块和应用的来回切换,可以更低成本地接入,支持平滑演进。
架构适配尝试
Spring Boot 1「可行性确认」
爱福路的存量应用中,九成使用的是 Spring Boot 1,RPC 主要依赖 Dubbo 2.6。这点和社区是有一定出入的,社区仅仅支持 SpringBoot 2。为此爱福路需要尝试对于 Spring Boot 1 的支持,也因此提出了相应的 issue, 通过和社区沟通协调确认,爱福路发现只是社区没能够完全覆盖到这块,企业自身可以通过部分扩展进行支持。
当时社区同学认为这个是比较重要的变更,可以进一步覆盖更多的社区用户,为此还特地调整了中央仓库的发版频次:加速 review、加速发 snapshot。
正是这些细节让爱福路更加信任 Koupleless 团队👍,也坚定了此次方案能够实际落地的信心。
应用合并
当 Spring Boot 1 得到支持之后,爱福路可以快速地将原来的应用转换成为模块,也能够成功地启动和运行。
Dubbo 2.6 合并问题
Dubbo 是一种高效、可扩展、可靠的分布式服务框架解决方案,由阿里巴巴公司开发并开源,适用于构建大型分布式系统。它基于 RPC 的服务调用和服务治理,具有透明化的远程调用、负载均衡、服务注册与发现、高度可扩展性、服务治理等特点。
正如上文所说,爱福路的服务主要是 Dubbo 进行 RPC 调用,但是 Dubbo 2.6 对于 Sofa-ark 倡导的多 ClassLoader 支持不够完善,因此爱福路也通过各种方式来进行尝试。
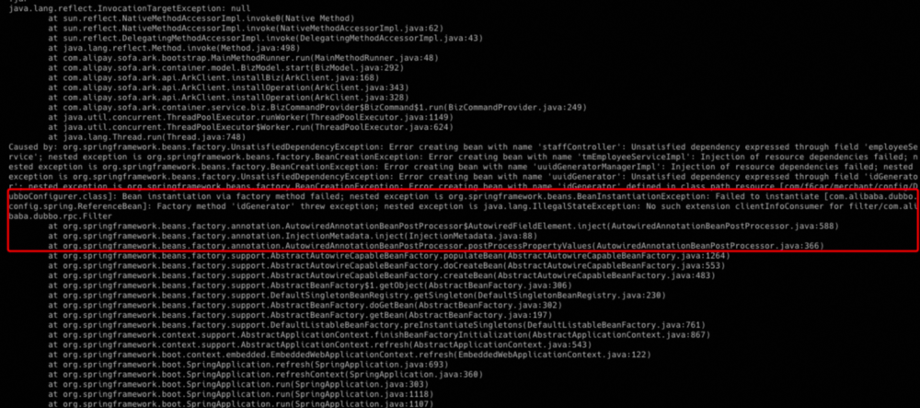
为此,爱福路也和社区进行沟通确认,最后社区提供了一套相对简便的能够增强 Dubbo 版本、支持多 ClassLoader 的方案
应用模型抽象封装
Apollo(阿波罗)是一款可靠的分布式配置管理中心,诞生于携程框架研发部,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
服务端基于 Spring Boot 和 Spring Cloud 开发,打包后可以直接运行,不需要额外安装 Tomcat 等应用容器。Java 客户端不依赖任何框架,能够运行于所有 Java 运行时环境,同时对 Spring/Spring Boot 环境也有较好的支持。
但问题是,在同一个 JVM 中,Apollo 的 appid 会互相污染,导致最后只有一个 Apollo 配置能够获取。
private static final String[] APOLLO_SYSTEM_PROPERTIES = { "app.id", ConfigConsts.APOLLO_CLUSTER_KEY, "apollo.cacheDir",
"apollo.accesskey.secret", ConfigConsts.APOLLO_META_KEY,
PropertiesFactory.APOLLO_PROPERTY_ORDER_ENABLE };
/**
* To fill system properties from environment config
*/
void initializeSystemProperty(ConfigurableEnvironment environment) {
for (String propertyName : APOLLO_SYSTEM_PROPERTIES) {
fillSystemPropertyFromEnvironment(environment, propertyName);
}
}
private void fillSystemPropertyFromEnvironment(ConfigurableEnvironment environment, String propertyName) {
if (System.getProperty(propertyName) != null) {
return;
}
String propertyValue = environment.getProperty(propertyName);
if (Strings.isNullOrEmpty(propertyValue)) {
return;
}
System.setProperty(propertyName, propertyValue);
}
核心是因为其使用了 System.setProperty 导致了 appid 的覆盖。基于此,社区也提供了相关的一键接入组件,可以便捷接入。
静态合并发布加速
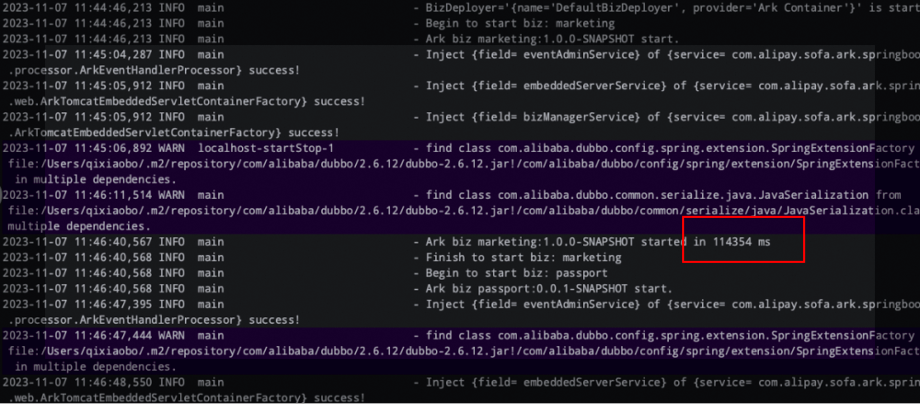
此外爱福路还遇到了启动时间太长的问题。与社区沟通后,社区立项提供了静态部署的加速方案,将原来的串行发布修改为并行发布,启动速度提升明显。

对比上下两张图,可以发现修改之后,启动时间从原来的 114 秒加速到了 29 秒。
初步成果
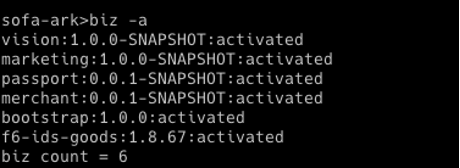
爱福路接入了 Koupleless 之后,成功地合并了多个应用。
后续演进和诉求
对于社区,爱福路有着满满的肯定,更多应用也将落地 Koupleless,因此提出了后续的演进诉求:
对于模块应用的卸载稳定性的诉求:对于动态发布,不希望每次修改一个模块就要重启整个应用;
针对爱福路利用 K8s 的 service 作为 http 的自动发现来说,pod 的就绪探针是一起的,那么如何做到一个模块发布不影响其他流量请求,以及 ingress 需要如何做;
针对云原生发布来看,如何更加无缝接入当前的发布体系
6 - 涂鸦智能落地 Koupleless 合并部署,实现云服务降本增效
作者:八幡、朵拉,杭州涂鸦智能技术专家

Koupleless 在涂鸦智能的落地效果探讨
背景
涂鸦智能是全球领先的云平台服务提供商,致力于构建智慧解决方案的开发者生态,赋能万物智能。基于全球公有云,涂鸦开发者平台实现了智慧场景和智能设备的互联互通,承载着每日数以亿计的设备请求交互;拥有亿级海量数据并发处理能力,为用户提供高稳定性的不间断计算服务。

涂鸦智能不仅服务于公有云用户,同时也为大客户提供混合云及私有云解决方案,满足不同层次客户的需求。因此,涂鸦需要同时关注公有云和私有云服务中潜在的问题。
公有云用户基数大、设备多、核心业务服务实例多,但也符合二八原则——20%的服务承担了 80%的流量。还有大量的配套周边管理服务及正处于发展中的业务等,虽然服务实例数量少,但为了保障业务的稳定性及可用性,至少得部署 2 个实例。
私有云在服务刚落地时,通常规模较小,随着业务的逐步发展,接入的用户数和设备数才会随之上涨。如果一开始就生搬硬套公有云的交付模式,将上百个服务部署在私有云客户环境中,基础设施成本占比太大,不仅造成了硬件资源成本浪费,同时也提升了运维复杂度。
综合考虑公有云部分服务和私有云前期服务存在的硬件资源利用率低、弹性扩容慢等问题,涂鸦开始着手调研解决方案。
方案调研
首先看下内存占用情况:
内存占用分析
涂鸦绝大部分业务应用都是采用 Java 语言实现的,基于微服务架构,部署在 K8S 上。来看下内存占用情况:
- 每个 POD 都需要启动精简的 Linux 系统,约几十兆初始内存;
- K8S 节点一般会附带一些 POD 监控、日志收集 Agent,约几十兆初始内存;
- Java Agent 之类的字节码增强消耗的初始内存;
- JVM 类库,Spring、Netty、Dubbo 等框架,内嵌 WEB 容器,占用的 Metaspace 和堆栈空间;
- 业务应用代码启动占用的 Metaspace 和堆栈空间;
- 业务流量处理产生的堆栈空间。
从上面分析可以看出,除了业务应用代码本身和业务流量处理之外,其他的内存占用当然是越少越好。一个简单的控制台应用内存占用如下图所示:

在微服务架构的视角下,Java 应用不但没有百多兆的 JRE 和框架之类的基础内存需要问题,更重要的是,单个微服务也不再需要再数十 GB 的内存。有了高可用的服务集群,也无须追求单个服务 7×24 小时不间断运行,在一天内随着业务流量的波动、高峰和低谷,服务随时可以进行弹性扩缩容。
但相应地,Java 的启动时间相对较长、需要预热才能达到最高性能等特点就显得相悖于这样的应用场景。在无服务架构中,矛盾则可能会更加突出,比起服务,一个函数的规模通常会更小,执行时间会更短。在这样的场景下,我们看下有哪些方案可以降本增效:
⭕️ 搁浅方案:Native Image
⭕️无法支持全场景、Spring 支持不足、异常难预见、问题难排查。
提前编译(Ahead of Time Compilation,AOT)可以减少即时编译带来的预热时间,减少 Java 应用长期给用户带来的“第一次运行慢”的不良体验,让用户能放心地进行很多全程序的分析行为,使用更大的优化措施。而随着 Graal VM 技术的成熟,它能显著降低内存占用及启动时间。由于 HotSpot 本身就会有一定的内存消耗(通常约几十 MB),根据 Oracle 官方给出的测试数据,运行在 Substrate VM 上的小规模应用,其内存占用和启动时间与运行在 HotSpot 相比有了 5 倍到 50 倍的下降。
但是提前编译的坏处也很明显,它破坏了 Java“一次编写,到处运行”的承诺,必须为每个不同的硬件、操作系统去编译对应的发行包。它也显著降低了 Java 链接过程的动态性,要求加载的代码必须在编译期就是全部已知的,而不能再是运行期才确定,大多数运行期对字节码的生成和修改操作也不再行得通。特别是在整个 Java 的生态系统中,数量庞大的第三方库要一一进行适配。随着 Graal VM 团队与来自 Pivotal 的 Spring 团队的紧密合作,解决了 Spring 全家桶在 Graal VM 上的运行适配问题。
为此,我们进行了 JDK17 升级,并将 SpringBoot 升至 3.x 版本,Dubbo 升至 3.x 版本。在验证过程中出现了许多组件的兼容性问题,如 Apollo、Guava、Jedis、MyBatis 等,也进行了逐一解决。
虽然该方案在简单的内部应用上验证通过,并上线试运行了一段时间,取得了一定的效果。但业务应用使用的第三方库数量众多,达到数百个,在如 GroovyShell、BouncyCastle、Agent 等场景上还无法很好地支持。同时 Spring 的支持不足,如 Spring XML Bean 的构造参数或 properties 配置出现 TypedStringValue 类型无法识别,Spring-AOT 不支持 setter-inject 方式的循环依赖等,导致需要对应用进行较大调整和修改,另外会出现一些无法预见的异常,且出现问题时不方便定位排查。最后涂鸦还是决定暂时搁浅该方案。
✅ 使用中:Koupleless
Koupleless 是一种模块化的 Serverless 技术解决方案,它能让普通应用以比较低的代价演进为 Serverless 研发模式,让代码与资源解耦,轻松独立维护,与此同时支持秒级构建部署、合并部署、动态伸缩等能力为用户提供极致的研发运维体验,最终帮助企业实现降本增效。
不同模块支持完全类隔离加载,对于应用开发来说相对透明,当然 Koupleless 也提供了更多插件机制,还有进程间跨 ClassLoader 的 JVM 调用能力。主要有如下优势:
- 类隔离:通过对业务应用的类隔离加载,原有业务系统几乎无侵入支持合并部署;
- 插件机制:通过插件机制解决依赖冲突问题;
- 基座和模块:可以将中间件和基础框架下沉到基座,框架与中间件升级维护成本降低。通过进程内 JVM 调用替代远程调用,节省网络 IO 和序列化反序列化成本,提升性能和稳定性。见下图:

- 静态合并部署:方便快速验证,简化部署,适合私有云环境;
- 动态合并部署:支持模块的热更新,提高发布效率,降低启动时间,适合公有云环境。
就内存节省效率方面来说,可以节省 POD 容器、Tomcat 容器、公共类库加载 Metaspace 等内存资源,主要是节省启动内存开销。对于低流量业务,几个应用合并部署到一个,资源利用更充分:10 个低流量 1C2G 应用,合并后仅需能一个 2C4G 就能搞定;单个应用突发的高流量可以有更大的水位池,稳定性也会提升。而对于高流量业务,虽然在内存方面优势不大,但可以实现极速弹性,更有利于 Serverless 架构。
❌ 其他弃选方案
- 代码合并:简单粗暴,降本优势明显,但同时也降低了开发和运维效率,不利于维护和业务快速发展
- 基于代码组织的模块化:服务打成 jar 包引入,但没有 ClassLoader 隔离,容易造成类库依赖冲突,beanName 冲突等
- 基于 Tomcat 的多 WAR 包部署:业务系统无任何侵入,也能一定程度上节省多个应用的 POD 和应用内置 Tomcat 内存。但脱离了主流的 DevOps 体系,需要针对这种部署方式提供额外支持,同时能节省的内存也非常有限。
改造升级
Koupleless 是一种多应用的架构,而传统的中间件可能只考虑了一个应用的场景,故在一些行为上无法兼容多应用共存的行为,会发生共享变量污染、ClassLoader 加载异常、Class 判断不符合预期等问题。由此,在使用 Koupleless 中间件时,我们需要对一些潜在的问题做补丁,覆盖掉原有中间件的实现,使开源的中间件和自研的组件也能兼容多应用的模式,涉及到以下的使用方式,可能需要多模块化适配改造:
适配点
系统变量被共享
在使用的时候,需要考虑到全局共享的情况下是否会与别的模块冲突,包括但不限于:Appid 、环境变量、System 配置等。
静态变量、静态单例、静态缓存被共享
正常情况下公共代码都是由基座进行加载,而基座的类加载器是唯一的,所以不同的模块对静态变量的操作都是施加在同一个对象上的,解决方案如下:
- 将公共包从基座引用改成每个应用单独引入;
- 将静态变量调整为按 ClassLoader 进行缓存,每次操作只对当前线程的 ClassLoader 对应的对象进行操作。
类找不到异常
一般存在于通过基座加载相应的类或者静态调用的情况下。由于基座类加载器无法访问到模块的类加载器,所以在公共代码中加载类时优先使用 Thread.currentThread().getContextClassLoader()
- XX Class Not Found
- XX Class No Defined
- ServiceLoader 异常
日志适配
- logback 通过 condition 进行适配
<if condition='property("sofa.ark.embed.enable").contains("true")'> <then> <springProperty scope="context" name="APP_NAME" source="spring.application.name" defaultValue="NO_APP_CONFIG"/> <property name="BASE_PATH" value="${user.home}/logs/${APP_NAME}"/> </then>
<else> <springProperty scope="context" name="loggingRoot" source="logging.file.path"/> <property name="BASE_PATH" value="${loggingRoot}/"/> </else>
</if>
- log4j 通过 properties 进行适配
<Property name="loggingRoot">${sys:user.home}/logs/${spring:tuya.sofa.ark.app:-}</Property>
- log4j2 和 logback 日志在同一个基座中混用
一般应用使用 logback,但是存在某些应用使用 log4j2 的情况,目前 Koupleless 不支持两种应用放在一个基座中,可以考虑在 Koupleless 上调整日志系统的判断,或在 Koupleless 上调整由模块决定某些 plugin 是否被加载。
健康检查
提供基座应用的健康检查实现:
- 静态部署模式:合并部署的所有应用的状态都健康,健康检查才会通过。
- 动态部署模式:提供配置,让用户自行决定模块热部署结果是否影响应用整体健康状态(默认配置为:不影响整体应用原本的健康状态)
Web 容器共享
- 多 Host 模式:使用多个 port 进行区分。该模式的问题首先在于重复创建了 Tomcat 相关的资源,造成资源的浪费;其次是每个 Biz 有自己的端口,不利于整个 Ark 包应用整体对外提供服务。
- 单 Host 模式:Koupleless 提供了类似独立 Tomcat 部署多 webapp 的方式。所有 Biz 共用同一个 Server 及 Host,每个 Biz 只创建自己的 Context,通过 Context 中的 contextPath 将自身接口与其它 Biz 接口做区分。

考虑到资源共享及整体性,我们采用了单 Host 模式。
实践心得
- 将下沉的组件配置抽离到父 POM 中,方便统一管控;
- 基座的 AutoConfig 被模块的依赖触发,但是初始化的时候报错,基座需要 exclude 相应的 AutoConfig。建议使用 Spring Boot 框架的自动装配功能时将相应组件下沉到基座;
- ContextPath:可以通过参数动态配置,方便应用运行在单模块独占基座和多模块合并部署场景中;

- 模块需要开启 https 协议时:用于支持自定义证书场景,可以在模块获取到 web server 并主动添加一个新的 Connector。

DevOps 改造
测试应用验证通过后,涂鸦团队开始着手进行发布系统的改造。由于静态合并部署比较适合部署相对稳定不频繁的场景(如私有云),而公有云更适合动态合并部署模式。但为了给私有云交付打前战,涂鸦一期先在公有云上实现静态合并部署,快速试点验证。而静态合并部署是需要所有模块和基座一起发布的,为了尽可能不影响开发同学效率,我们同时支持单模块独占基座和多模块合并部署两种发布模式,方便在开发、日常、预发、线上等环境进行实地试运行,完整验证业务链路。
首先按业务域及流量情况将应用拆分为基座或模块:

然后发布系统根据基座与模块的映射关系,进行打包发布。目前我们是通过 K8S 部署服务的,源代码经过编译打包成 Docker 镜像再进行发布,为复用原有流程,快速上线,模块和基座都打包为镜像。模块由模块负责人进行打包,基座由业务域负责人打包,并根据迭代节奏进行定期发布。

InitContainert 先启动模块镜像,再将模块的 ark 包拷贝到/home/docker/module/biz目录下:

通过-Dcom.alipay.sofa.ark.static.biz.dir 参数实现合并部署:

日志目录
日志路径由原来的 home/docker/logs,在合并模块部署后调整为 home/docker/logs/appname/,日志收集模板按此进行调整。std 输出的日志会打印在基座应用的 std 中,比如异常类的 printStackTrace,所以尽量避免使用 stdout 和 stderr。
域名切换
由于应用合并,原来的域名需要切换到新的域名上来。由单一应用过渡到合并部署模式的发布过程中需要注意对等的流量切换。
有两种域名切换方式:
1、调用方切换到新域名。✅优点:简单,不需要路由。❌缺点:需要调用方配合调整,应用模块与基座关系调整时同样需要再次调整。
2、域名路由。调用方还是访问原域名,通过内部网关路由到新域名。✅优点:灵活。❌缺点:多一次调用。
我们最终采用路由的方式来进行域名切换。
上线实施
目前一期按业务域划分为 18 个基座,60 多个模块在一些数据中心(如中国区、美西区等)进行合并部署后稳定运行。

如某基座合并部署了 8 个模块:

合并后,每个模块由原来的 1C2G 变为 2C4G,节省资源 6C12G。

8 个模块非合并部署前的启动时间如下图 8 条记录显示,在 1-3 分钟之间。

而静态合并部署后的基座启动时间见下图,约 2 分 45 秒。8 个模块分别交付,每个 1-3 分钟,统一成 2 分 45 秒一次性完成交付,大大提高了整体交付效率****。

总体来说,在内存方面,对于应用初始启动内存占总消耗内存比例较高、低流量的业务场景,应用合并部署的内存节省收益越大。60 个模块共节省 70G 内存。线上 POD 数约有 6000 多个,预计可节省 6000 多 G 内存。相应地在 CPU 资源利用率方面,大部分业务应用都是 IO 密集型,而合并部署能将 CPU 较为充足地利用起来,线上 Pod 合并部署后能节省 3000 核。
在调用性能和网络 IO 优化上,大流量的业务场景从远程调用变成本地调用,网络 IO、序列化反序列的 CPU 开销以及调用性能、稳定性上都能得到大幅度提升。
后续演进
当前我们完成的是静态合并部署能力,很好地解决了资源浪费问题。为了进一步提升研发效率,我们正在开发动态合并部署能力,为公有云大规模合并部署打下基础,也为未来更长远的 Serverless 能力提供基座。
为了打造对开发者更友好的 Serverless 能力和平台:
1、我们需要增强模块热卸载能力。
2、进一步的模块瘦身,将更多的通用组件下沉到基座中,减少公共类库和框架加载和初始化运行开销。不但节省内存,还能加速子模块的启动速度,如尝试复用基座数据源和基座拦截器。
3、弹性伸缩,目前依赖应用的 CPU、内存等指标对进程进行弹性伸缩,而合并部署后,可以通过预热基座的方式,让模块的扩缩容速度更快。另外由于模块级别资源的监控指标较难获取,也可以考虑 QPS 等其他维度的指标。
在整个调研、升级改造及实施的过程中,社区同学多次和我们进行线上和线下交流讨论,提供了许多蚂蚁内部和其他外部企业的最佳实践, 给予了我们很多帮助与指导,在共同的努力下最终成功落地 Koupleless!
希望后续社区在模块应用的卸载稳定性上有进一步的优秀表现,为我们的动态发布打下坚实的基础!****也欢迎更多同学加入社区,一起参与共建!
7 - Koupleless 助力「人力家」实现分布式研发集中式部署,又快又省!
作者:赵云兴,葛志刚, 仁励家网络科技(杭州)有限公司架构师,专注 to B 领域架构
背景
人力家由阿里钉钉与人力窝共同孵化,致力于为企业提供以薪酬为核心的一体化 HR SaaS 解决方案,加速对中国人力资源服务行业数字化赋能。
人力资源软件通常由多模块组成,如人力资源规划、招聘、培训、绩效管理、薪酬福利、劳动关系,以及员工和组织管理等。随着业务发展,部分模块进入稳定期,仅需少量维护投入。例如,一个早期有 20 人研发的项目,现在拆分为 5 个应用。尽管产品成熟,但由于客户需求随竞争、业务和政策变化,仍需每年投入部分精力进行迭代。
长时间以来,我们一直面临着以下问题,而苦于没有解决方案:
- 系统资源浪费:5 个应用支撑的业务,我们在生产环境为每个应用部署了 3 台 2C4G 的 Pod,一共是 15 个 Pod 的资源。
- 迭代运维成本高:因为业务的复杂性,经常需要多个应用同时改动,部署等待周期长,单应用部署时间在 6 分钟左右。
在过去,我们已经探索过以下方案:
- 压缩工程:通过排除冗余的 jar 依赖,降低镜像大小。但空间有限,整个应用 jar 包只能从 100+M 减少到 80+M,整个镜像依然有 500M,能节省的部署等待时间有限。
- 单 ECS 上部署多应用:我们需要为这个应用做特别的定制,譬如监听端口要支持多个;部署脚本也要特别定制,要支持滚动发布,健康检测不同的端口,一段时间以后运维容易搞不清整个部署方案,容易出现运维事故。
初见成效
直到在某个月不黑风不高的夜晚,我们在最大的程序员交友网站上遇到了 Koupleless 团队。看完框架的介绍,我们立刻明白,Koupleless 就是我们要寻找的解决方案。
经过近两个月的敲敲打打,模块成功瘦身了,其中最大的模块的 jar 也只有不到 4M。应用部署的体积从 500M 一下子降到了 5M 以下,具体可见下图~

瘦身以后模块的 jar
但高兴不过一天,我们在「如何把 Koupleless 部署到生产环境」上遇到了难题。因为我们没有专门的运维团队,部署都是开发人员通过阿里云的云效流水线,直接把镜像推送到 K8s 的 Pod。但这样改了以后,我们迎来了一连串待解决的问题……
- 模块要不要流量,还是直接通过基座处理流量?
- 如何在单独部署模块的时候先把基座的流量摘掉?
- 发布成功以后如何做健康检查?
- 如何重新开放基座流量?
Koupleless 的生产环境部署
在这里要特别感谢 Koupleless 团队的伙伴,给了我们很多专业的建议和方案。最终,我们选择了以下部署方案:

整体方案是,在基座上增加监听 oss 文件变化自动更新部署模块,卸载老版本模块安装新版模块,所有流量由 nginx 进入,转发到进程 tomcat (基座和多个模块复用同个 tomcat host),并在基座上控制健康检查和流量的开关,主要工作是在基座上扩充一些能力:
1、基座支持配置自身运行的必要条件,譬如需要模块 A、B、C 都安装成功才能放流量进来;
2、检查 oss 目录,自动安装最新的模块版本,并做健康检查;
3、实现 K8s 的 liveness:用来在基座部署的时候判断基座是否成功启动。只要基座启动成功,即返回成功,这样基座可以走后续的安装模块逻辑;
4、实现 K8s 的 readiness:主要控制外部流量是否可以进来。因此这里需要判断所有必须安装的模块是否健康,并且对应的流量文件 A_status 等是否存在(该文件是一个空文件,在滚动发布的时候开关流量的时候用)。
小 Tips:
目前 Koupleless 优化了静态部署和健康检查能力,能够直接满足我们的需求:
- 静态部署:在基座启动成功后,允许用户通过自定义的方式安装模块;
- 健康检查:在基座启动成功且用户自定义安装的模块启动后,Koupleless 框架将原生 SpringBoot 的 readiness 配置为 ‘ACCEPTING_TRAFFIC’,用户可以通过探测 readiness 决定是否让流量进入。
以下是 K8s 上的配置图:
- 就绪检查和启动探测:

- 在 Pod 上增加云存储的挂载:

模块动态部署时需要考虑两个问题:怎么感知新的模块并部署?在模块部署的前后怎么通过健康检查,控制基座流量?
我们的方案大概如下:
- 模块通过流水线,直接 jar 上传到一个 oss 目录;
- 基座上增加配置,配置基座承接流量的必须安装的模块,以及对应模块的健康检查地址;
- 基座监听 oss 文件夹的变化,来决定是否重新部署模块(譬如有更晚的/更大的版本的模块上传到了 oss);
- 基座部署模块前,先摘流量(可以通过删除一个空文件来实现,结合上一步 K8s 的 readiness 逻辑,空文件删除以后,readiness 检测不通过,流量就不会进来。但模块是存活的,防止有耗时的线程还在运行);
- 安装好模块以后,把删除的文件写上,就可以开流量了;
- 集群下,基座通过 redis 来控制 Pod 不会出现并行安装,保证流量不会断;
- 基座提供就绪检查:就绪检查只需要判断基座起来了就可以。
存活检查是比较关键的一步:
a.判断第 4 步的空文件是否存在
b.需要判断所有必须安装的模块都可以访问
小 Tips:
目前 Koupleless 优化了健康检查能力,能够在模块动态安装/卸载之前关闭流量,将 readiness 配置为 REFUSING_TRAFFIC,并允许用户配置模块卸载前的静默时长,让流量在静默时期处于关闭状态。在卸载的静默时长结束、旧模块卸载完成、全部模块安装成功后,readiness 才会配置为 ACCEPTING_TRAFFIC 状态。
总结
在以前,单个模块升级发布一次要 6 分多钟。

而改造后,升级单个模块只需要把编译后的 jar 上传到 oss 即可。

最终的效果,通过一组简单的数字对比就可以看出差异:
- 在服务器资源上,以前需要 15X2C4G,现在只需要 3X4c8G,节省了 18C36G 的服务器资源;
- 在单个模块的发布时间上,我们从之前的 6 分钟降低到了 3 分钟;
- 在单个模块的部署资源上,我们从 500M 降低到了 5****M。
再次感谢 Koupleless 团队伙伴的专业支持,特别是有济、立蓬。当我们在改造过程中遇到一些个性场景的兼容性问题,他们都能快速响应,让我们整个升级改造时间大大缩短。
通过升级 Koupleless 架构,人力家实现了多应用的合并部署、并行研发、轻量集中部署,大大降低了运维成本。
天下架构,分久必合,合久必分。而 Koupleless,让架构演进(分合)更丝滑🥰
8 - Koupleless 所有企业案例
目前主动登记使用 Koupleless 的企业,按企业拼音字母顺序排序,不分先后:
阿里国际数字商业集团

使用场景:通用基座实现普通应用秒级构建发布、SDK 无感升级。详细案例
阿里健康科技(中国)有限公司

使用场景:应用插件化开发
阿里妈妈

使用场景:合并部署、热部署
北京快手科技有限公司

使用场景:合并部署、热部署
杭州涂鸦科技有限公司

使用场景:合并部署、热部署
浙江政采云 - 中国招标与采购网

使用场景:合并部署、热部署
郑州易盛信息科技有限公司

使用场景:合并部署、热部署
广东正元信息技术有限公司

使用场景:热部署
斑马信息科技有限公司

使用场景:类隔离、合并部署
成都云智天下科技股份有限公司
使用场景:模块动态部署、卸载
蚂蚁集团

使用场景:应用秒级构建发布、秒级弹性、并行迭代、合并部署,实现资源降本和研发提效。详细案例
南京爱福路汽车科技有限公司

使用场景:多应用合并部署降本增效
深圳市诺安赛威科技有限公司

https://company.rfidworld.com.cn/Intro-137503.aspx
使用场景:动态热部署、热卸载、模块隔离
山东网聪信息科技有限公司
使用场景:类隔离
宋城独木桥网络有限公司

使用场景:动态热部署、热卸载、模块隔离
网商银行

使用场景:应用秒级构建发布、秒级弹性、并行迭代、合并部署
易宝支付有限公司

使用场景:项目插件化,如动态部署、卸载、模块隔离
江苏纵目信息科技有限公司

使用场景:多应用合并部署降本增效
华信永道(北京)科技股份有限公司
使用场景:多应用合并部署降本增效

https://www.yondervision.com.cn/